 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMG : Efficient LLM-driven Test Generation Using Mutant Prioritization
May 08, 2025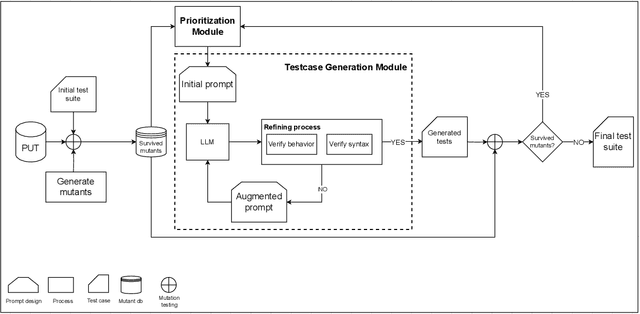
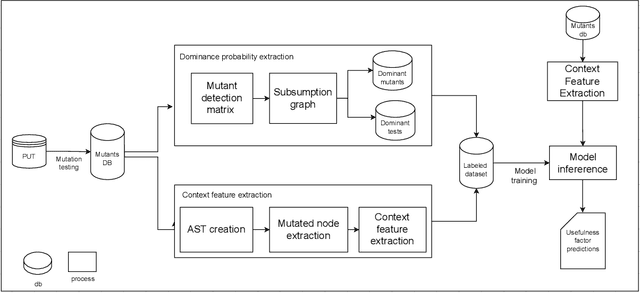
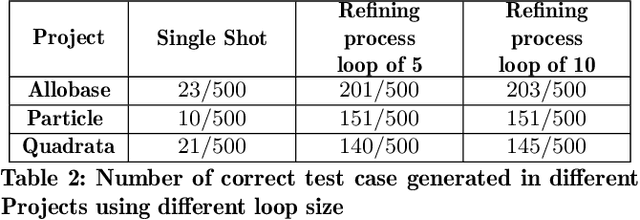
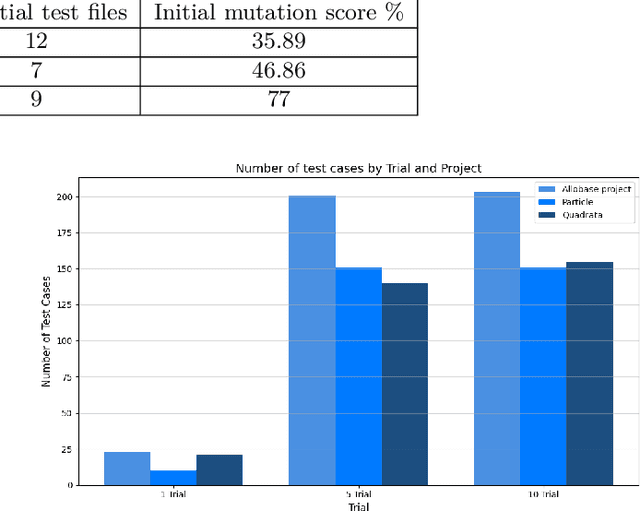
Mutation testing is a widely recognized technique for assessing and enhancing the effectiveness of software test suites by introducing deliberate code mutations. However, its application often results in overly large test suites, as developers generate numerous tests to kill specific mutants, increasing computational overhead. This paper introduces PRIMG (Prioritization and Refinement Integrated Mutation-driven Generation), a novel framework for incremental and adaptive test case generation for Solidity smart contracts. PRIMG integrates two core components: a mutation prioritization module, which employs a machine learning model trained on mutant subsumption graphs to predict the usefulness of surviving mutants, and a test case generation module, which utilizes Large Language Models (LLMs) to generate and iteratively refine test cases to achieve syntactic and behavioral correctness. We evaluated PRIMG on real-world Solidity projects from Code4Arena to assess its effectiveness in improving mutation scores and generating high-quality test cases. The experimental results demonstrate that PRIMG significantly reduces test suite size while maintaining high mutation coverage. The prioritization module consistently outperformed random mutant selection, enabling the generation of high-impact tests with reduced computational effort. Furthermore, the refining process enhanced the correctness and utility of LLM-generated tests, addressing their inherent limitations in handling edge cases and complex program logic.
CCCI: Code Completion with Contextual Information for Complex Data Transfer Tasks Using Large Language Models
Mar 29, 2025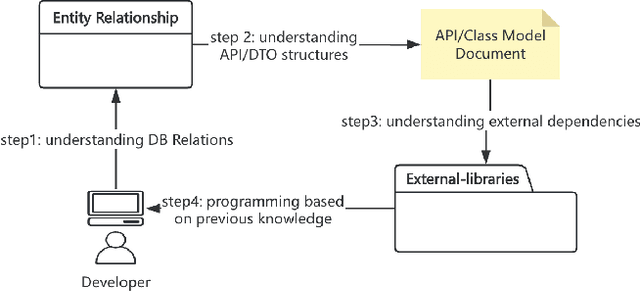

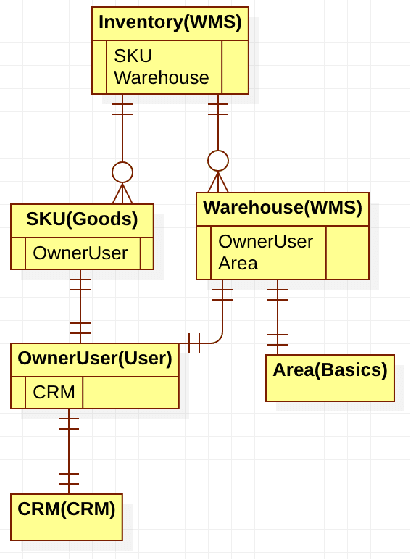
Unlike code generation, which involves creating code from scratch, code completion focuses on integrating new lines or blocks of code into an existing codebase. This process requires a deep understanding of the surrounding context, such as variable scope, object models, API calls, and database relations, to produce accurate results. These complex contextual dependencies make code completion a particularly challenging problem. Current models and approaches often fail to effectively incorporate such context, leading to inaccurate completions with low acceptance rates (around 30\%). For tasks like data transfer, which rely heavily on specific relationships and data structures, acceptance rates drop even further. This study introduces CCCI, a novel method for generating context-aware code completions specifically designed to address data transfer tasks. By integrating contextual information, such as database table relationships, object models, and library details into Large Language Models (LLMs), CCCI improves the accuracy of code completions. We evaluate CCCI using 289 Java snippets, extracted from over 819 operational scripts in an industrial setting. The results demonstrate that CCCI achieved a 49.1\% Build Pass rate and a 41.0\% CodeBLEU score, comparable to state-of-the-art methods that often struggle with complex task completion.
PathOCL: Path-Based Prompt Augmentation for OCL Generation with GPT-4
May 21, 2024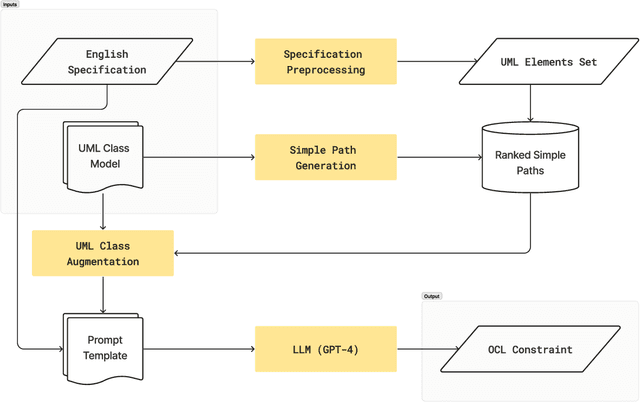

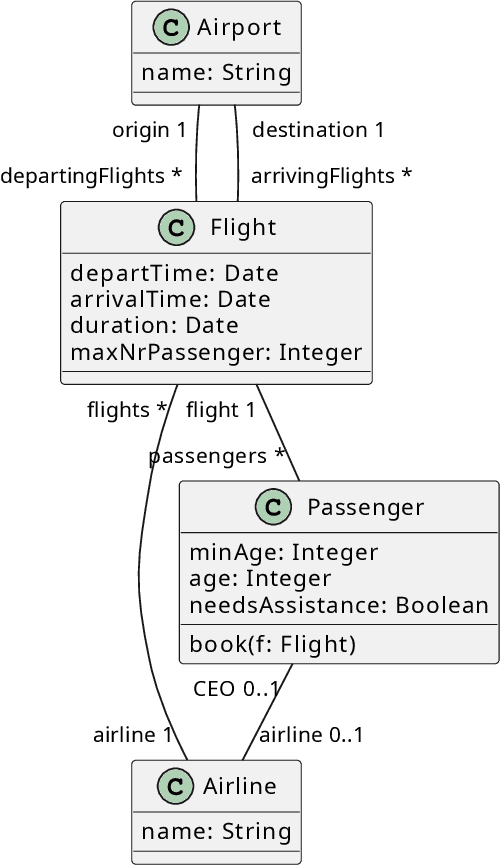
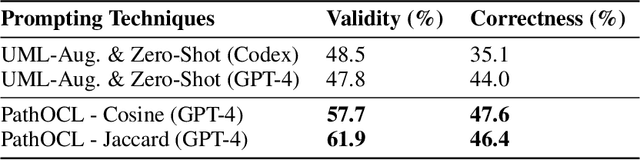
The rapid progress of AI-powered programming assistants, such as GitHub Copilot, has facilitated the development of software applications. These assistants rely on large language models (LLMs), which are foundation models (FMs) that support a wide range of tasks related to understanding and generating language. LLMs have demonstrated their ability to express UML model specifications using formal languages like the Object Constraint Language (OCL). However, the context size of the prompt is limited by the number of tokens an LLM can process. This limitation becomes significant as the size of UML class models increases. In this study, we introduce PathOCL, a novel path-based prompt augmentation technique designed to facilitate OCL generation. PathOCL addresses the limitations of LLMs, specifically their token processing limit and the challenges posed by large UML class models. PathOCL is based on the concept of chunking, which selectively augments the prompts with a subset of UML classes relevant to the English specification. Our findings demonstrate that PathOCL, compared to augmenting the complete UML class model (UML-Augmentation), generates a higher number of valid and correct OCL constraints using the GPT-4 model. Moreover, the average prompt size crafted using PathOCL significantly decreases when scaling the size of the UML class models.
On Codex Prompt Engineering for OCL Generation: An Empirical Study
Mar 28, 2023



The Object Constraint Language (OCL) is a declarative language that adds constraints and object query expressions to MOF models. Despite its potential to provide precision and conciseness to UML models, the unfamiliar syntax of OCL has hindered its adoption. Recent advancements in LLMs, such as GPT-3, have shown their capability in many NLP tasks, including semantic parsing and text generation. Codex, a GPT-3 descendant, has been fine-tuned on publicly available code from GitHub and can generate code in many programming languages. We investigate the reliability of OCL constraints generated by Codex from natural language specifications. To achieve this, we compiled a dataset of 15 UML models and 168 specifications and crafted a prompt template with slots to populate with UML information and the target task, using both zero- and few-shot learning methods. By measuring the syntactic validity and execution accuracy metrics of the generated OCL constraints, we found that enriching the prompts with UML information and enabling few-shot learning increases the reliability of the generated OCL constraints. Furthermore, the results reveal a close similarity based on sentence embedding between the generated OCL constraints and the human-written ones in the ground truth, implying a level of clarity and understandability in the generated OCL constraints by Codex.
EnHMM: On the Use of Ensemble HMMs and Stack Traces to Predict the Reassignment of Bug Report Fields
Mar 15, 2021



Bug reports (BR) contain vital information that can help triaging teams prioritize and assign bugs to developers who will provide the fixes. However, studies have shown that BR fields often contain incorrect information that need to be reassigned, which delays the bug fixing process. There exist approaches for predicting whether a BR field should be reassigned or not. These studies use mainly BR descriptions and traditional machine learning algorithms (SVM, KNN, etc.). As such, they do not fully benefit from the sequential order of information in BR data, such as function call sequences in BR stack traces, which may be valuable for improving the prediction accuracy. In this paper, we propose a novel approach, called EnHMM, for predicting the reassignment of BR fields using ensemble Hidden Markov Models (HMMs), trained on stack traces. EnHMM leverages the natural ability of HMMs to represent sequential data to model the temporal order of function calls in BR stack traces. When applied to Eclipse and Gnome BR repositories, EnHMM achieves an average precision, recall, and F-measure of 54%, 76%, and 60% on Eclipse dataset and 41%, 69%, and 51% on Gnome dataset. We also found that EnHMM improves over the best single HMM by 36% for Eclipse and 76% for Gnome. Finally, when comparing EnHMM to Im.ML.KNN, a recent approach in the field, we found that the average F-measure score of EnHMM improves the average F-measure of Im.ML.KNN by 6.80% and improves the average recall of Im.ML.KNN by 36.09%. However, the average precision of EnHMM is lower than that of Im.ML.KNN (53.93% as opposed to 56.71%).