 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Gradient SARSA Routing with Theoretical Guarantee on Traffic Stability and Weight Convergence
Mar 19, 2025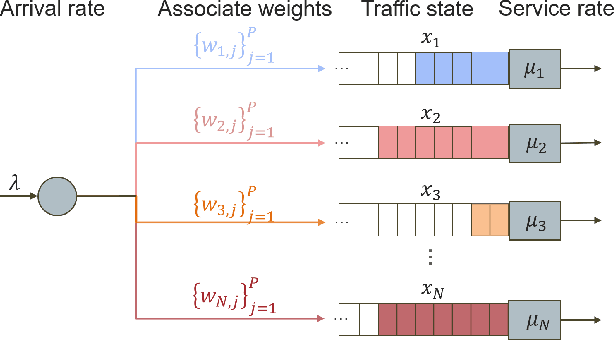
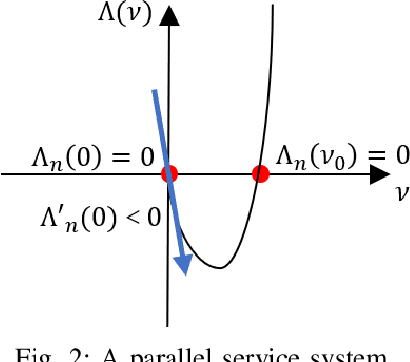
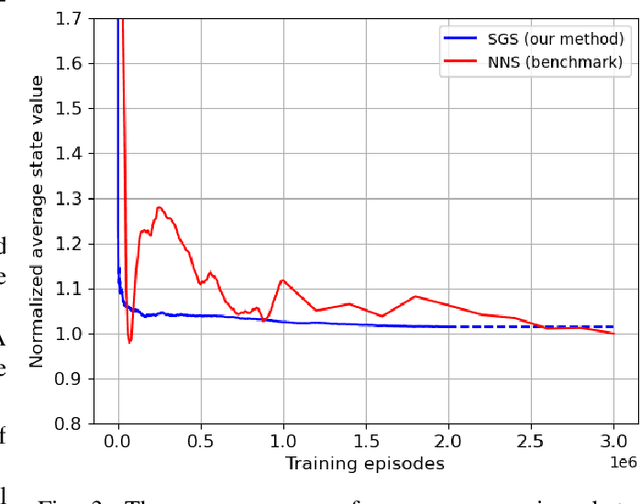

We consider the traffic control problem of dynamic routing over parallel servers, which arises in a variety of engineering systems such as transportation and data transmission. We propose a semi-gradient, on-policy algorithm that learns an approximate optimal routing policy. The algorithm uses generic basis functions with flexible weights to approximate the value function across the unbounded state space. Consequently, the training process lacks Lipschitz continuity of the gradient, boundedness of the temporal-difference error, and a prior guarantee on ergodicity, which are the standard prerequisites in existing literature on reinforcement learning theory. To address this, we combine a Lyapunov approach and an ordinary differential equation-based method to jointly characterize the behavior of traffic state and approximation weights. Our theoretical analysis proves that the training scheme guarantees traffic state stability and ensures almost surely convergence of the weights to the approximate optimum. We also demonstrate via simulations that our algorithm attains significantly faster convergence than neural network-based methods with an insignificant approximation error.
Precise Drive with VLM: First Prize Solution for PRCV 2024 Drive LM challenge
Nov 05, 2024



This technical report outlines the methodologies we applied for the PRCV Challenge, focusing on cognition and decision-making in driving scenarios. We employed InternVL-2.0, a pioneering open-source multi-modal model, and enhanced it by refining both the model input and training methodologies. For the input data, we strategically concatenated and formatted the multi-view images. It is worth mentioning that we utilized the coordinates of the original images without transformation. In terms of model training, we initially pre-trained the model on publicly available autonomous driving scenario datasets to bolster its alignment capabilities of the challenge tasks, followed by fine-tuning on the DriveLM-nuscenes Dataset. During the fine-tuning phase, we innovatively modified the loss function to enhance the model's precision in predicting coordinate values. These approaches ensure that our model possesses advanced cognitive and decision-making capabilities in driving scenarios. Consequently, our model achieved a score of 0.6064, securing the first prize on the competition's final results.