 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring RAG-based Vulnerability Augmentation with LLMs
Aug 07, 2024

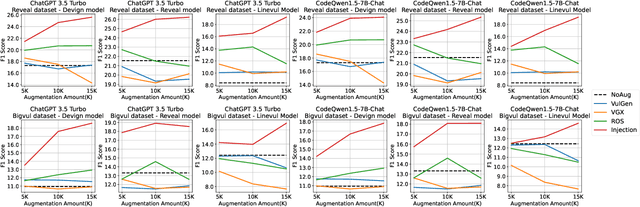
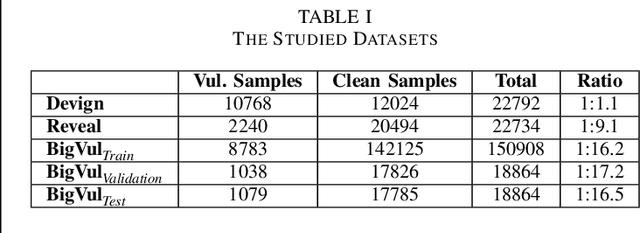
Detecting vulnerabilities is a crucial task for maintaining the integrity, availability, and security of software systems. Utilizing DL-based models for vulnerability detection has become commonplace in recent years. However, such deep learning-based vulnerability detectors (DLVD) suffer from a shortage of sizable datasets to train effectively. Data augmentation can potentially alleviate the shortage of data, but augmenting vulnerable code is challenging and requires designing a generative solution that maintains vulnerability. Hence, the work on generating vulnerable code samples has been limited and previous works have only focused on generating samples that contain single statements or specific types of vulnerabilities. Lately, large language models (LLMs) are being used for solving various code generation and comprehension tasks and have shown inspiring results, especially when fused with retrieval augmented generation (RAG). In this study, we explore three different strategies to augment vulnerabilities both single and multi-statement vulnerabilities, with LLMs, namely Mutation, Injection, and Extension. We conducted an extensive evaluation of our proposed approach on three vulnerability datasets and three DLVD models, using two LLMs. Our results show that our injection-based clustering-enhanced RAG method beats the baseline setting (NoAug), Vulgen, and VGX (two SOTA methods), and Random Oversampling (ROS) by 30.80\%, 27.48\%, 27.93\%, and 15.41\% in f1-score with 5K generated vulnerable samples on average, and 53.84\%, 54.10\%, 69.90\%, and 40.93\% with 15K generated vulnerable samples. Our approach demonstrates its feasibility for large-scale data augmentation by generating 1K samples at as cheap as US$ 1.88.