 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
Visually Guided Generative Text-Layout Pre-training for Document Intelligence
Mar 27, 2024



Prior study shows that pre-training techniques can boost the performance of visual document understanding (VDU), which typically requires models to gain abilities to perceive and reason both document texts and layouts (e.g., locations of texts and table-cells). To this end, we propose visually guided generative text-layout pre-training, named ViTLP. Given a document image, the model optimizes hierarchical language and layout modeling objectives to generate the interleaved text and layout sequence. In addition, to address the limitation of processing long documents by Transformers, we introduce a straightforward yet effective multi-segment generative pre-training scheme, facilitating ViTLP to process word-intensive documents of any length. ViTLP can function as a native OCR model to localize and recognize texts of document images. Besides, ViTLP can be effectively applied to various downstream VDU tasks. Extensive experiments show that ViTLP achieves competitive performance over existing baselines on benchmark VDU tasks, including information extraction, document classification, and document question answering.
UniTRec: A Unified Text-to-Text Transformer and Joint Contrastive Learning Framework for Text-based Recommendation
May 25, 2023Prior study has shown that pretrained language models (PLM) can boost the performance of text-based recommendation. In contrast to previous works that either use PLM to encode user history as a whole input text, or impose an additional aggregation network to fuse multi-turn history representations, we propose a unified local- and global-attention Transformer encoder to better model two-level contexts of user history. Moreover, conditioned on user history encoded by Transformer encoders, our framework leverages Transformer decoders to estimate the language perplexity of candidate text items, which can serve as a straightforward yet significant contrastive signal for user-item text matching. Based on this, our framework, UniTRec, unifies the contrastive objectives of discriminative matching scores and candidate text perplexity to jointly enhance text-based recommendation. Extensive evaluation shows that UniTRec delivers SOTA performance on three text-based recommendation tasks. Code is available at https://github.com/Veason-silverbullet/UniTRec.
DIGAT: Modeling News Recommendation with Dual-Graph Interaction
Oct 11, 2022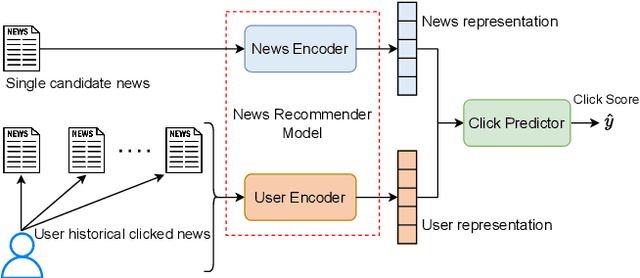
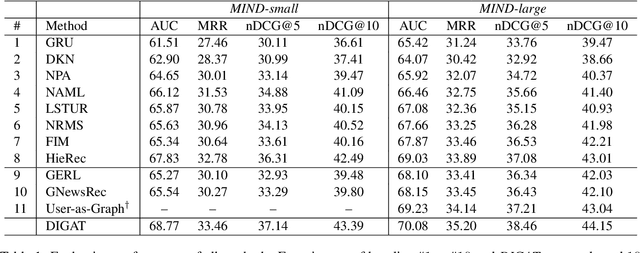
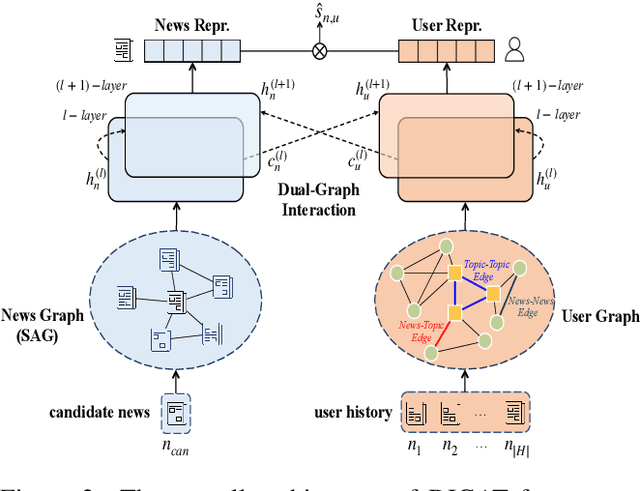
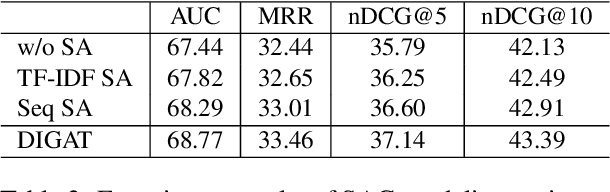
News recommendation (NR) is essential for online news services. Existing NR methods typically adopt a news-user representation learning framework, facing two potential limitations. First, in news encoder, single candidate news encoding suffers from an insufficient semantic information problem. Second, existing graph-based NR methods are promising but lack effective news-user feature interaction, rendering the graph-based recommendation suboptimal. To overcome these limitations, we propose dual-interactive graph attention networks (DIGAT) consisting of news- and user-graph channels. In the news-graph channel, we enrich the semantics of single candidate news by incorporating the semantically relevant news information with a semantic-augmented graph (SAG). In the user-graph channel, multi-level user interests are represented with a news-topic graph. Most notably, we design a dual-graph interaction process to perform effective feature interaction between the news and user graphs, which facilitates accurate news-user representation matching. Experiment results on the benchmark dataset MIND show that DIGAT outperforms existing news recommendation methods. Further ablation studies and analyses validate the effectiveness of (1) semantic-augmented news graph modeling and (2) dual-graph interaction.
Neural News Recommendation with Collaborative News Encoding and Structural User Encoding
Sep 18, 2021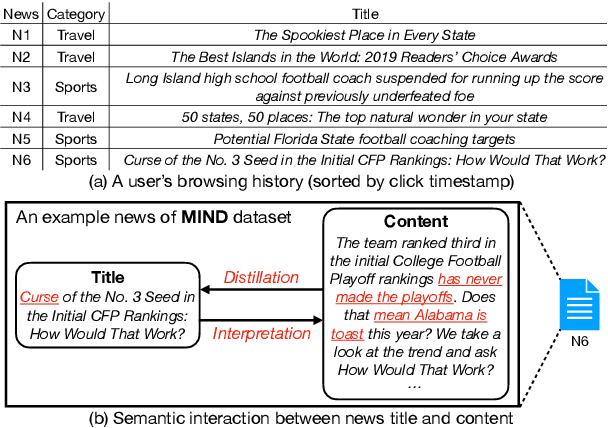
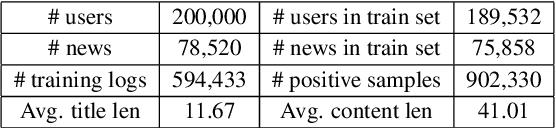
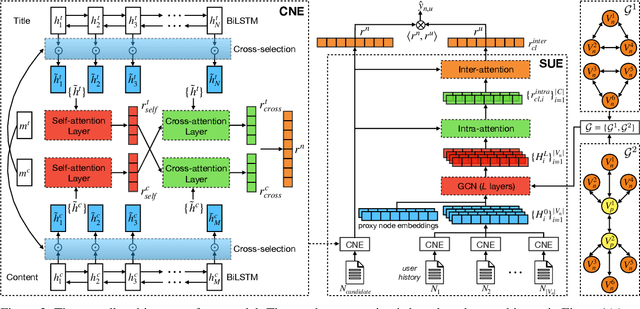
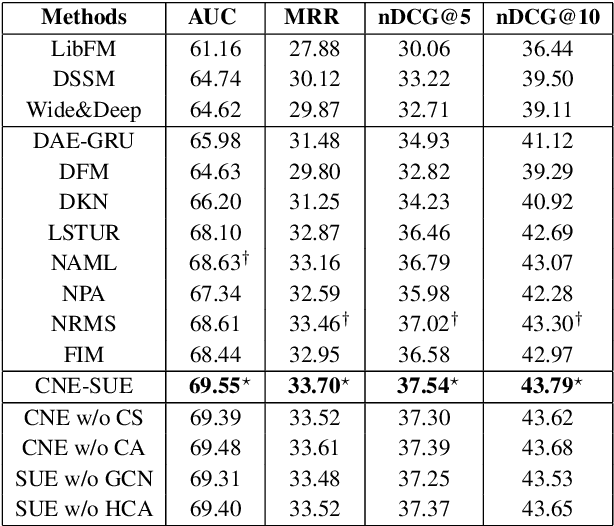
Automatic news recommendation has gained much attention from the academic community and industry. Recent studies reveal that the key to this task lies within the effective representation learning of both news and users. Existing works typically encode news title and content separately while neglecting their semantic interaction, which is inadequate for news text comprehension. Besides, previous models encode user browsing history without leveraging the structural correlation of user browsed news to reflect user interests explicitly. In this work, we propose a news recommendation framework consisting of collaborative news encoding (CNE) and structural user encoding (SUE) to enhance news and user representation learning. CNE equipped with bidirectional LSTMs encodes news title and content collaboratively with cross-selection and cross-attention modules to learn semantic-interactive news representations. SUE utilizes graph convolutional networks to extract cluster-structural features of user history, followed by intra-cluster and inter-cluster attention modules to learn hierarchical user interest representations. Experiment results on the MIND dataset validate the effectiveness of our model to improve the performance of news recommendation. Our code is released at https://github.com/Veason-silverbullet/NNR.