 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastBEV++: Fast by Algorithm, Deployable by Design
Dec 09, 2025The advancement of camera-only Bird's-Eye-View(BEV) perception is currently impeded by a fundamental tension between state-of-the-art performance and on-vehicle deployment tractability. This bottleneck stems from a deep-rooted dependency on computationally prohibitive view transformations and bespoke, platform-specific kernels. This paper introduces FastBEV++, a framework engineered to reconcile this tension, demonstrating that high performance and deployment efficiency can be achieved in unison via two guiding principles: Fast by Algorithm and Deployable by Design. We realize the "Deployable by Design" principle through a novel view transformation paradigm that decomposes the monolithic projection into a standard Index-Gather-Reshape pipeline. Enabled by a deterministic pre-sorting strategy, this transformation is executed entirely with elementary, operator native primitives (e.g Gather, Matrix Multiplication), which eliminates the need for specialized CUDA kernels and ensures fully TensorRT-native portability. Concurrently, our framework is "Fast by Algorithm", leveraging this decomposed structure to seamlessly integrate an end-to-end, depth-aware fusion mechanism. This jointly learned depth modulation, further bolstered by temporal aggregation and robust data augmentation, significantly enhances the geometric fidelity of the BEV representation.Empirical validation on the nuScenes benchmark corroborates the efficacy of our approach. FastBEV++ establishes a new state-of-the-art 0.359 NDS while maintaining exceptional real-time performance, exceeding 134 FPS on automotive-grade hardware (e.g Tesla T4). By offering a solution that is free of custom plugins yet highly accurate, FastBEV++ presents a mature and scalable design philosophy for production autonomous systems. The code is released at: https://github.com/ymlab/advanced-fastbev
Precise Drive with VLM: First Prize Solution for PRCV 2024 Drive LM challenge
Nov 05, 2024



This technical report outlines the methodologies we applied for the PRCV Challenge, focusing on cognition and decision-making in driving scenarios. We employed InternVL-2.0, a pioneering open-source multi-modal model, and enhanced it by refining both the model input and training methodologies. For the input data, we strategically concatenated and formatted the multi-view images. It is worth mentioning that we utilized the coordinates of the original images without transformation. In terms of model training, we initially pre-trained the model on publicly available autonomous driving scenario datasets to bolster its alignment capabilities of the challenge tasks, followed by fine-tuning on the DriveLM-nuscenes Dataset. During the fine-tuning phase, we innovatively modified the loss function to enhance the model's precision in predicting coordinate values. These approaches ensure that our model possesses advanced cognitive and decision-making capabilities in driving scenarios. Consequently, our model achieved a score of 0.6064, securing the first prize on the competition's final results.
RTN: Reparameterized Ternary Network
Dec 12, 2019
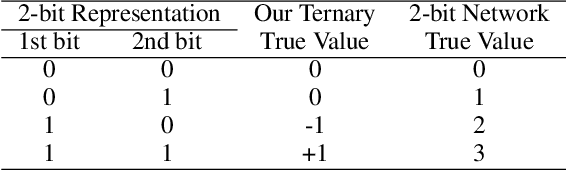
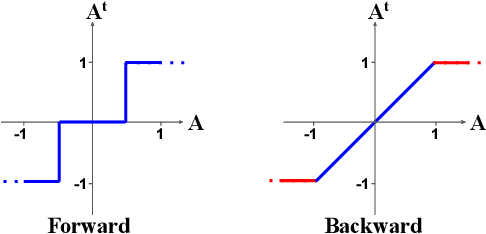

To deploy deep neural networks on resource-limited devices, quantization has been widely explored. In this work, we study the extremely low-bit networks which have tremendous speed-up, memory saving with quantized activation and weights. We first bring up three omitted issues in extremely low-bit networks: the squashing range of quantized values; the gradient vanishing during backpropagation and the unexploited hardware acceleration of ternary networks. By reparameterizing quantized activation and weights vector with full precision scale and offset for fixed ternary vector, we decouple the range and magnitude from the direction to extenuate the three issues. Learnable scale and offset can automatically adjust the range of quantized values and sparsity without gradient vanishing. A novel encoding and computation pat-tern are designed to support efficient computing for our reparameterized ternary network (RTN). Experiments on ResNet-18 for ImageNet demonstrate that the proposed RTN finds a much better efficiency between bitwidth and accuracy, and achieves up to 26.76% relative accuracy improvement compared with state-of-the-art methods. Moreover, we validate the proposed computation pattern on Field Programmable Gate Arrays (FPGA), and it brings 46.46x and 89.17x savings on power and area respectively compared with the full precision convolution.