 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Tokens: Semantic-Aware Speculative Decoding for Efficient Inference by Probing Internal States
Feb 03, 2026Large Language Models (LLMs) achieve strong performance across many tasks but suffer from high inference latency due to autoregressive decoding. The issue is exacerbated in Large Reasoning Models (LRMs), which generate lengthy chains of thought. While speculative decoding accelerates inference by drafting and verifying multiple tokens in parallel, existing methods operate at the token level and ignore semantic equivalence (i.e., different token sequences expressing the same meaning), leading to inefficient rejections. We propose SemanticSpec, a semantic-aware speculative decoding framework that verifies entire semantic sequences instead of tokens. SemanticSpec introduces a semantic probability estimation mechanism that probes the model's internal hidden states to assess the likelihood of generating sequences with specific meanings.Experiments on four benchmarks show that SemanticSpec achieves up to 2.7x speedup on DeepSeekR1-32B and 2.1x on QwQ-32B, consistently outperforming token-level and sequence-level baselines in both efficiency and effectiveness.
ZipMoE: Efficient On-Device MoE Serving via Lossless Compression and Cache-Affinity Scheduling
Jan 29, 2026While Mixture-of-Experts (MoE) architectures substantially bolster the expressive power of large-language models, their prohibitive memory footprint severely impedes the practical deployment on resource-constrained edge devices, especially when model behavior must be preserved without relying on lossy quantization. In this paper, we present ZipMoE, an efficient and semantically lossless on-device MoE serving system. ZipMoE exploits the synergy between the hardware properties of edge devices and the statistical redundancy inherent to MoE parameters via a caching-scheduling co-design with provable performance guarantee. Fundamentally, our design shifts the paradigm of on-device MoE inference from an I/O-bound bottleneck to a compute-centric workflow that enables efficient parallelization. We implement a prototype of ZipMoE and conduct extensive experiments on representative edge computing platforms using popular open-source MoE models and real-world workloads. Our evaluation reveals that ZipMoE achieves up to $72.77\%$ inference latency reduction and up to $6.76\times$ higher throughput than the state-of-the-art systems.
SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
Model Performance-Guided Evaluation Data Selection for Effective Prompt Optimization
May 15, 2025


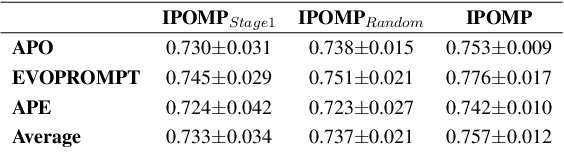
Optimizing Large Language Model (LLM) performance requires well-crafted prompts, but manual prompt engineering is labor-intensive and often ineffective. Automated prompt optimization techniques address this challenge but the majority of them rely on randomly selected evaluation subsets, which fail to represent the full dataset, leading to unreliable evaluations and suboptimal prompts. Existing coreset selection methods, designed for LLM benchmarking, are unsuitable for prompt optimization due to challenges in clustering similar samples, high data collection costs, and the unavailability of performance data for new or private datasets. To overcome these issues, we propose IPOMP, an Iterative evaluation data selection for effective Prompt Optimization using real-time Model Performance. IPOMP is a two-stage approach that selects representative and diverse samples using semantic clustering and boundary analysis, followed by iterative refinement with real-time model performance data to replace redundant samples. Evaluations on the BIG-bench dataset show that IPOMP improves effectiveness by 1.6% to 5.3% and stability by at least 57% compared with SOTA baselines, with minimal computational overhead below 1%. Furthermore, the results demonstrate that our real-time performance-guided refinement approach can be universally applied to enhance existing coreset selection methods.
A Study On Mixup-inspired Augmentation Methods For Software Vulnerability Detection
Apr 22, 2025Various Deep Learning (DL) methods have recently been utilized to detect software vulnerabilities. Real-world software vulnerability datasets are rare and hard to acquire as there's no simple metric for classifying vulnerability. Such datasets are heavily imbalanced, and none of the current datasets are considered huge for DL models. To tackle these problems a recent work has tried to augment the dataset using the source code and generate realistic single-statement vulnerabilities which is not quite practical and requires manual checking of the generated vulnerabilities. In this regard, we aim to explore the augmentation of vulnerabilities at the representation level to help current models learn better which has never been done before to the best of our knowledge. We implement and evaluate the 5 augmentation techniques that augment the embedding of the data and recently have been used for code search which is a completely different software engineering task. We also introduced a conditioned version of those augmentation methods, which ensures the augmentation does not change the vulnerable section of the vector representation. We show that such augmentation methods can be helpful and increase the f1-score by up to 9.67%, yet they cannot beat Random Oversampling when balancing datasets which increases the f1-score by 10.82%!
Nearly Optimal Differentially Private ReLU Regression
Mar 08, 2025In this paper, we investigate one of the most fundamental nonconvex learning problems, ReLU regression, in the Differential Privacy (DP) model. Previous studies on private ReLU regression heavily rely on stringent assumptions, such as constant bounded norms for feature vectors and labels. We relax these assumptions to a more standard setting, where data can be i.i.d. sampled from $O(1)$-sub-Gaussian distributions. We first show that when $\varepsilon = \tilde{O}(\sqrt{\frac{1}{N}})$ and there is some public data, it is possible to achieve an upper bound of $\Tilde{O}(\frac{d^2}{N^2 \varepsilon^2})$ for the excess population risk in $(\epsilon, \delta)$-DP, where $d$ is the dimension and $N$ is the number of data samples. Moreover, we relax the requirement of $\epsilon$ and public data by proposing and analyzing a one-pass mini-batch Generalized Linear Model Perceptron algorithm (DP-MBGLMtron). Additionally, using the tracing attack argument technique, we demonstrate that the minimax rate of the estimation error for $(\varepsilon, \delta)$-DP algorithms is lower bounded by $\Omega(\frac{d^2}{N^2 \varepsilon^2})$. This shows that DP-MBGLMtron achieves the optimal utility bound up to logarithmic factors. Experiments further support our theoretical results.
On Theoretical Limits of Learning with Label Differential Privacy
Feb 20, 2025Label differential privacy (DP) is designed for learning problems involving private labels and public features. While various methods have been proposed for learning under label DP, the theoretical limits remain largely unexplored. In this paper, we investigate the fundamental limits of learning with label DP in both local and central models for both classification and regression tasks, characterized by minimax convergence rates. We establish lower bounds by converting each task into a multiple hypothesis testing problem and bounding the test error. Additionally, we develop algorithms that yield matching upper bounds. Our results demonstrate that under label local DP (LDP), the risk has a significantly faster convergence rate than that under full LDP, i.e. protecting both features and labels, indicating the advantages of relaxing the DP definition to focus solely on labels. In contrast, under the label central DP (CDP), the risk is only reduced by a constant factor compared to full DP, indicating that the relaxation of CDP only has limited benefits on the performance.
The Impact of Input Order Bias on Large Language Models for Software Fault Localization
Dec 25, 2024



Large Language Models (LLMs) show great promise in software engineering tasks like Fault Localization (FL) and Automatic Program Repair (APR). This study examines how input order and context size affect LLM performance in FL, a key step for many downstream software engineering tasks. We test different orders for methods using Kendall Tau distances, including "perfect" (where ground truths come first) and "worst" (where ground truths come last). Our results show a strong bias in order, with Top-1 accuracy falling from 57\% to 20\% when we reverse the code order. Breaking down inputs into smaller contexts helps reduce this bias, narrowing the performance gap between perfect and worst orders from 22\% to just 1\%. We also look at ordering methods based on traditional FL techniques and metrics. Ordering using DepGraph's ranking achieves 48\% Top-1 accuracy, better than more straightforward ordering approaches like CallGraph. These findings underscore the importance of how we structure inputs, manage contexts, and choose ordering methods to improve LLM performance in FL and other software engineering tasks.
DiagramQG: A Dataset for Generating Concept-Focused Questions from Diagrams
Nov 26, 2024



Visual Question Generation (VQG) has gained significant attention due to its potential in educational applications. However, VQG researches mainly focus on natural images, neglecting diagrams in educational materials used to assess students' conceptual understanding. To address this gap, we introduce DiagramQG, a dataset containing 8,372 diagrams and 19,475 questions across various subjects. DiagramQG introduces concept and target text constraints, guiding the model to generate concept-focused questions for educational purposes. Meanwhile, we present the Hierarchical Knowledge Integration framework for Diagram Question Generation (HKI-DQG) as a strong baseline. This framework obtains multi-scale patches of diagrams and acquires knowledge using a visual language model with frozen parameters. It then integrates knowledge, text constraints and patches to generate concept-focused questions. We evaluate the performance of existing VQG models, open-source and closed-source vision-language models, and HKI-DQG on the DiagramQG dataset. Our HKI-DQG outperform existing methods, demonstrating that it serves as a strong baseline. Furthermore, to assess its generalizability, we apply HKI-DQG to two other VQG datasets of natural images, namely VQG-COCO and K-VQG, achieving state-of-the-art performance.The dataset and code are available at https://dxzxy12138.github.io/diagramqg-home.
PromptExp: Multi-granularity Prompt Explanation of Large Language Models
Oct 16, 2024



Large Language Models excel in tasks like natural language understanding and text generation. Prompt engineering plays a critical role in leveraging LLM effectively. However, LLMs black-box nature hinders its interpretability and effective prompting engineering. A wide range of model explanation approaches have been developed for deep learning models, However, these local explanations are designed for single-output tasks like classification and regression,and cannot be directly applied to LLMs, which generate sequences of tokens. Recent efforts in LLM explanation focus on natural language explanations, but they are prone to hallucinations and inaccuracies. To address this, we introduce OurTool, a framework for multi-granularity prompt explanations by aggregating token-level insights. OurTool introduces two token-level explanation approaches: 1.an aggregation-based approach combining local explanation techniques, and 2. a perturbation-based approach with novel techniques to evaluate token masking impact. OurTool supports both white-box and black-box explanations and extends explanations to higher granularity levels, enabling flexible analysis. We evaluate OurTool in case studies such as sentiment analysis, showing the perturbation-based approach performs best using semantic similarity to assess perturbation impact. Furthermore, we conducted a user study to confirm OurTool's accuracy and practical value, and demonstrate its potential to enhance LLM interpretability.