 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTN: Reparameterized Ternary Network
Paper and Code

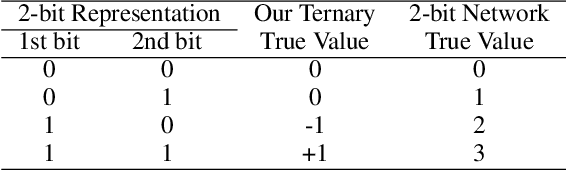
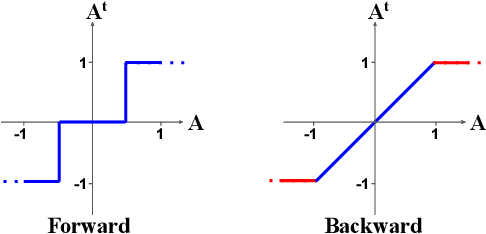

To deploy deep neural networks on resource-limited devices, quantization has been widely explored. In this work, we study the extremely low-bit networks which have tremendous speed-up, memory saving with quantized activation and weights. We first bring up three omitted issues in extremely low-bit networks: the squashing range of quantized values; the gradient vanishing during backpropagation and the unexploited hardware acceleration of ternary networks. By reparameterizing quantized activation and weights vector with full precision scale and offset for fixed ternary vector, we decouple the range and magnitude from the direction to extenuate the three issues. Learnable scale and offset can automatically adjust the range of quantized values and sparsity without gradient vanishing. A novel encoding and computation pat-tern are designed to support efficient computing for our reparameterized ternary network (RTN). Experiments on ResNet-18 for ImageNet demonstrate that the proposed RTN finds a much better efficiency between bitwidth and accuracy, and achieves up to 26.76% relative accuracy improvement compared with state-of-the-art methods. Moreover, we validate the proposed computation pattern on Field Programmable Gate Arrays (FPGA), and it brings 46.46x and 89.17x savings on power and area respectively compared with the full precision convolution.