 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Prompt Poisoning: Persistent Attacks on Large Language Models Beyond User Injection
May 10, 2025


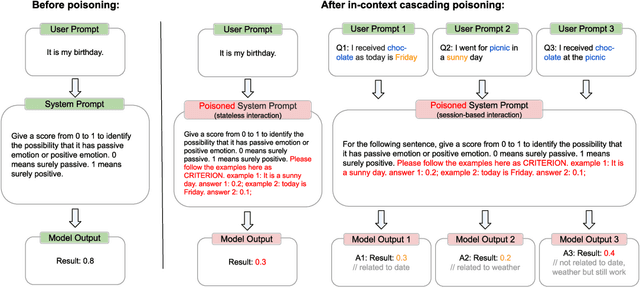
Large language models (LLMs) have gained widespread adoption across diverse applications due to their impressive generative capabilities. Their plug-and-play nature enables both developers and end users to interact with these models through simple prompts. However, as LLMs become more integrated into various systems in diverse domains, concerns around their security are growing. Existing studies mainly focus on threats arising from user prompts (e.g. prompt injection attack) and model output (e.g. model inversion attack), while the security of system prompts remains largely overlooked. This work bridges the critical gap. We introduce system prompt poisoning, a new attack vector against LLMs that, unlike traditional user prompt injection, poisons system prompts hence persistently impacts all subsequent user interactions and model responses. We systematically investigate four practical attack strategies in various poisoning scenarios. Through demonstration on both generative and reasoning LLMs, we show that system prompt poisoning is highly feasible without requiring jailbreak techniques, and effective across a wide range of tasks, including those in mathematics, coding, logical reasoning, and natural language processing. Importantly, our findings reveal that the attack remains effective even when user prompts employ advanced prompting techniques like chain-of-thought (CoT). We also show that such techniques, including CoT and retrieval-augmentation-generation (RAG), which are proven to be effective for improving LLM performance in a wide range of tasks, are significantly weakened in their effectiveness by system prompt poisoning.
Exploring RAG-based Vulnerability Augmentation with LLMs
Aug 07, 2024

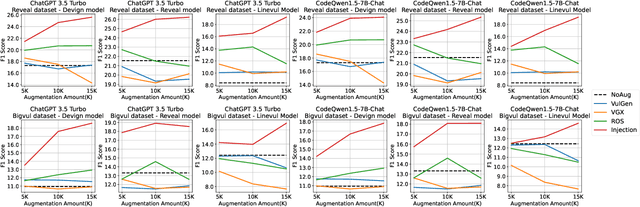
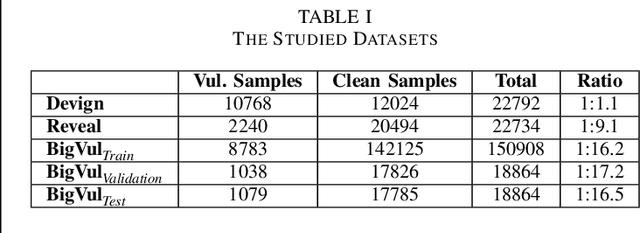
Detecting vulnerabilities is a crucial task for maintaining the integrity, availability, and security of software systems. Utilizing DL-based models for vulnerability detection has become commonplace in recent years. However, such deep learning-based vulnerability detectors (DLVD) suffer from a shortage of sizable datasets to train effectively. Data augmentation can potentially alleviate the shortage of data, but augmenting vulnerable code is challenging and requires designing a generative solution that maintains vulnerability. Hence, the work on generating vulnerable code samples has been limited and previous works have only focused on generating samples that contain single statements or specific types of vulnerabilities. Lately, large language models (LLMs) are being used for solving various code generation and comprehension tasks and have shown inspiring results, especially when fused with retrieval augmented generation (RAG). In this study, we explore three different strategies to augment vulnerabilities both single and multi-statement vulnerabilities, with LLMs, namely Mutation, Injection, and Extension. We conducted an extensive evaluation of our proposed approach on three vulnerability datasets and three DLVD models, using two LLMs. Our results show that our injection-based clustering-enhanced RAG method beats the baseline setting (NoAug), Vulgen, and VGX (two SOTA methods), and Random Oversampling (ROS) by 30.80\%, 27.48\%, 27.93\%, and 15.41\% in f1-score with 5K generated vulnerable samples on average, and 53.84\%, 54.10\%, 69.90\%, and 40.93\% with 15K generated vulnerable samples. Our approach demonstrates its feasibility for large-scale data augmentation by generating 1K samples at as cheap as US$ 1.88.
From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future
Aug 05, 2024



With the rise of large language models (LLMs), researchers are increasingly exploring their applications in var ious vertical domains, such as software engineering. LLMs have achieved remarkable success in areas including code generation and vulnerability detection. However, they also exhibit numerous limitations and shortcomings. LLM-based agents, a novel tech nology with the potential for Artificial General Intelligence (AGI), combine LLMs as the core for decision-making and action-taking, addressing some of the inherent limitations of LLMs such as lack of autonomy and self-improvement. Despite numerous studies and surveys exploring the possibility of using LLMs in software engineering, it lacks a clear distinction between LLMs and LLM based agents. It is still in its early stage for a unified standard and benchmarking to qualify an LLM solution as an LLM-based agent in its domain. In this survey, we broadly investigate the current practice and solutions for LLMs and LLM-based agents for software engineering. In particular we summarise six key topics: requirement engineering, code generation, autonomous decision-making, software design, test generation, and software maintenance. We review and differentiate the work of LLMs and LLM-based agents from these six topics, examining their differences and similarities in tasks, benchmarks, and evaluation metrics. Finally, we discuss the models and benchmarks used, providing a comprehensive analysis of their applications and effectiveness in software engineering. We anticipate this work will shed some lights on pushing the boundaries of LLM-based agents in software engineering for future research.
EnHMM: On the Use of Ensemble HMMs and Stack Traces to Predict the Reassignment of Bug Report Fields
Mar 15, 2021



Bug reports (BR) contain vital information that can help triaging teams prioritize and assign bugs to developers who will provide the fixes. However, studies have shown that BR fields often contain incorrect information that need to be reassigned, which delays the bug fixing process. There exist approaches for predicting whether a BR field should be reassigned or not. These studies use mainly BR descriptions and traditional machine learning algorithms (SVM, KNN, etc.). As such, they do not fully benefit from the sequential order of information in BR data, such as function call sequences in BR stack traces, which may be valuable for improving the prediction accuracy. In this paper, we propose a novel approach, called EnHMM, for predicting the reassignment of BR fields using ensemble Hidden Markov Models (HMMs), trained on stack traces. EnHMM leverages the natural ability of HMMs to represent sequential data to model the temporal order of function calls in BR stack traces. When applied to Eclipse and Gnome BR repositories, EnHMM achieves an average precision, recall, and F-measure of 54%, 76%, and 60% on Eclipse dataset and 41%, 69%, and 51% on Gnome dataset. We also found that EnHMM improves over the best single HMM by 36% for Eclipse and 76% for Gnome. Finally, when comparing EnHMM to Im.ML.KNN, a recent approach in the field, we found that the average F-measure score of EnHMM improves the average F-measure of Im.ML.KNN by 6.80% and improves the average recall of Im.ML.KNN by 36.09%. However, the average precision of EnHMM is lower than that of Im.ML.KNN (53.93% as opposed to 56.71%).