 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavAgent: Multi-scale Urban Street View Fusion For UAV Embodied Vision-and-Language Navigation
Nov 13, 2024Vision-and-Language Navigation (VLN), as a widely discussed research direction in embodied intelligence, aims to enable embodied agents to navigate in complicated visual environments through natural language commands. Most existing VLN methods focus on indoor ground robot scenarios. However, when applied to UAV VLN in outdoor urban scenes, it faces two significant challenges. First, urban scenes contain numerous objects, which makes it challenging to match fine-grained landmarks in images with complex textual descriptions of these landmarks. Second, overall environmental information encompasses multiple modal dimensions, and the diversity of representations significantly increases the complexity of the encoding process. To address these challenges, we propose NavAgent, the first urban UAV embodied navigation model driven by a large Vision-Language Model. NavAgent undertakes navigation tasks by synthesizing multi-scale environmental information, including topological maps (global), panoramas (medium), and fine-grained landmarks (local). Specifically, we utilize GLIP to build a visual recognizer for landmark capable of identifying and linguisticizing fine-grained landmarks. Subsequently, we develop dynamically growing scene topology map that integrate environmental information and employ Graph Convolutional Networks to encode global environmental data. In addition, to train the visual recognizer for landmark, we develop NavAgent-Landmark2K, the first fine-grained landmark dataset for real urban street scenes. In experiments conducted on the Touchdown and Map2seq datasets, NavAgent outperforms strong baseline models. The code and dataset will be released to the community to facilitate the exploration and development of outdoor VLN.
AeroVerse: UAV-Agent Benchmark Suite for Simulating, Pre-training, Finetuning, and Evaluating Aerospace Embodied World Models
Aug 28, 2024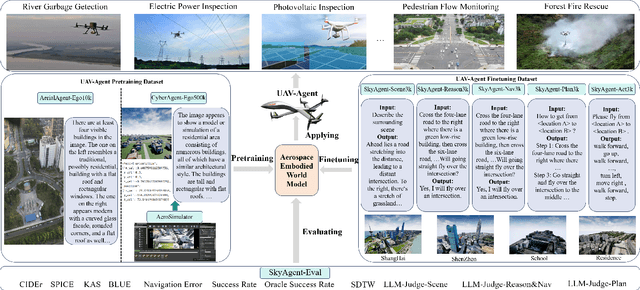
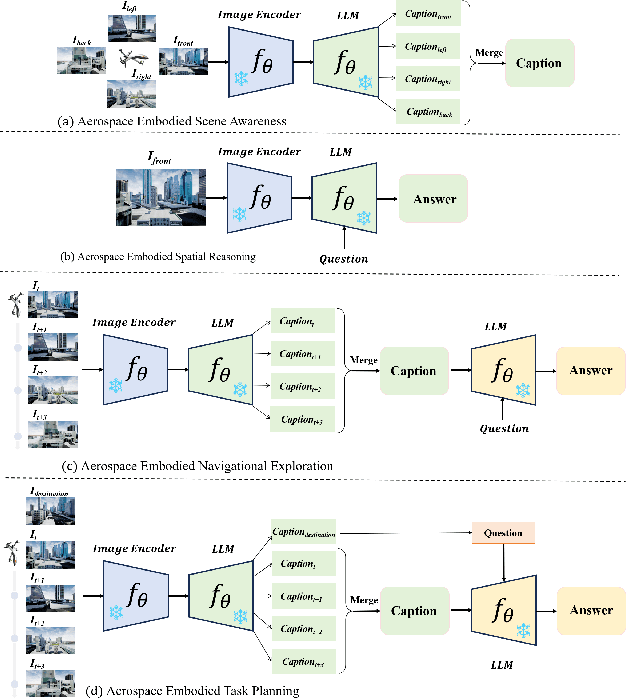


Aerospace embodied intelligence aims to empower unmanned aerial vehicles (UAVs) and other aerospace platforms to achieve autonomous perception, cognition, and action, as well as egocentric active interaction with humans and the environment. The aerospace embodied world model serves as an effective means to realize the autonomous intelligence of UAVs and represents a necessary pathway toward aerospace embodied intelligence. However, existing embodied world models primarily focus on ground-level intelligent agents in indoor scenarios, while research on UAV intelligent agents remains unexplored. To address this gap, we construct the first large-scale real-world image-text pre-training dataset, AerialAgent-Ego10k, featuring urban drones from a first-person perspective. We also create a virtual image-text-pose alignment dataset, CyberAgent Ego500k, to facilitate the pre-training of the aerospace embodied world model. For the first time, we clearly define 5 downstream tasks, i.e., aerospace embodied scene awareness, spatial reasoning, navigational exploration, task planning, and motion decision, and construct corresponding instruction datasets, i.e., SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k, for fine-tuning the aerospace embodiment world model. Simultaneously, we develop SkyAgentEval, the downstream task evaluation metrics based on GPT-4, to comprehensively, flexibly, and objectively assess the results, revealing the potential and limitations of 2D/3D visual language models in UAV-agent tasks. Furthermore, we integrate over 10 2D/3D visual-language models, 2 pre-training datasets, 5 finetuning datasets, more than 10 evaluation metrics, and a simulator into the benchmark suite, i.e., AeroVerse, which will be released to the community to promote exploration and development of aerospace embodied intelligence.
ReCon1M:A Large-scale Benchmark Dataset for Relation Comprehension in Remote Sensing Imagery
Jun 10, 2024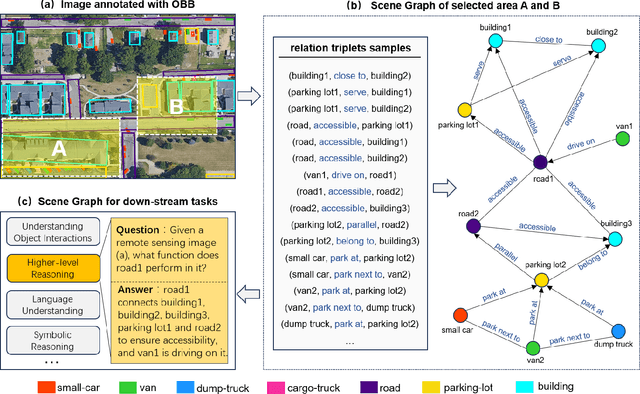
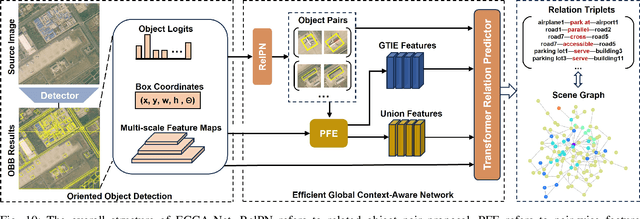
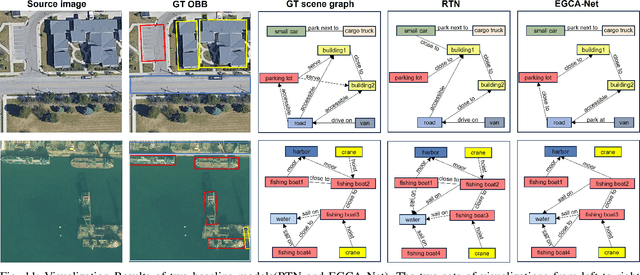
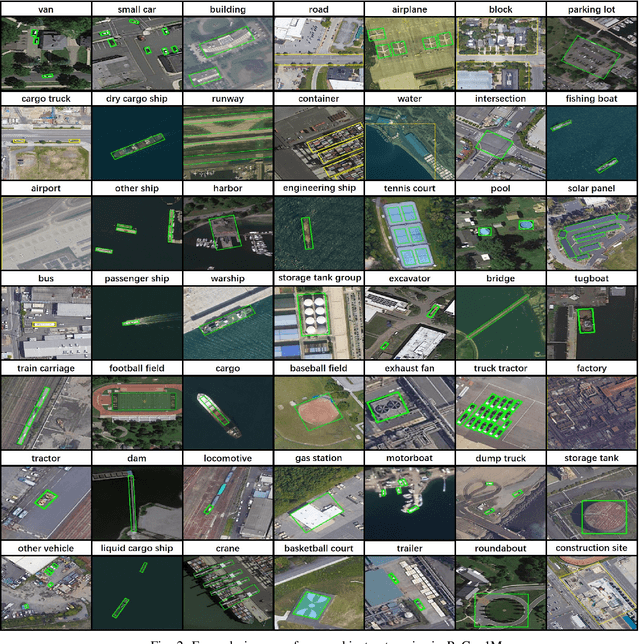
Scene Graph Generation (SGG) is a high-level visual understanding and reasoning task aimed at extracting entities (such as objects) and their interrelationships from images. Significant progress has been made in the study of SGG in natural images in recent years, but its exploration in the domain of remote sensing images remains very limited. The complex characteristics of remote sensing images necessitate higher time and manual interpretation costs for annotation compared to natural images. The lack of a large-scale public SGG benchmark is a major impediment to the advancement of SGG-related research in aerial imagery. In this paper, we introduce the first publicly available large-scale, million-level relation dataset in the field of remote sensing images which is named as ReCon1M. Specifically, our dataset is built upon Fair1M and comprises 21,392 images. It includes annotations for 859,751 object bounding boxes across 60 different categories, and 1,149,342 relation triplets across 64 categories based on these bounding boxes. We provide a detailed description of the dataset's characteristics and statistical information. We conducted two object detection tasks and three sub-tasks within SGG on this dataset, assessing the performance of mainstream methods on these tasks.
SFTformer: A Spatial-Frequency-Temporal Correlation-Decoupling Transformer for Radar Echo Extrapolation
Feb 28, 2024
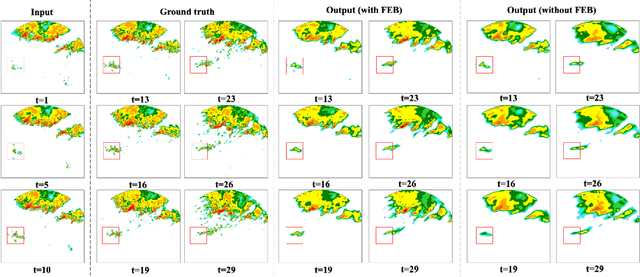
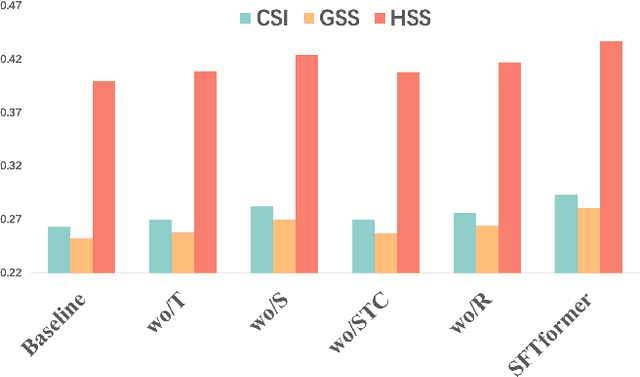
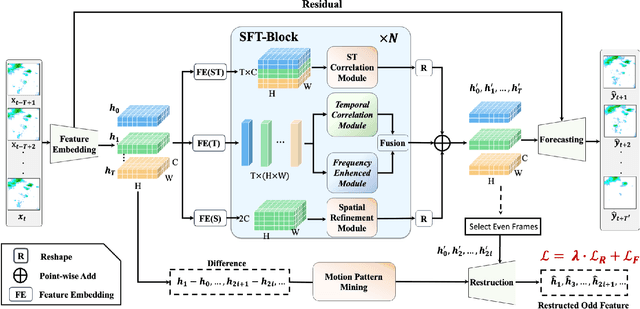
Extrapolating future weather radar echoes from past observations is a complex task vital for precipitation nowcasting. The spatial morphology and temporal evolution of radar echoes exhibit a certain degree of correlation, yet they also possess independent characteristics. {Existing methods learn unified spatial and temporal representations in a highly coupled feature space, emphasizing the correlation between spatial and temporal features but neglecting the explicit modeling of their independent characteristics, which may result in mutual interference between them.} To effectively model the spatiotemporal dynamics of radar echoes, we propose a Spatial-Frequency-Temporal correlation-decoupling Transformer (SFTformer). The model leverages stacked multiple SFT-Blocks to not only mine the correlation of the spatiotemporal dynamics of echo cells but also avoid the mutual interference between the temporal modeling and the spatial morphology refinement by decoupling them. Furthermore, inspired by the practice that weather forecast experts effectively review historical echo evolution to make accurate predictions, SFTfomer incorporates a joint training paradigm for historical echo sequence reconstruction and future echo sequence prediction. Experimental results on the HKO-7 dataset and ChinaNorth-2021 dataset demonstrate the superior performance of SFTfomer in short(1h), mid(2h), and long-term(3h) precipitation nowcasting.
Thinking Like an Expert:Multimodal Hypergraph-of-Thought (HoT) Reasoning to boost Foundation Modals
Aug 11, 2023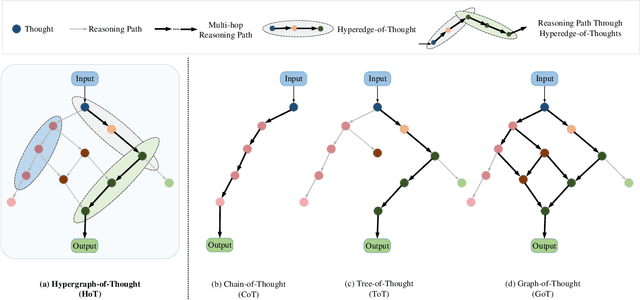

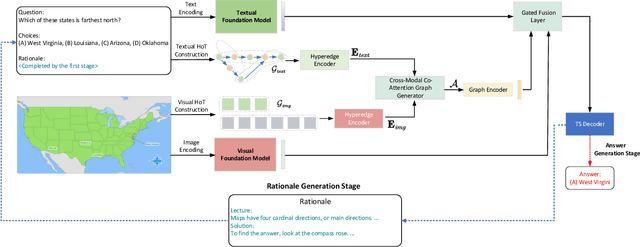

Reasoning ability is one of the most crucial capabilities of a foundation model, signifying its capacity to address complex reasoning tasks. Chain-of-Thought (CoT) technique is widely regarded as one of the effective methods for enhancing the reasoning ability of foundation models and has garnered significant attention. However, the reasoning process of CoT is linear, step-by-step, similar to personal logical reasoning, suitable for solving general and slightly complicated problems. On the contrary, the thinking pattern of an expert owns two prominent characteristics that cannot be handled appropriately in CoT, i.e., high-order multi-hop reasoning and multimodal comparative judgement. Therefore, the core motivation of this paper is transcending CoT to construct a reasoning paradigm that can think like an expert. The hyperedge of a hypergraph could connect various vertices, making it naturally suitable for modelling high-order relationships. Inspired by this, this paper innovatively proposes a multimodal Hypergraph-of-Thought (HoT) reasoning paradigm, which enables the foundation models to possess the expert-level ability of high-order multi-hop reasoning and multimodal comparative judgement. Specifically, a textual hypergraph-of-thought is constructed utilizing triple as the primary thought to model higher-order relationships, and a hyperedge-of-thought is generated through multi-hop walking paths to achieve multi-hop inference. Furthermore, we devise a visual hypergraph-of-thought to interact with the textual hypergraph-of-thought via Cross-modal Co-Attention Graph Learning for multimodal comparative verification. Experimentations on the ScienceQA benchmark demonstrate the proposed HoT-based T5 outperforms CoT-based GPT3.5 and chatGPT, which is on par with CoT-based GPT4 with a lower model size.