 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHISR: Hindsight Information Modulated Segmental Process Rewards For Multi-turn Agentic Reinforcement Learning
Mar 19, 2026While large language models excel in diverse domains, their performance on complex longhorizon agentic decision-making tasks remains limited. Most existing methods concentrate on designing effective reward models (RMs) to advance performance via multi-turn reinforcement learning. However, they suffer from delayed propagation in sparse outcome rewards and unreliable credit assignment with potentially overly fine-grained and unfocused turnlevel process rewards. In this paper, we propose (HISR) exploiting Hindsight Information to modulate Segmental process Rewards, which closely aligns rewards with sub-goals and underscores significant segments to enhance the reliability of credit assignment. Specifically, a segment-level process RM is presented to assign rewards for each sub-goal in the task, avoiding excessively granular allocation to turns. To emphasize significant segments in the trajectory, a hindsight model is devised to reflect the preference of performing a certain action after knowing the trajectory outcome. With this characteristic, we design the ratios of sequence likelihoods between hindsight and policy model to measure action importance. The ratios are subsequently employed to aggregate segment importance scores, which in turn modulate segmental process rewards, enhancing credit assignment reliability. Extensive experimental results on three publicly benchmarks demonstrate the validity of our method.
CoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Mar 01, 2026Open-world promptable 3D semantic segmentation remains brittle as semantics are inferred in the input sensor coordinates. Yet, humans, in contrast, interpret parts via functional roles in a canonical space -- wings extend laterally, handles protrude to the side, and legs support from below. Psychophysical evidence shows that we mentally rotate objects into canonical frames to reveal these roles. To fill this gap, we propose \methodName{}, which attains canonical space perception by inducing a latent canonical reference frame learned directly from data. By construction, we create a unified canonical dataset through LLM-guided intra- and cross-category alignment, exposing canonical spatial regularities across 200 categories. By induction, we realize canonicality inside the model through a dual-branch architecture with canonical map anchoring and canonical box calibration, collapsing pose variation and symmetry into a stable canonical embedding. This shift from input pose space to canonical embedding yields far more stable and transferable part semantics. Experimental results show that \methodName{} establishes new state of the art in open-world promptable 3D segmentation.
ES-Mem: Event Segmentation-Based Memory for Long-Term Dialogue Agents
Jan 13, 2026Memory is critical for dialogue agents to maintain coherence and enable continuous adaptation in long-term interactions. While existing memory mechanisms offer basic storage and retrieval capabilities, they are hindered by two primary limitations: (1) rigid memory granularity often disrupts semantic integrity, resulting in fragmented and incoherent memory units; (2) prevalent flat retrieval paradigms rely solely on surface-level semantic similarity, neglecting the structural cues of discourse required to navigate and locate specific episodic contexts. To mitigate these limitations, drawing inspiration from Event Segmentation Theory, we propose ES-Mem, a framework incorporating two core components: (1) a dynamic event segmentation module that partitions long-term interactions into semantically coherent events with distinct boundaries; (2) a hierarchical memory architecture that constructs multi-layered memories and leverages boundary semantics to anchor specific episodic memory for precise context localization. Evaluations on two memory benchmarks demonstrate that ES-Mem yields consistent performance gains over baseline methods. Furthermore, the proposed event segmentation module exhibits robust applicability on dialogue segmentation datasets.
Rectify Evaluation Preference: Improving LLMs' Critique on Math Reasoning via Perplexity-aware Reinforcement Learning
Nov 13, 2025To improve Multi-step Mathematical Reasoning (MsMR) of Large Language Models (LLMs), it is crucial to obtain scalable supervision from the corpus by automatically critiquing mistakes in the reasoning process of MsMR and rendering a final verdict of the problem-solution. Most existing methods rely on crafting high-quality supervised fine-tuning demonstrations for critiquing capability enhancement and pay little attention to delving into the underlying reason for the poor critiquing performance of LLMs. In this paper, we orthogonally quantify and investigate the potential reason -- imbalanced evaluation preference, and conduct a statistical preference analysis. Motivated by the analysis of the reason, a novel perplexity-aware reinforcement learning algorithm is proposed to rectify the evaluation preference, elevating the critiquing capability. Specifically, to probe into LLMs' critiquing characteristics, a One-to-many Problem-Solution (OPS) benchmark is meticulously constructed to quantify the behavior difference of LLMs when evaluating the problem solutions generated by itself and others. Then, to investigate the behavior difference in depth, we conduct a statistical preference analysis oriented on perplexity and find an intriguing phenomenon -- ``LLMs incline to judge solutions with lower perplexity as correct'', which is dubbed as \textit{imbalanced evaluation preference}. To rectify this preference, we regard perplexity as the baton in the algorithm of Group Relative Policy Optimization, supporting the LLMs to explore trajectories that judge lower perplexity as wrong and higher perplexity as correct. Extensive experimental results on our built OPS and existing available critic benchmarks demonstrate the validity of our method.
Embodied World Models Emerge from Navigational Task in Open-Ended Environments
Apr 15, 2025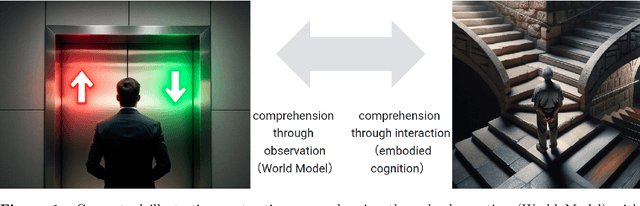
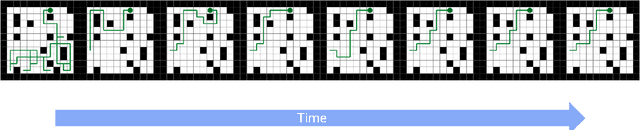
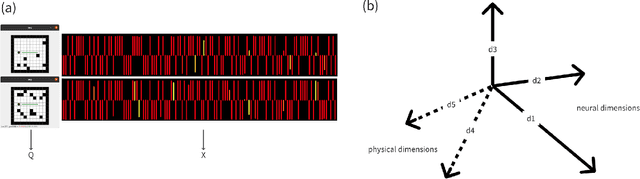
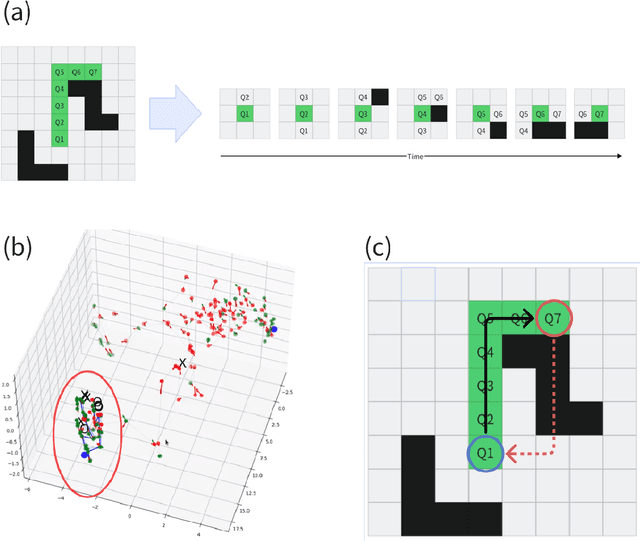
Understanding how artificial systems can develop spatial awareness and reasoning has long been a challenge in AI research. Traditional models often rely on passive observation, but embodied cognition theory suggests that deeper understanding emerges from active interaction with the environment. This study investigates whether neural networks can autonomously internalize spatial concepts through interaction, focusing on planar navigation tasks. Using Gated Recurrent Units (GRUs) combined with Meta-Reinforcement Learning (Meta-RL), we show that agents can learn to encode spatial properties like direction, distance, and obstacle avoidance. We introduce Hybrid Dynamical Systems (HDS) to model the agent-environment interaction as a closed dynamical system, revealing stable limit cycles that correspond to optimal navigation strategies. Ridge Representation allows us to map navigation paths into a fixed-dimensional behavioral space, enabling comparison with neural states. Canonical Correlation Analysis (CCA) confirms strong alignment between these representations, suggesting that the agent's neural states actively encode spatial knowledge. Intervention experiments further show that specific neural dimensions are causally linked to navigation performance. This work provides an approach to bridging the gap between action and perception in AI, offering new insights into building adaptive, interpretable models that can generalize across complex environments. The causal validation of neural representations also opens new avenues for understanding and controlling the internal mechanisms of AI systems, pushing the boundaries of how machines learn and reason in dynamic, real-world scenarios.
Semi-Gradient SARSA Routing with Theoretical Guarantee on Traffic Stability and Weight Convergence
Mar 19, 2025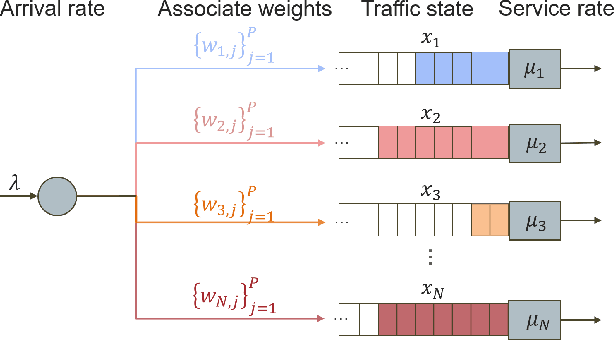
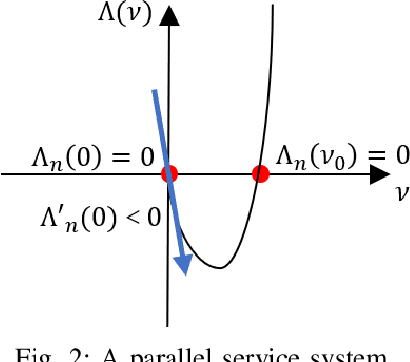
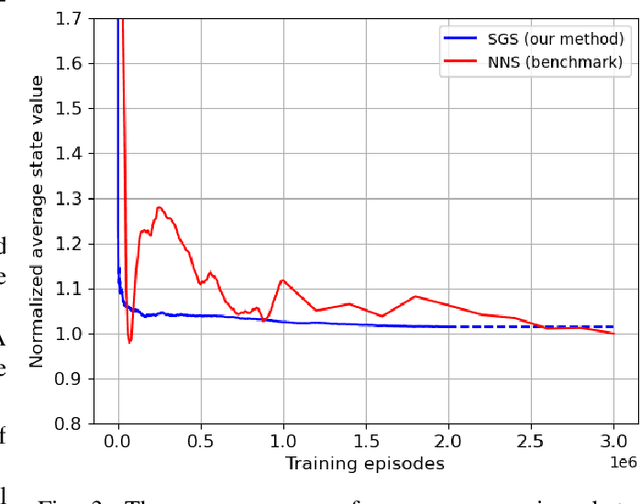

We consider the traffic control problem of dynamic routing over parallel servers, which arises in a variety of engineering systems such as transportation and data transmission. We propose a semi-gradient, on-policy algorithm that learns an approximate optimal routing policy. The algorithm uses generic basis functions with flexible weights to approximate the value function across the unbounded state space. Consequently, the training process lacks Lipschitz continuity of the gradient, boundedness of the temporal-difference error, and a prior guarantee on ergodicity, which are the standard prerequisites in existing literature on reinforcement learning theory. To address this, we combine a Lyapunov approach and an ordinary differential equation-based method to jointly characterize the behavior of traffic state and approximation weights. Our theoretical analysis proves that the training scheme guarantees traffic state stability and ensures almost surely convergence of the weights to the approximate optimum. We also demonstrate via simulations that our algorithm attains significantly faster convergence than neural network-based methods with an insignificant approximation error.
Benchmarking Multimodal RAG through a Chart-based Document Question-Answering Generation Framework
Feb 20, 2025Multimodal Retrieval-Augmented Generation (MRAG) enhances reasoning capabilities by integrating external knowledge. However, existing benchmarks primarily focus on simple image-text interactions, overlooking complex visual formats like charts that are prevalent in real-world applications. In this work, we introduce a novel task, Chart-based MRAG, to address this limitation. To semi-automatically generate high-quality evaluation samples, we propose CHARt-based document question-answering GEneration (CHARGE), a framework that produces evaluation data through structured keypoint extraction, crossmodal verification, and keypoint-based generation. By combining CHARGE with expert validation, we construct Chart-MRAG Bench, a comprehensive benchmark for chart-based MRAG evaluation, featuring 4,738 question-answering pairs across 8 domains from real-world documents. Our evaluation reveals three critical limitations in current approaches: (1) unified multimodal embedding retrieval methods struggles in chart-based scenarios, (2) even with ground-truth retrieval, state-of-the-art MLLMs achieve only 58.19% Correctness and 73.87% Coverage scores, and (3) MLLMs demonstrate consistent text-over-visual modality bias during Chart-based MRAG reasoning. The CHARGE and Chart-MRAG Bench are released at https://github.com/Nomothings/CHARGE.git.
COT: A Generative Approach for Hate Speech Counter-Narratives via Contrastive Optimal Transport
Jun 18, 2024



Counter-narratives, which are direct responses consisting of non-aggressive fact-based arguments, have emerged as a highly effective approach to combat the proliferation of hate speech. Previous methodologies have primarily focused on fine-tuning and post-editing techniques to ensure the fluency of generated contents, while overlooking the critical aspects of individualization and relevance concerning the specific hatred targets, such as LGBT groups, immigrants, etc. This research paper introduces a novel framework based on contrastive optimal transport, which effectively addresses the challenges of maintaining target interaction and promoting diversification in generating counter-narratives. Firstly, an Optimal Transport Kernel (OTK) module is leveraged to incorporate hatred target information in the token representations, in which the comparison pairs are extracted between original and transported features. Secondly, a self-contrastive learning module is employed to address the issue of model degeneration. This module achieves this by generating an anisotropic distribution of token representations. Finally, a target-oriented search method is integrated as an improved decoding strategy to explicitly promote domain relevance and diversification in the inference process. This strategy modifies the model's confidence score by considering both token similarity and target relevance. Quantitative and qualitative experiments have been evaluated on two benchmark datasets, which demonstrate that our proposed model significantly outperforms current methods evaluated by metrics from multiple aspects.
Dyna-Style Learning with A Macroscopic Model for Vehicle Platooning in Mixed-Autonomy Traffic
May 03, 2024



Platooning of connected and autonomous vehicles (CAVs) plays a vital role in modernizing highways, ushering in enhanced efficiency and safety. This paper explores the significance of platooning in smart highways, employing a coupled partial differential equation (PDE) and ordinary differential equation (ODE) model to elucidate the complex interaction between bulk traffic flow and CAV platoons. Our study focuses on developing a Dyna-style planning and learning framework tailored for platoon control, with a specific goal of reducing fuel consumption. By harnessing the coupled PDE-ODE model, we improve data efficiency in Dyna-style learning through virtual experiences. Simulation results validate the effectiveness of our macroscopic model in modeling platoons within mixed-autonomy settings, demonstrating a notable $10.11\%$ reduction in vehicular fuel consumption compared to conventional approaches.
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.