 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
SciVisAgentBench: A Benchmark for Evaluating Scientific Data Analysis and Visualization Agents
Mar 31, 2026Recent advances in large language models (LLMs) have enabled agentic systems that translate natural language intent into executable scientific visualization (SciVis) tasks. Despite rapid progress, the community lacks a principled and reproducible benchmark for evaluating these emerging SciVis agents in realistic, multi-step analysis settings. We present SciVisAgentBench, a comprehensive and extensible benchmark for evaluating scientific data analysis and visualization agents. Our benchmark is grounded in a structured taxonomy spanning four dimensions: application domain, data type, complexity level, and visualization operation. It currently comprises 108 expert-crafted cases covering diverse SciVis scenarios. To enable reliable assessment, we introduce a multimodal outcome-centric evaluation pipeline that combines LLM-based judging with deterministic evaluators, including image-based metrics, code checkers, rule-based verifiers, and case-specific evaluators. We also conduct a validity study with 12 SciVis experts to examine the agreement between human and LLM judges. Using this framework, we evaluate representative SciVis agents and general-purpose coding agents to establish initial baselines and reveal capability gaps. SciVisAgentBench is designed as a living benchmark to support systematic comparison, diagnose failure modes, and drive progress in agentic SciVis. The benchmark is available at https://scivisagentbench.github.io/.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025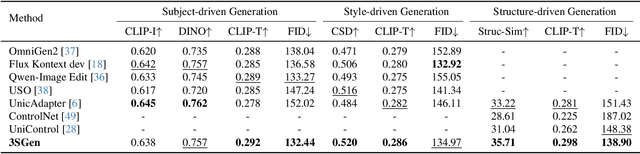
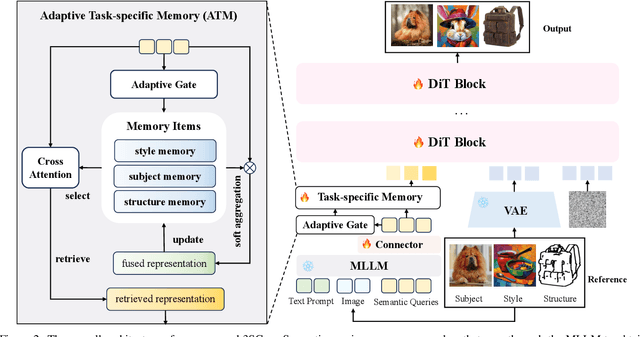
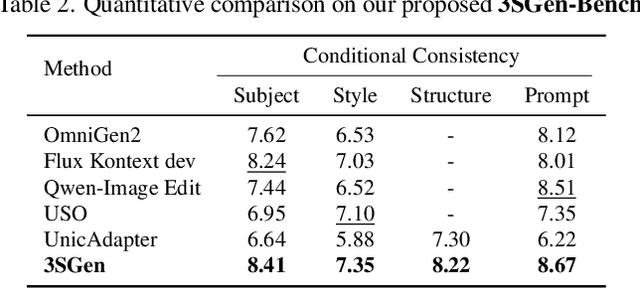
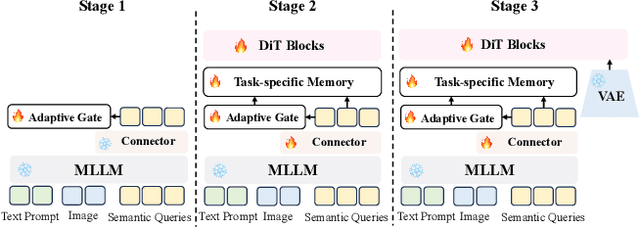
Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025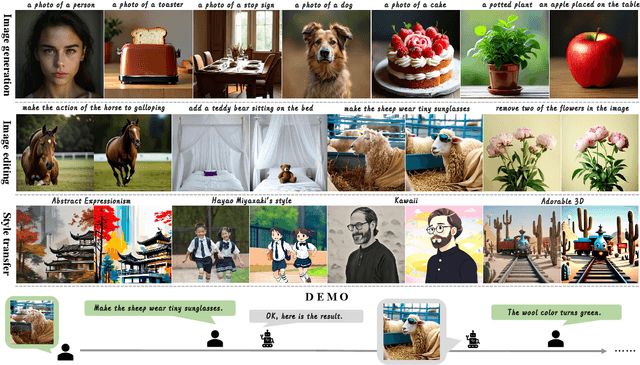

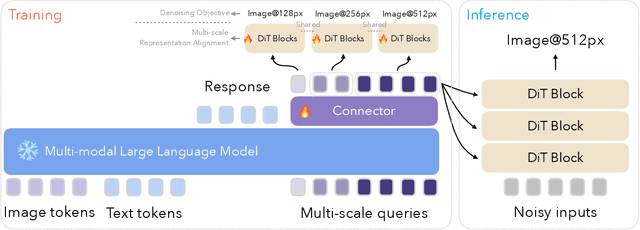
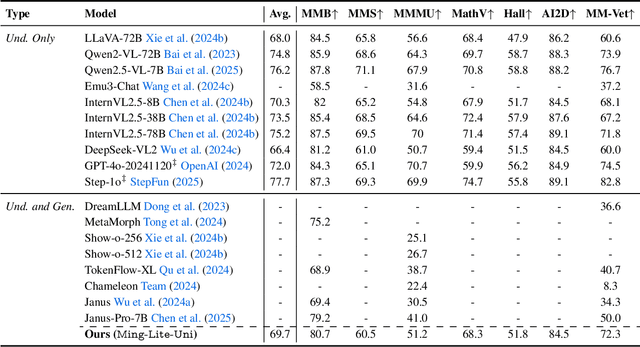
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
Can Language Models Enable In-Context Database?
Nov 04, 2024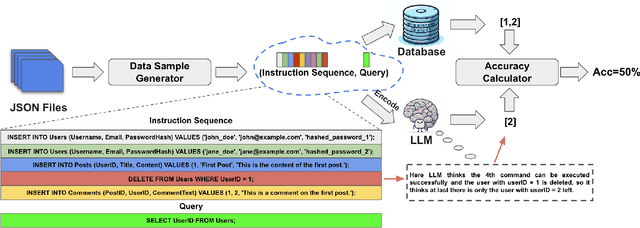
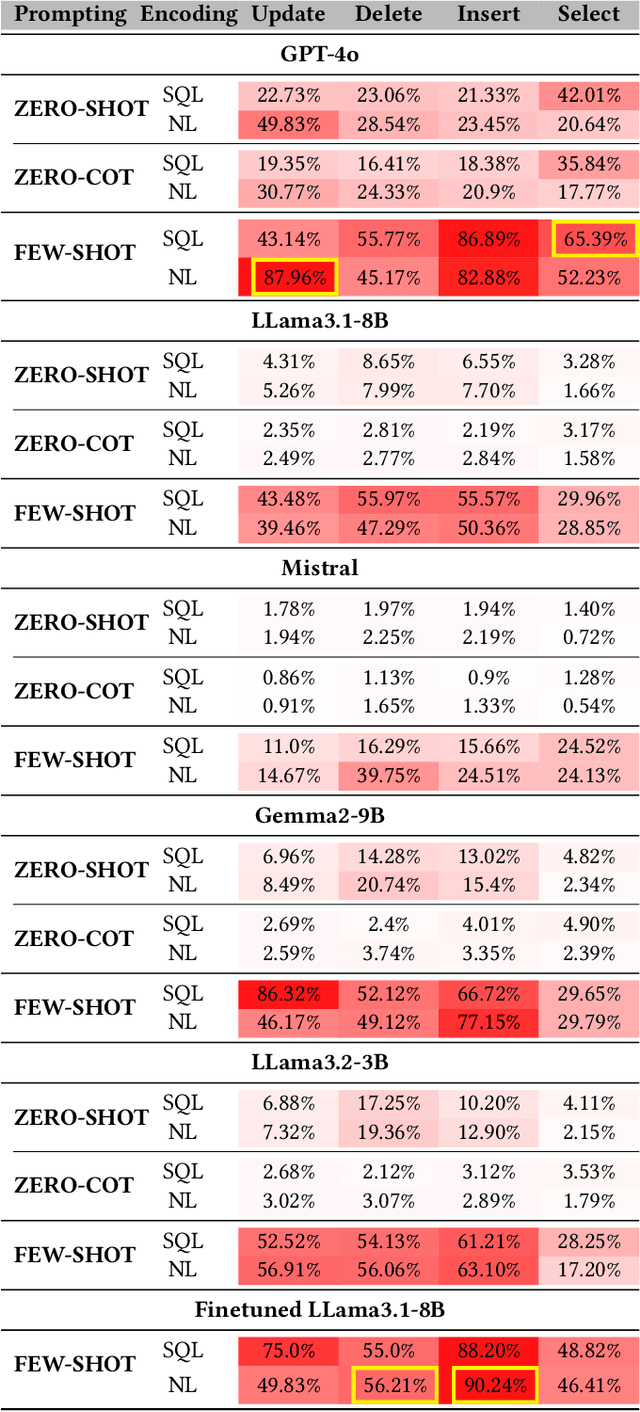

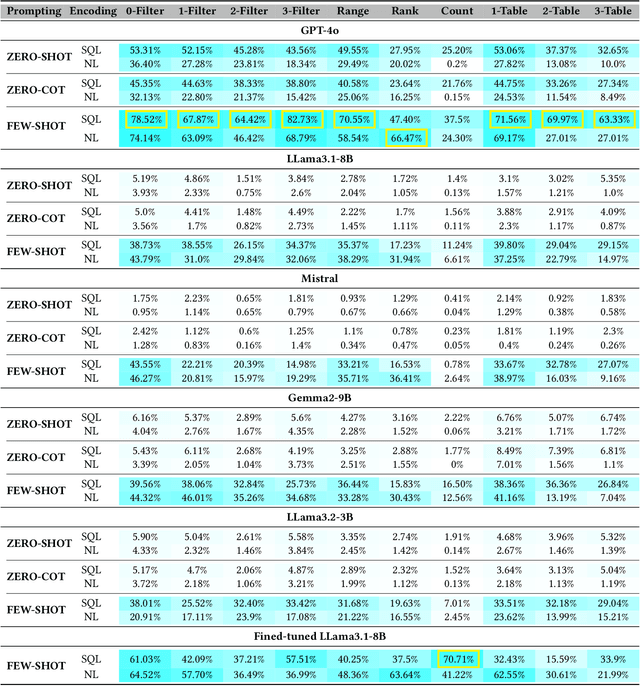
Large language models (LLMs) are emerging as few-shot learners capable of handling a variety of tasks, including comprehension, planning, reasoning, question answering, arithmetic calculations, and more. At the core of these capabilities is LLMs' proficiency in representing and understanding structural or semi-structural data, such as tables and graphs. Numerous studies have demonstrated that reasoning on tabular data or graphs is not only feasible for LLMs but also gives a promising research direction which treats these data as in-context data. The lightweight and human readable characteristics of in-context database can potentially make it an alternative for the traditional database in typical RAG (Retrieval Augmented Generation) settings. However, almost all current work focuses on static in-context data, which does not allow dynamic update. In this paper, to enable dynamic database update, delta encoding of database is proposed. We explore how data stored in traditional RDBMS can be encoded as in-context text and evaluate LLMs' proficiency for CRUD (Create, Read, Update and Delete) operations on in-context databases. A benchmark named InConDB is presented and extensive experiments are conducted to show the performance of different language models in enabling in-context database by varying the database encoding method, prompting method, operation type and input data distribution, revealing both the proficiency and limitations.
Building Multi-Agent Copilot towards Autonomous Agricultural Data Management and Analysis
Oct 31, 2024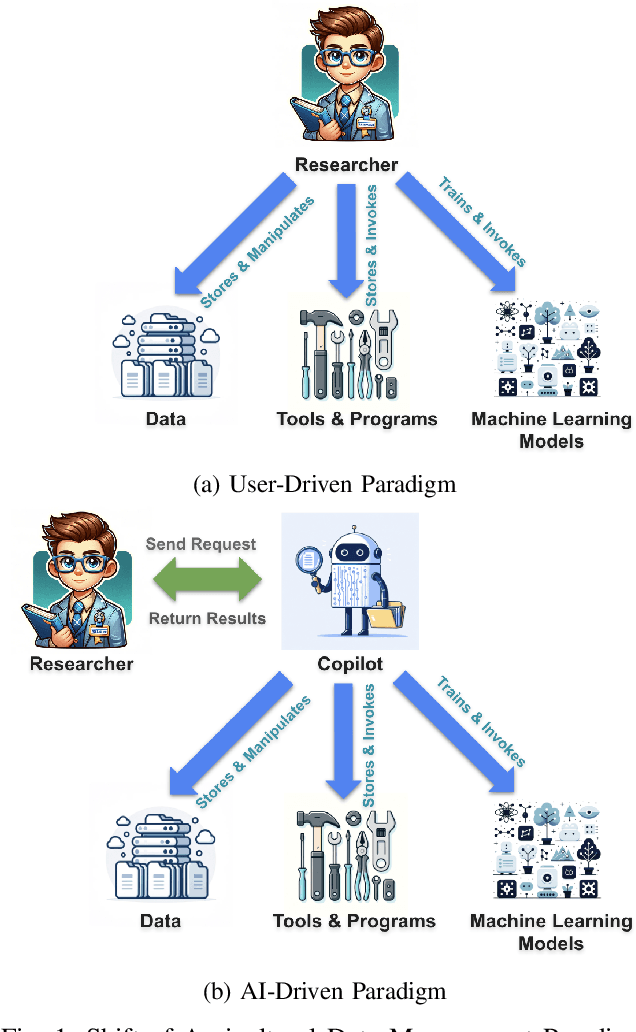
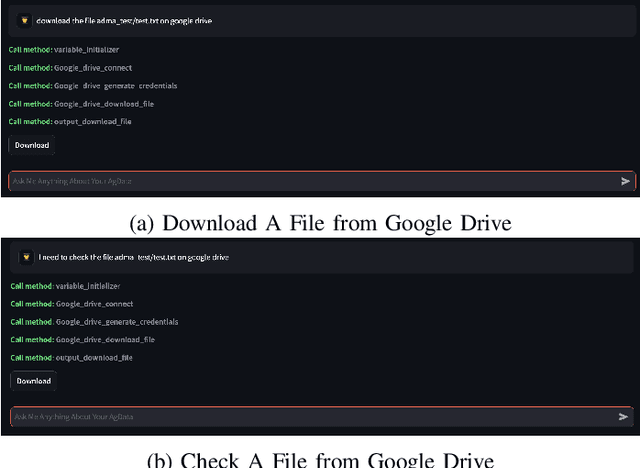
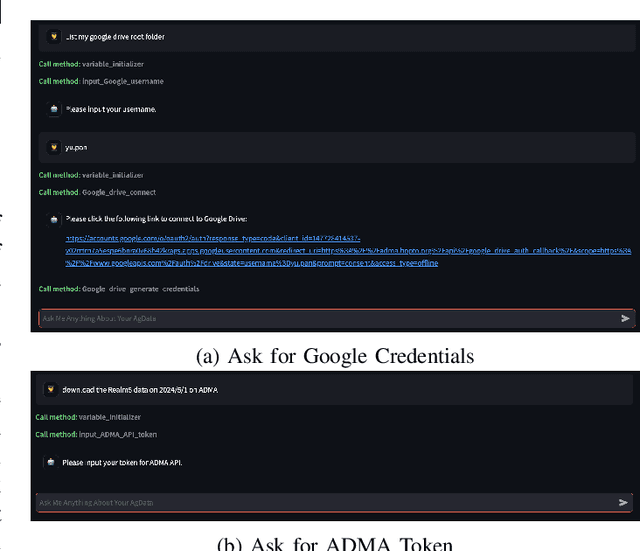

Current agricultural data management and analysis paradigms are to large extent traditional, in which data collecting, curating, integration, loading, storing, sharing and analyzing still involve too much human effort and know-how. The experts, researchers and the farm operators need to understand the data and the whole process of data management pipeline to make fully use of the data. The essential problem of the traditional paradigm is the lack of a layer of orchestrational intelligence which can understand, organize and coordinate the data processing utilities to maximize data management and analysis outcome. The emerging reasoning and tool mastering abilities of large language models (LLM) make it a potentially good fit to this position, which helps a shift from the traditional user-driven paradigm to AI-driven paradigm. In this paper, we propose and explore the idea of a LLM based copilot for autonomous agricultural data management and analysis. Based on our previously developed platform of Agricultural Data Management and Analytics (ADMA), we build a proof-of-concept multi-agent system called ADMA Copilot, which can understand user's intent, makes plans for data processing pipeline and accomplishes tasks automatically, in which three agents: a LLM based controller, an input formatter and an output formatter collaborate together. Different from existing LLM based solutions, by defining a meta-program graph, our work decouples control flow and data flow to enhance the predictability of the behaviour of the agents. Experiments demonstrates the intelligence, autonomy, efficacy, efficiency, extensibility, flexibility and privacy of our system. Comparison is also made between ours and existing systems to show the superiority and potential of our system.
Free-style and Fast 3D Portrait Synthesis
Jun 28, 2023Efficiently generating a free-style 3D portrait with high quality and consistency is a promising yet challenging task. The portrait styles generated by most existing methods are usually restricted by their 3D generators, which are learned in specific facial datasets, such as FFHQ. To get a free-style 3D portrait, one can build a large-scale multi-style database to retrain the 3D generator, or use a off-the-shelf tool to do the style translation. However, the former is time-consuming due to data collection and training process, the latter may destroy the multi-view consistency. To tackle this problem, we propose a fast 3D portrait synthesis framework in this paper, which enable one to use text prompts to specify styles. Specifically, for a given portrait style, we first leverage two generative priors, a 3D-aware GAN generator (EG3D) and a text-guided image editor (Ip2p), to quickly construct a few-shot training set, where the inference process of Ip2p is optimized to make editing more stable. Then we replace original triplane generator of EG3D with a Image-to-Triplane (I2T) module for two purposes: 1) getting rid of the style constraints of pre-trained EG3D by fine-tuning I2T on the few-shot dataset; 2) improving training efficiency by fixing all parts of EG3D except I2T. Furthermore, we construct a multi-style and multi-identity 3D portrait database to demonstrate the scalability and generalization of our method. Experimental results show that our method is capable of synthesizing high-quality 3D portraits with specified styles in a few minutes, outperforming the state-of-the-art.
Unlearnable Examples Give a False Sense of Security: Piercing through Unexploitable Data with Learnable Examples
May 23, 2023



Safeguarding data from unauthorized exploitation is vital for privacy and security, especially in recent rampant research in security breach such as adversarial/membership attacks. To this end, \textit{unlearnable examples} (UEs) have been recently proposed as a compelling protection, by adding imperceptible perturbation to data so that models trained on them cannot classify them accurately on original clean distribution. Unfortunately, we find UEs provide a false sense of security, because they cannot stop unauthorized users from utilizing other unprotected data to remove the protection, by turning unlearnable data into learnable again. Motivated by this observation, we formally define a new threat by introducing \textit{learnable unauthorized examples} (LEs) which are UEs with their protection removed. The core of this approach is a novel purification process that projects UEs onto the manifold of LEs. This is realized by a new joint-conditional diffusion model which denoises UEs conditioned on the pixel and perceptual similarity between UEs and LEs. Extensive experiments demonstrate that LE delivers state-of-the-art countering performance against both supervised UEs and unsupervised UEs in various scenarios, which is the first generalizable countermeasure to UEs across supervised learning and unsupervised learning.
HumanDiffusion: a Coarse-to-Fine Alignment Diffusion Framework for Controllable Text-Driven Person Image Generation
Nov 11, 2022
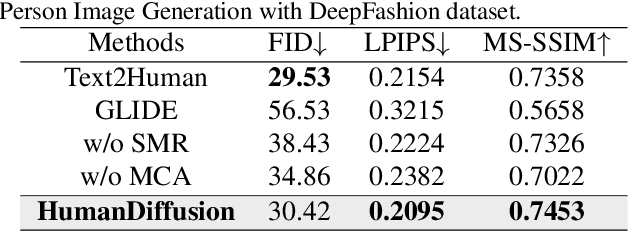
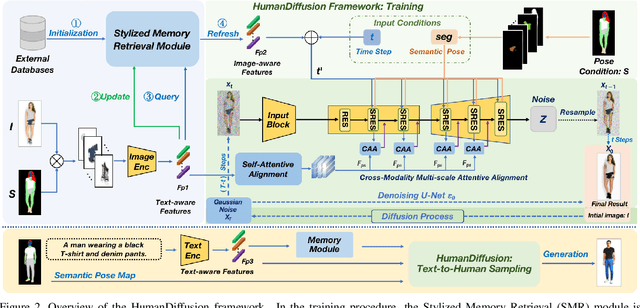

Text-driven person image generation is an emerging and challenging task in cross-modality image generation. Controllable person image generation promotes a wide range of applications such as digital human interaction and virtual try-on. However, previous methods mostly employ single-modality information as the prior condition (e.g. pose-guided person image generation), or utilize the preset words for text-driven human synthesis. Introducing a sentence composed of free words with an editable semantic pose map to describe person appearance is a more user-friendly way. In this paper, we propose HumanDiffusion, a coarse-to-fine alignment diffusion framework, for text-driven person image generation. Specifically, two collaborative modules are proposed, the Stylized Memory Retrieval (SMR) module for fine-grained feature distillation in data processing and the Multi-scale Cross-modality Alignment (MCA) module for coarse-to-fine feature alignment in diffusion. These two modules guarantee the alignment quality of the text and image, from image-level to feature-level, from low-resolution to high-resolution. As a result, HumanDiffusion realizes open-vocabulary person image generation with desired semantic poses. Extensive experiments conducted on DeepFashion demonstrate the superiority of our method compared with previous approaches. Moreover, better results could be obtained for complicated person images with various details and uncommon poses.