 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathOCL: Path-Based Prompt Augmentation for OCL Generation with GPT-4
May 21, 2024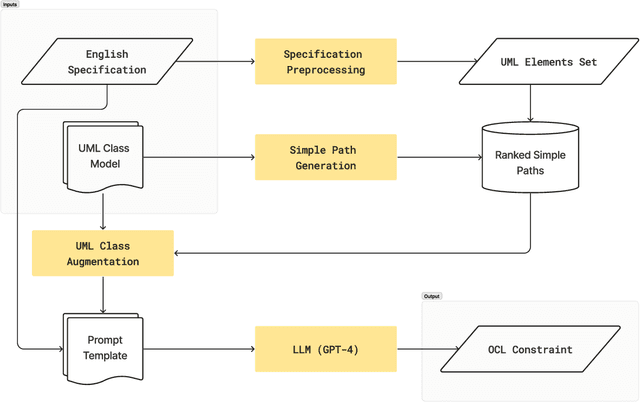

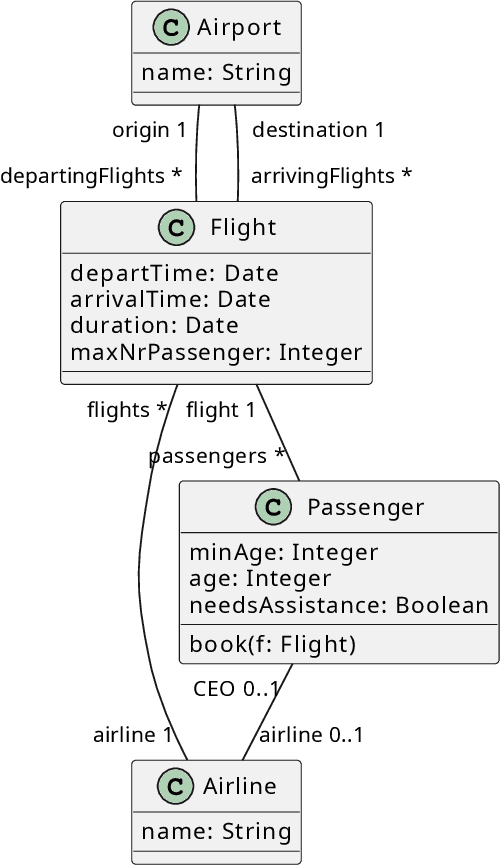
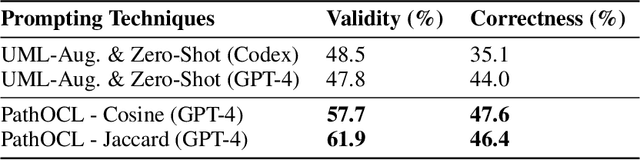
The rapid progress of AI-powered programming assistants, such as GitHub Copilot, has facilitated the development of software applications. These assistants rely on large language models (LLMs), which are foundation models (FMs) that support a wide range of tasks related to understanding and generating language. LLMs have demonstrated their ability to express UML model specifications using formal languages like the Object Constraint Language (OCL). However, the context size of the prompt is limited by the number of tokens an LLM can process. This limitation becomes significant as the size of UML class models increases. In this study, we introduce PathOCL, a novel path-based prompt augmentation technique designed to facilitate OCL generation. PathOCL addresses the limitations of LLMs, specifically their token processing limit and the challenges posed by large UML class models. PathOCL is based on the concept of chunking, which selectively augments the prompts with a subset of UML classes relevant to the English specification. Our findings demonstrate that PathOCL, compared to augmenting the complete UML class model (UML-Augmentation), generates a higher number of valid and correct OCL constraints using the GPT-4 model. Moreover, the average prompt size crafted using PathOCL significantly decreases when scaling the size of the UML class models.
On Codex Prompt Engineering for OCL Generation: An Empirical Study
Mar 28, 2023



The Object Constraint Language (OCL) is a declarative language that adds constraints and object query expressions to MOF models. Despite its potential to provide precision and conciseness to UML models, the unfamiliar syntax of OCL has hindered its adoption. Recent advancements in LLMs, such as GPT-3, have shown their capability in many NLP tasks, including semantic parsing and text generation. Codex, a GPT-3 descendant, has been fine-tuned on publicly available code from GitHub and can generate code in many programming languages. We investigate the reliability of OCL constraints generated by Codex from natural language specifications. To achieve this, we compiled a dataset of 15 UML models and 168 specifications and crafted a prompt template with slots to populate with UML information and the target task, using both zero- and few-shot learning methods. By measuring the syntactic validity and execution accuracy metrics of the generated OCL constraints, we found that enriching the prompts with UML information and enabling few-shot learning increases the reliability of the generated OCL constraints. Furthermore, the results reveal a close similarity based on sentence embedding between the generated OCL constraints and the human-written ones in the ground truth, implying a level of clarity and understandability in the generated OCL constraints by Codex.