 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
OVD: On-policy Verbal Distillation
Jan 29, 2026Knowledge distillation offers a promising path to transfer reasoning capabilities from large teacher models to efficient student models; however, existing token-level on-policy distillation methods require token-level alignment between the student and teacher models, which restricts the student model's exploration ability, prevent effective use of interactive environment feedback, and suffer from severe memory bottlenecks in reinforcement learning. We introduce On-policy Verbal Distillation (OVD), a memory-efficient framework that replaces token-level probability matching with trajectory matching using discrete verbal scores (0--9) from teacher models. OVD dramatically reduces memory consumption while enabling on-policy distillation from teacher models with verbal feedback, and avoids token-level alignment, allowing the student model to freely explore the output space. Extensive experiments on Web question answering and mathematical reasoning tasks show that OVD substantially outperforms existing methods, delivering up to +12.9% absolute improvement in average EM on Web Q&A tasks and a up to +25.7% gain on math benchmarks (when trained with only one random samples), while also exhibiting superior training efficiency. Our project page is available at https://OVD.github.io
From Verifiable Dot to Reward Chain: Harnessing Verifiable Reference-based Rewards for Reinforcement Learning of Open-ended Generation
Jan 26, 2026Reinforcement learning with verifiable rewards (RLVR) succeeds in reasoning tasks (e.g., math and code) by checking the final verifiable answer (i.e., a verifiable dot signal). However, extending this paradigm to open-ended generation is challenging because there is no unambiguous ground truth. Relying on single-dot supervision often leads to inefficiency and reward hacking. To address these issues, we propose reinforcement learning with verifiable reference-based rewards (RLVRR). Instead of checking the final answer, RLVRR extracts an ordered linguistic signal from high-quality references (i.e, reward chain). Specifically, RLVRR decomposes rewards into two dimensions: content, which preserves deterministic core concepts (e.g., keywords), and style, which evaluates adherence to stylistic properties through LLM-based verification. In this way, RLVRR combines the exploratory strength of RL with the efficiency and reliability of supervised fine-tuning (SFT). Extensive experiments on more than 10 benchmarks with Qwen and Llama models confirm the advantages of our approach. RLVRR (1) substantially outperforms SFT trained with ten times more data and advanced reward models, (2) unifies the training of structured reasoning and open-ended generation, and (3) generalizes more effectively while preserving output diversity. These results establish RLVRR as a principled and efficient path toward verifiable reinforcement learning for general-purpose LLM alignment. We release our code and data at https://github.com/YJiangcm/RLVRR.
What Makes Low-Bit Quantization-Aware Training Work for Reasoning LLMs? A Systematic Study
Jan 21, 2026Reasoning models excel at complex tasks such as coding and mathematics, yet their inference is often slow and token-inefficient. To improve the inference efficiency, post-training quantization (PTQ) usually comes with the cost of large accuracy drops, especially for reasoning tasks under low-bit settings. In this study, we present a systematic empirical study of quantization-aware training (QAT) for reasoning models. Our key findings include: (1) Knowledge distillation is a robust objective for reasoning models trained via either supervised fine-tuning or reinforcement learning; (2) PTQ provides a strong initialization for QAT, improving accuracy while reducing training cost; (3) Reinforcement learning remains feasible for quantized models given a viable cold start and yields additional gains; and (4) Aligning the PTQ calibration domain with the QAT training domain accelerates convergence and often improves the final accuracy. Finally, we consolidate these findings into an optimized workflow (Reasoning-QAT), and show that it consistently outperforms state-of-the-art PTQ methods across multiple LLM backbones and reasoning datasets. For instance, on Qwen3-0.6B, it surpasses GPTQ by 44.53% on MATH-500 and consistently recovers performance in the 2-bit regime.
Benchmarking Post-Training Quantization of Large Language Models under Microscaling Floating Point Formats
Jan 14, 2026Microscaling Floating-Point (MXFP) has emerged as a promising low-precision format for large language models (LLMs). Despite various post-training quantization (PTQ) algorithms being proposed, they mostly focus on integer quantization, while their applicability and behavior under MXFP formats remain largely unexplored. To address this gap, this work conducts a systematic investigation of PTQ under MXFP formats, encompassing over 7 PTQ algorithms, 15 evaluation benchmarks, and 3 LLM families. The key findings include: 1) MXFP8 consistently achieves near-lossless performance, while MXFP4 introduces substantial accuracy degradation and remains challenging; 2) PTQ effectiveness under MXFP depends strongly on format compatibility, with some algorithmic paradigms being consistently more effective than others; 3) PTQ performance exhibits highly consistent trends across model families and modalities, in particular, quantization sensitivity is dominated by the language model rather than the vision encoder in multimodal LLMs; 4) The scaling factor of quantization is a critical error source in MXFP4, and a simple pre-scale optimization strategy can significantly mitigate its impact. Together, these results provide practical guidance on adapting existing PTQ methods to MXFP quantization.
SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion Language Model Backbone
Dec 27, 2025While autoregressive Large Vision-Language Models (VLMs) have achieved remarkable success, their sequential generation often limits their efficacy in complex visual planning and dynamic robotic control. In this work, we investigate the potential of constructing Vision-Language Models upon diffusion-based large language models (dLLMs) to overcome these limitations. We introduce Dream-VL, an open diffusion-based VLM (dVLM) that achieves state-of-the-art performance among previous dVLMs. Dream-VL is comparable to top-tier AR-based VLMs trained on open data on various benchmarks but exhibits superior potential when applied to visual planning tasks. Building upon Dream-VL, we introduce Dream-VLA, a dLLM-based Vision-Language-Action model (dVLA) developed through continuous pre-training on open robotic datasets. We demonstrate that the natively bidirectional nature of this diffusion backbone serves as a superior foundation for VLA tasks, inherently suited for action chunking and parallel generation, leading to significantly faster convergence in downstream fine-tuning. Dream-VLA achieves top-tier performance of 97.2% average success rate on LIBERO, 71.4% overall average on SimplerEnv-Bridge, and 60.5% overall average on SimplerEnv-Fractal, surpassing leading models such as $π_0$ and GR00T-N1. We also validate that dVLMs surpass AR baselines on downstream tasks across different training objectives. We release both Dream-VL and Dream-VLA to facilitate further research in the community.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
A1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025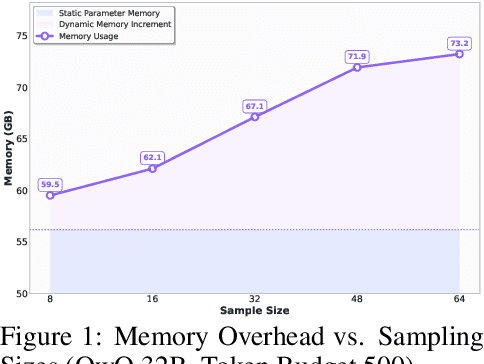
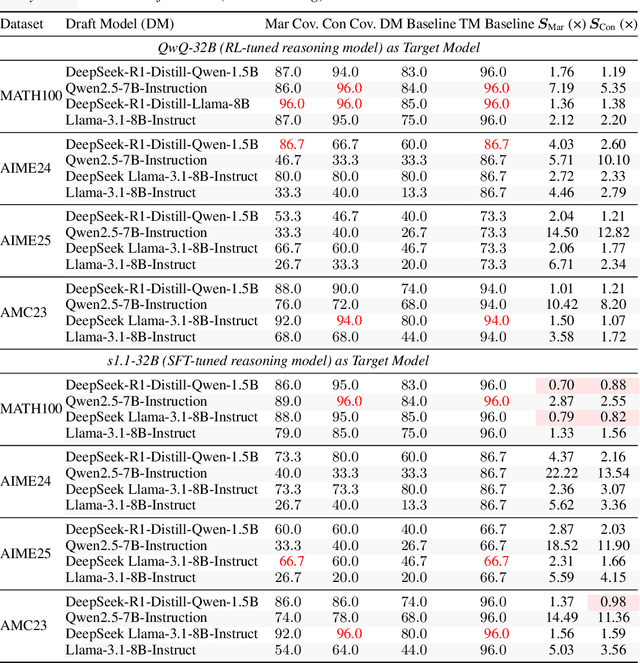
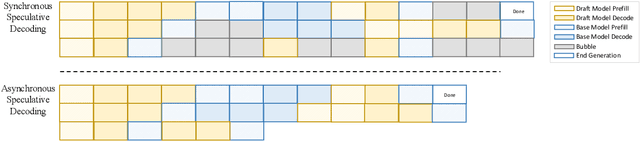
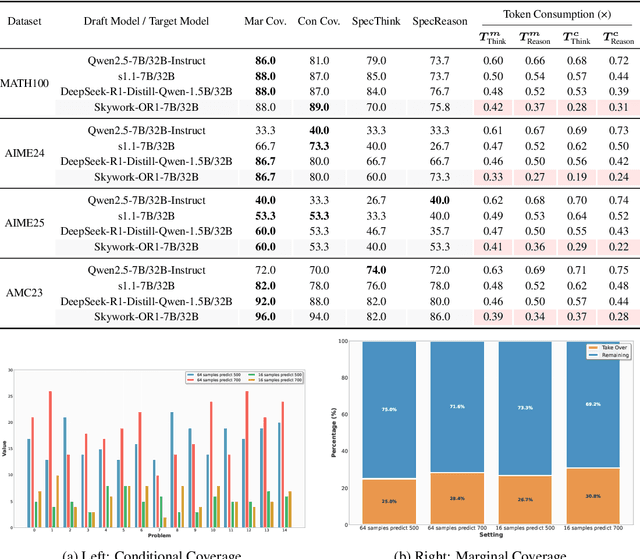
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.