 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciVisAgentBench: A Benchmark for Evaluating Scientific Data Analysis and Visualization Agents
Mar 31, 2026Recent advances in large language models (LLMs) have enabled agentic systems that translate natural language intent into executable scientific visualization (SciVis) tasks. Despite rapid progress, the community lacks a principled and reproducible benchmark for evaluating these emerging SciVis agents in realistic, multi-step analysis settings. We present SciVisAgentBench, a comprehensive and extensible benchmark for evaluating scientific data analysis and visualization agents. Our benchmark is grounded in a structured taxonomy spanning four dimensions: application domain, data type, complexity level, and visualization operation. It currently comprises 108 expert-crafted cases covering diverse SciVis scenarios. To enable reliable assessment, we introduce a multimodal outcome-centric evaluation pipeline that combines LLM-based judging with deterministic evaluators, including image-based metrics, code checkers, rule-based verifiers, and case-specific evaluators. We also conduct a validity study with 12 SciVis experts to examine the agreement between human and LLM judges. Using this framework, we evaluate representative SciVis agents and general-purpose coding agents to establish initial baselines and reveal capability gaps. SciVisAgentBench is designed as a living benchmark to support systematic comparison, diagnose failure modes, and drive progress in agentic SciVis. The benchmark is available at https://scivisagentbench.github.io/.
Can Language Models Enable In-Context Database?
Nov 04, 2024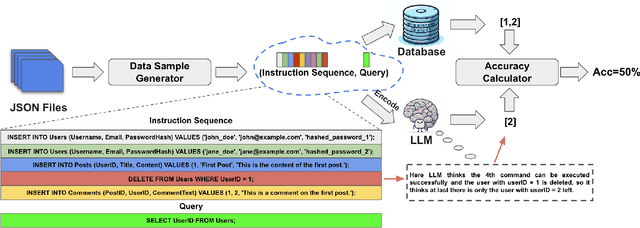
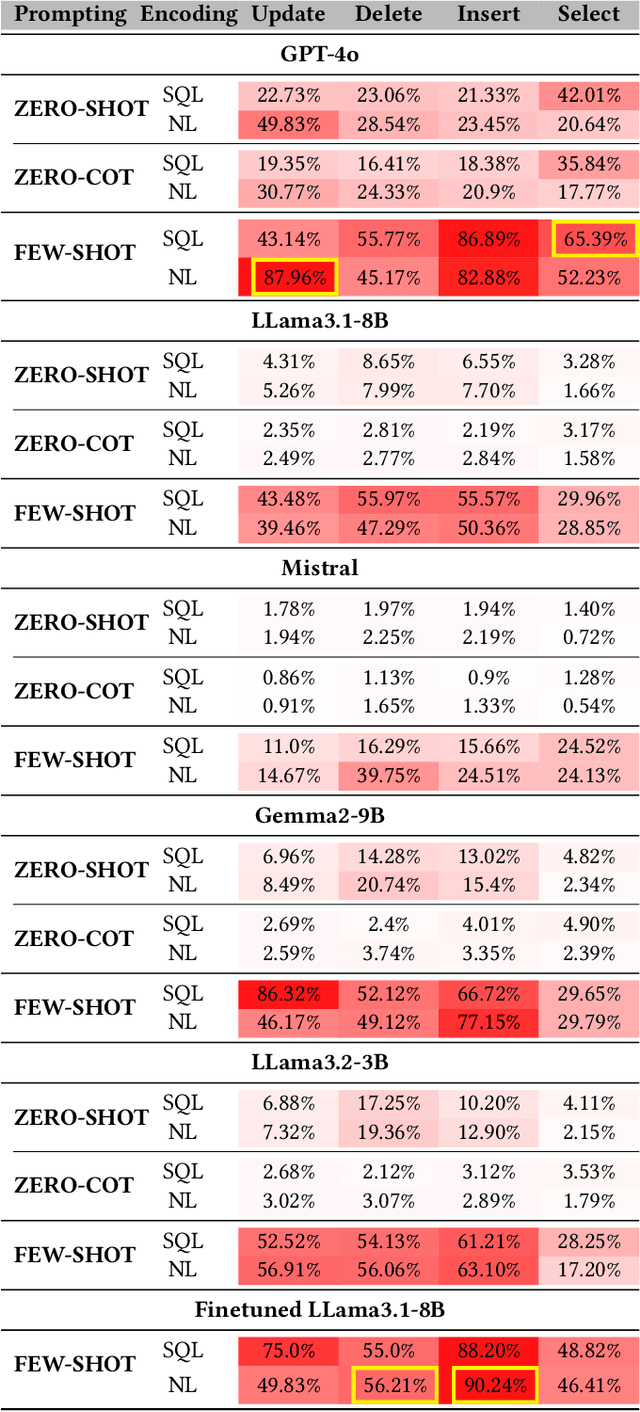

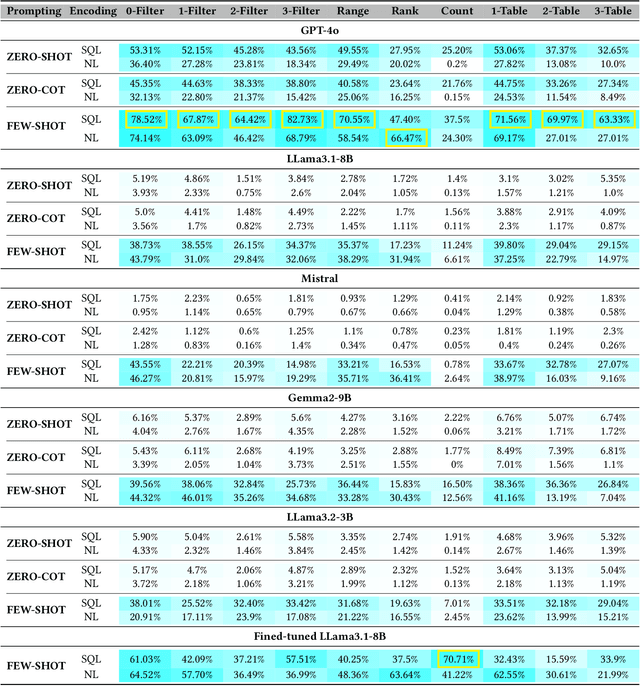
Large language models (LLMs) are emerging as few-shot learners capable of handling a variety of tasks, including comprehension, planning, reasoning, question answering, arithmetic calculations, and more. At the core of these capabilities is LLMs' proficiency in representing and understanding structural or semi-structural data, such as tables and graphs. Numerous studies have demonstrated that reasoning on tabular data or graphs is not only feasible for LLMs but also gives a promising research direction which treats these data as in-context data. The lightweight and human readable characteristics of in-context database can potentially make it an alternative for the traditional database in typical RAG (Retrieval Augmented Generation) settings. However, almost all current work focuses on static in-context data, which does not allow dynamic update. In this paper, to enable dynamic database update, delta encoding of database is proposed. We explore how data stored in traditional RDBMS can be encoded as in-context text and evaluate LLMs' proficiency for CRUD (Create, Read, Update and Delete) operations on in-context databases. A benchmark named InConDB is presented and extensive experiments are conducted to show the performance of different language models in enabling in-context database by varying the database encoding method, prompting method, operation type and input data distribution, revealing both the proficiency and limitations.
Building Multi-Agent Copilot towards Autonomous Agricultural Data Management and Analysis
Oct 31, 2024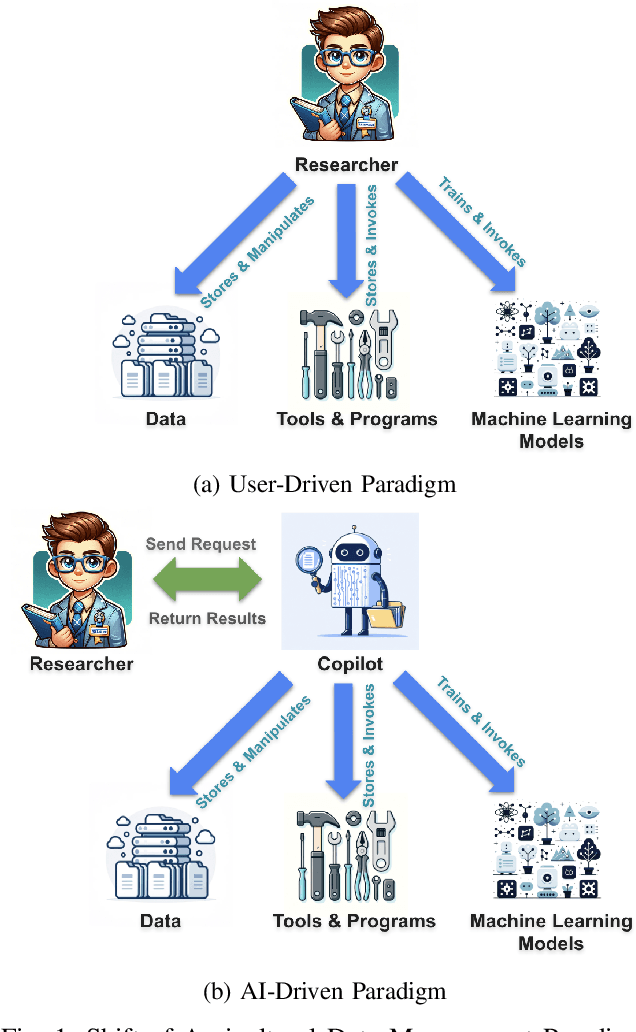
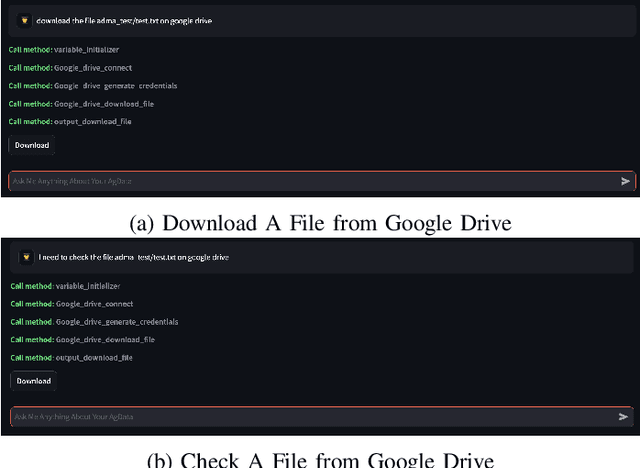
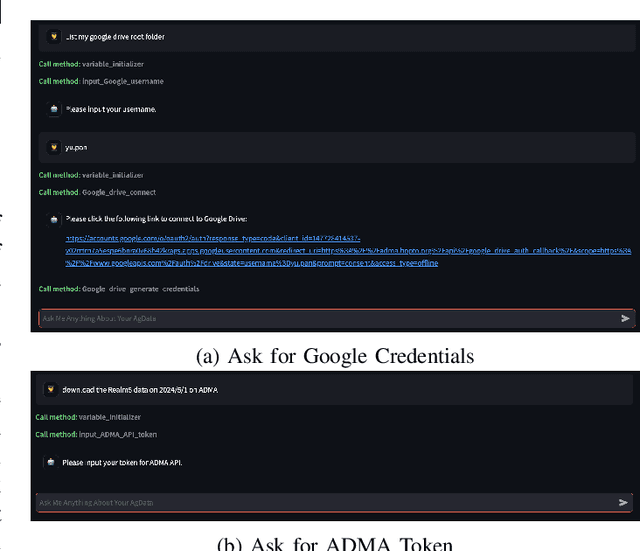

Current agricultural data management and analysis paradigms are to large extent traditional, in which data collecting, curating, integration, loading, storing, sharing and analyzing still involve too much human effort and know-how. The experts, researchers and the farm operators need to understand the data and the whole process of data management pipeline to make fully use of the data. The essential problem of the traditional paradigm is the lack of a layer of orchestrational intelligence which can understand, organize and coordinate the data processing utilities to maximize data management and analysis outcome. The emerging reasoning and tool mastering abilities of large language models (LLM) make it a potentially good fit to this position, which helps a shift from the traditional user-driven paradigm to AI-driven paradigm. In this paper, we propose and explore the idea of a LLM based copilot for autonomous agricultural data management and analysis. Based on our previously developed platform of Agricultural Data Management and Analytics (ADMA), we build a proof-of-concept multi-agent system called ADMA Copilot, which can understand user's intent, makes plans for data processing pipeline and accomplishes tasks automatically, in which three agents: a LLM based controller, an input formatter and an output formatter collaborate together. Different from existing LLM based solutions, by defining a meta-program graph, our work decouples control flow and data flow to enhance the predictability of the behaviour of the agents. Experiments demonstrates the intelligence, autonomy, efficacy, efficiency, extensibility, flexibility and privacy of our system. Comparison is also made between ours and existing systems to show the superiority and potential of our system.
ReCon1M:A Large-scale Benchmark Dataset for Relation Comprehension in Remote Sensing Imagery
Jun 10, 2024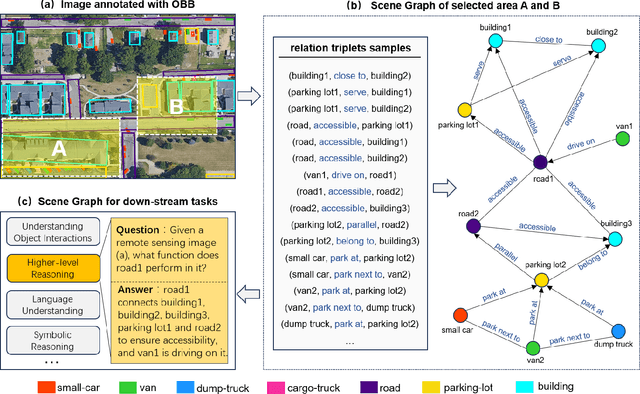
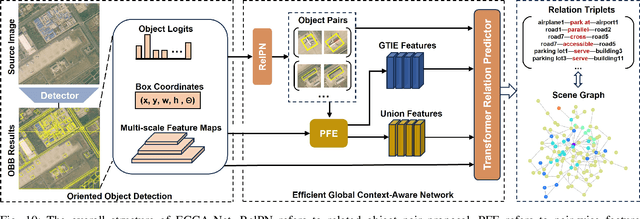
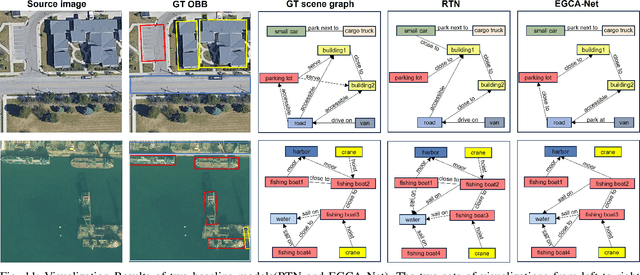
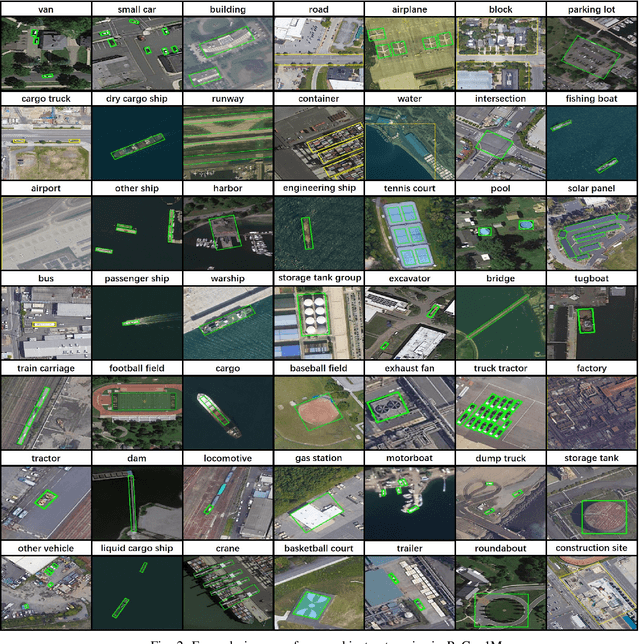
Scene Graph Generation (SGG) is a high-level visual understanding and reasoning task aimed at extracting entities (such as objects) and their interrelationships from images. Significant progress has been made in the study of SGG in natural images in recent years, but its exploration in the domain of remote sensing images remains very limited. The complex characteristics of remote sensing images necessitate higher time and manual interpretation costs for annotation compared to natural images. The lack of a large-scale public SGG benchmark is a major impediment to the advancement of SGG-related research in aerial imagery. In this paper, we introduce the first publicly available large-scale, million-level relation dataset in the field of remote sensing images which is named as ReCon1M. Specifically, our dataset is built upon Fair1M and comprises 21,392 images. It includes annotations for 859,751 object bounding boxes across 60 different categories, and 1,149,342 relation triplets across 64 categories based on these bounding boxes. We provide a detailed description of the dataset's characteristics and statistical information. We conducted two object detection tasks and three sub-tasks within SGG on this dataset, assessing the performance of mainstream methods on these tasks.
TAFormer: A Unified Target-Aware Transformer for Video and Motion Joint Prediction in Aerial Scenes
Mar 27, 2024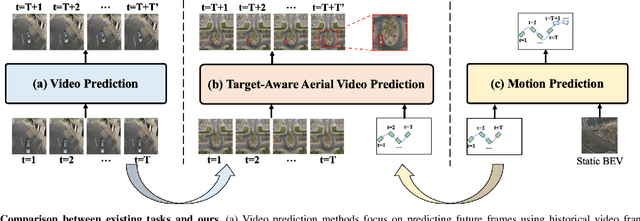
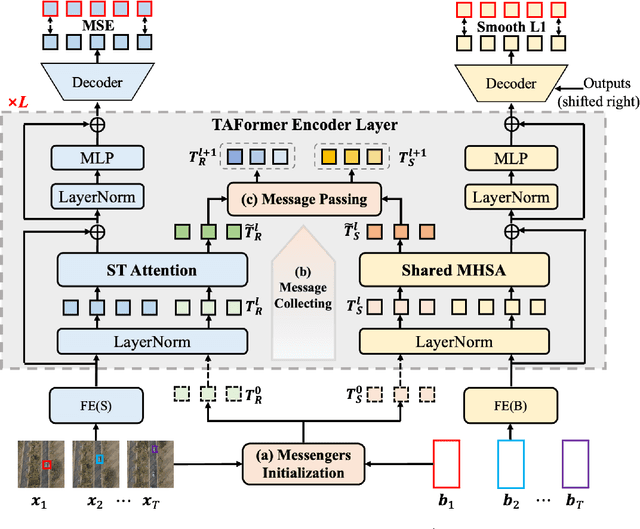
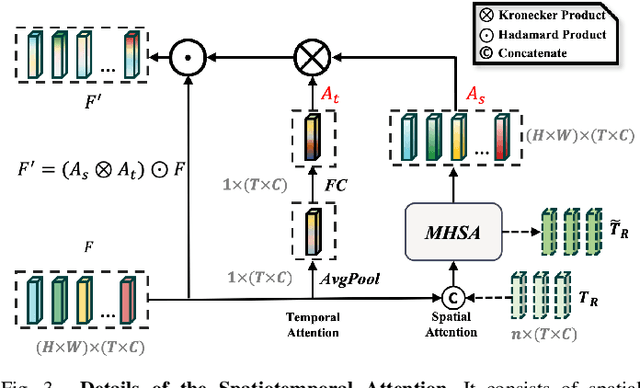
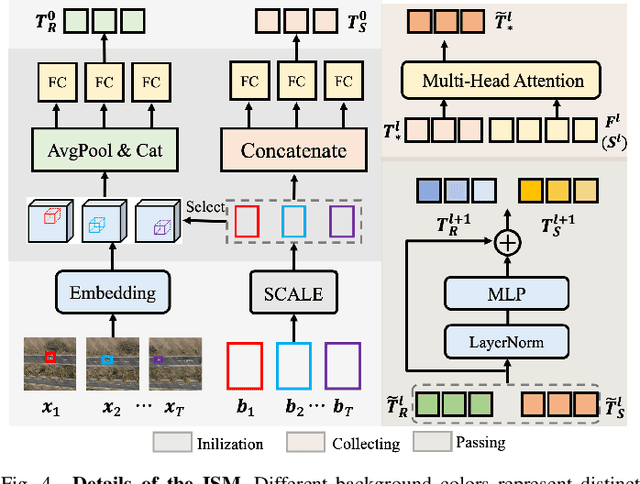
As drone technology advances, using unmanned aerial vehicles for aerial surveys has become the dominant trend in modern low-altitude remote sensing. The surge in aerial video data necessitates accurate prediction for future scenarios and motion states of the interested target, particularly in applications like traffic management and disaster response. Existing video prediction methods focus solely on predicting future scenes (video frames), suffering from the neglect of explicitly modeling target's motion states, which is crucial for aerial video interpretation. To address this issue, we introduce a novel task called Target-Aware Aerial Video Prediction, aiming to simultaneously predict future scenes and motion states of the target. Further, we design a model specifically for this task, named TAFormer, which provides a unified modeling approach for both video and target motion states. Specifically, we introduce Spatiotemporal Attention (STA), which decouples the learning of video dynamics into spatial static attention and temporal dynamic attention, effectively modeling the scene appearance and motion. Additionally, we design an Information Sharing Mechanism (ISM), which elegantly unifies the modeling of video and target motion by facilitating information interaction through two sets of messenger tokens. Moreover, to alleviate the difficulty of distinguishing targets in blurry predictions, we introduce Target-Sensitive Gaussian Loss (TSGL), enhancing the model's sensitivity to both target's position and content. Extensive experiments on UAV123VP and VisDroneVP (derived from single-object tracking datasets) demonstrate the exceptional performance of TAFormer in target-aware video prediction, showcasing its adaptability to the additional requirements of aerial video interpretation for target awareness.
SFTformer: A Spatial-Frequency-Temporal Correlation-Decoupling Transformer for Radar Echo Extrapolation
Feb 28, 2024
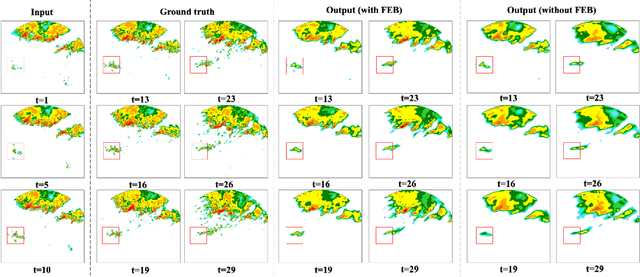
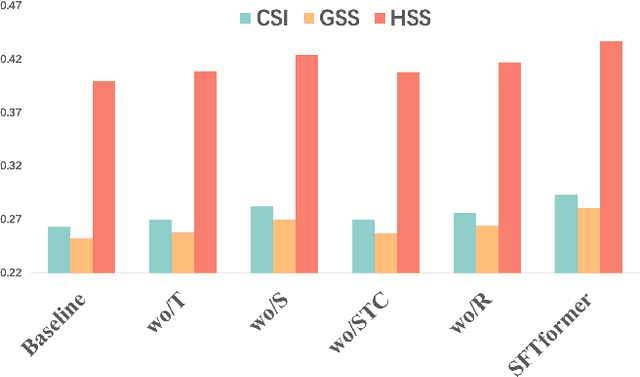
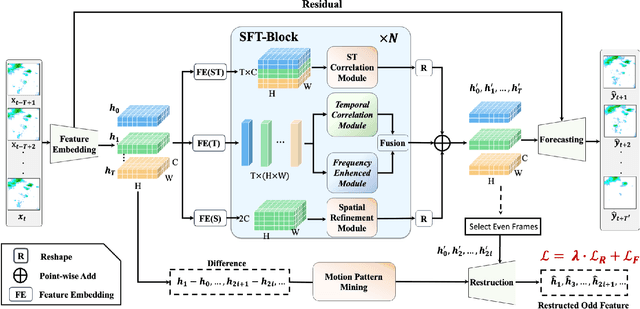
Extrapolating future weather radar echoes from past observations is a complex task vital for precipitation nowcasting. The spatial morphology and temporal evolution of radar echoes exhibit a certain degree of correlation, yet they also possess independent characteristics. {Existing methods learn unified spatial and temporal representations in a highly coupled feature space, emphasizing the correlation between spatial and temporal features but neglecting the explicit modeling of their independent characteristics, which may result in mutual interference between them.} To effectively model the spatiotemporal dynamics of radar echoes, we propose a Spatial-Frequency-Temporal correlation-decoupling Transformer (SFTformer). The model leverages stacked multiple SFT-Blocks to not only mine the correlation of the spatiotemporal dynamics of echo cells but also avoid the mutual interference between the temporal modeling and the spatial morphology refinement by decoupling them. Furthermore, inspired by the practice that weather forecast experts effectively review historical echo evolution to make accurate predictions, SFTfomer incorporates a joint training paradigm for historical echo sequence reconstruction and future echo sequence prediction. Experimental results on the HKO-7 dataset and ChinaNorth-2021 dataset demonstrate the superior performance of SFTfomer in short(1h), mid(2h), and long-term(3h) precipitation nowcasting.
3DGAUnet: 3D generative adversarial networks with a 3D U-Net based generator to achieve the accurate and effective synthesis of clinical tumor image data for pancreatic cancer
Nov 27, 2023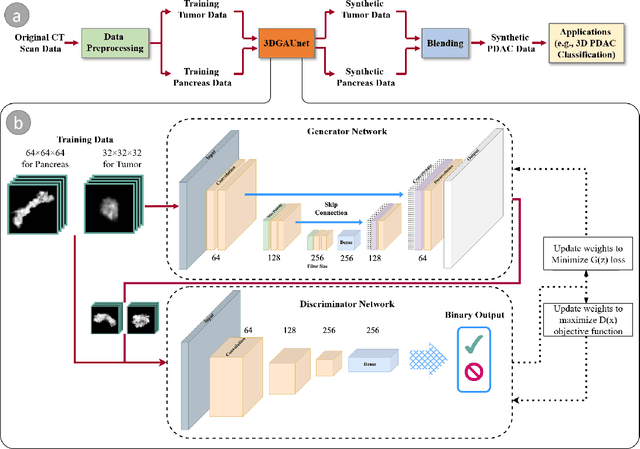



Pancreatic ductal adenocarcinoma (PDAC) presents a critical global health challenge, and early detection is crucial for improving the 5-year survival rate. Recent medical imaging and computational algorithm advances offer potential solutions for early diagnosis. Deep learning, particularly in the form of convolutional neural networks (CNNs), has demonstrated success in medical image analysis tasks, including classification and segmentation. However, the limited availability of clinical data for training purposes continues to provide a significant obstacle. Data augmentation, generative adversarial networks (GANs), and cross-validation are potential techniques to address this limitation and improve model performance, but effective solutions are still rare for 3D PDAC, where contrast is especially poor owing to the high heterogeneity in both tumor and background tissues. In this study, we developed a new GAN-based model, named 3DGAUnet, for generating realistic 3D CT images of PDAC tumors and pancreatic tissue, which can generate the interslice connection data that the existing 2D CT image synthesis models lack. Our innovation is to develop a 3D U-Net architecture for the generator to improve shape and texture learning for PDAC tumors and pancreatic tissue. Our approach offers a promising path to tackle the urgent requirement for creative and synergistic methods to combat PDAC. The development of this GAN-based model has the potential to alleviate data scarcity issues, elevate the quality of synthesized data, and thereby facilitate the progression of deep learning models to enhance the accuracy and early detection of PDAC tumors, which could profoundly impact patient outcomes. Furthermore, this model has the potential to be adapted to other types of solid tumors, hence making significant contributions to the field of medical imaging in terms of image processing models.
Assessing Deep Neural Networks as Probability Estimators
Nov 16, 2021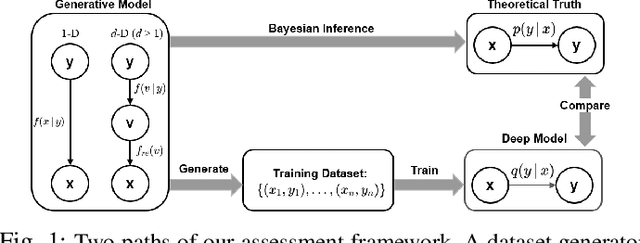
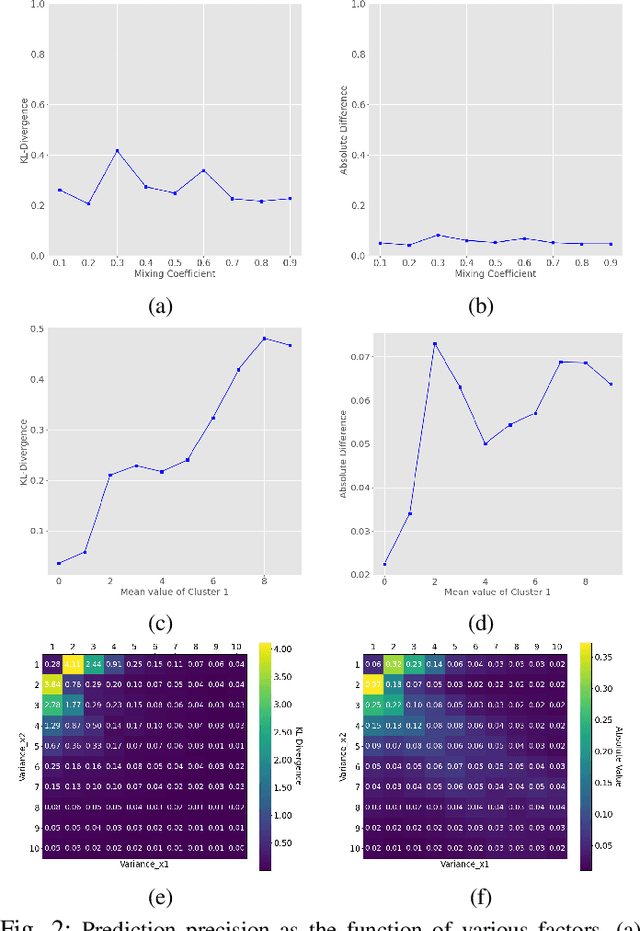
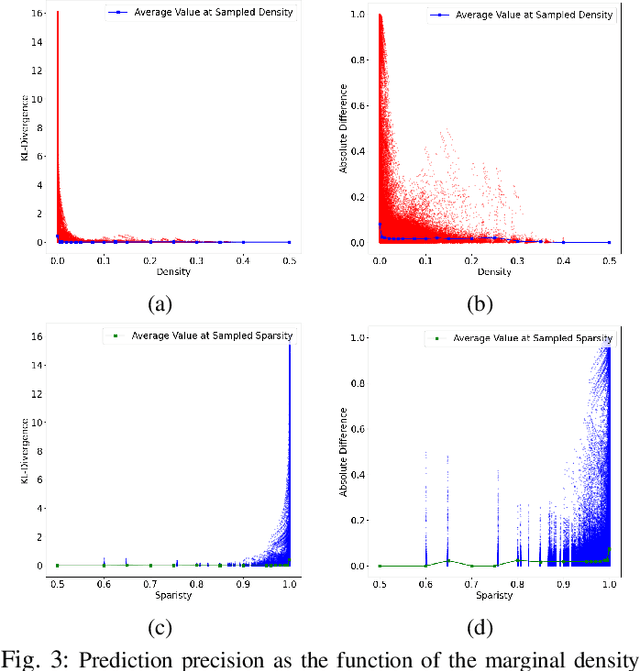
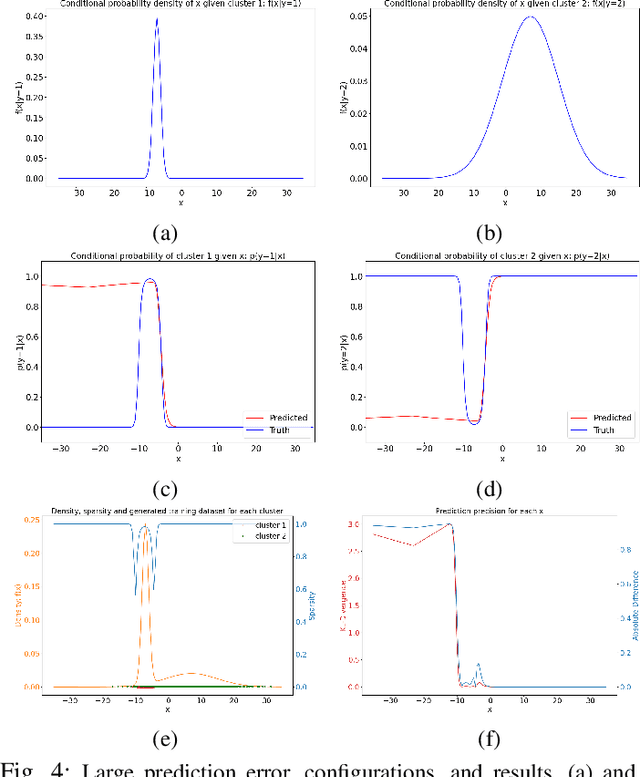
Deep Neural Networks (DNNs) have performed admirably in classification tasks. However, the characterization of their classification uncertainties, required for certain applications, has been lacking. In this work, we investigate the issue by assessing DNNs' ability to estimate conditional probabilities and propose a framework for systematic uncertainty characterization. Denoting the input sample as x and the category as y, the classification task of assigning a category y to a given input x can be reduced to the task of estimating the conditional probabilities p(y|x), as approximated by the DNN at its last layer using the softmax function. Since softmax yields a vector whose elements all fall in the interval (0, 1) and sum to 1, it suggests a probabilistic interpretation to the DNN's outcome. Using synthetic and real-world datasets, we look into the impact of various factors, e.g., probability density f(x) and inter-categorical sparsity, on the precision of DNNs' estimations of p(y|x), and find that the likelihood probability density and the inter-categorical sparsity have greater impacts than the prior probability to DNNs' classification uncertainty.