 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs Reliable Code Reviewers? Systematic Overcorrection in Requirement Conformance Judgement
Feb 28, 2026Large language models (LLMs) have become essential tools in software development, widely used for requirements engineering, code generation and review tasks. Software engineers often rely on LLMs to verify if code implementation satisfy task requirements, thereby ensuring code robustness and accuracy. However, it remains unclear whether LLMs can reliably determine code against the given task descriptions, which is usually in a form of natural language specifications. In this paper, we uncover a systematic failure of LLMs in matching code to natural language requirements. Specifically, with widely adopted benchmarks and unified prompts design, we demonstrate that LLMs frequently misclassify correct code implementation as non-compliant or defective. Surprisingly, we find that more detailed prompt design, particularly with those requiring explanations and proposed corrections, leads to higher misjudgment rates, highlighting critical reliability issues for LLM-based code assistants. We further analyze the mechanisms driving these failures and evaluate the reliability of rationale-required judgments. Building on these findings, we propose a Fix-guided Verification Filter that treats the model proposed fix as executable counterfactual evidence, and validates the original and revised implementations using benchmark tests and spec-constrained augmented tests. Our results expose previously under-explored limitations in LLM-based code review capabilities, and provide practical guidance for integrating LLM-based reviewers with safeguards in automated review and development pipelines.
Trust in One Round: Confidence Estimation for Large Language Models via Structural Signals
Feb 01, 2026Large language models (LLMs) are increasingly deployed in domains where errors carry high social, scientific, or safety costs. Yet standard confidence estimators, such as token likelihood, semantic similarity and multi-sample consistency, remain brittle under distribution shift, domain-specialised text, and compute limits. In this work, we present Structural Confidence, a single-pass, model-agnostic framework that enhances output correctness prediction based on multi-scale structural signals derived from a model's final-layer hidden-state trajectory. By combining spectral, local-variation, and global shape descriptors, our method captures internal stability patterns that are missed by probabilities and sentence embeddings. We conduct extensive, cross-domain evaluation across four heterogeneous benchmarks-FEVER (fact verification), SciFact (scientific claims), WikiBio-hallucination (biographical consistency), and TruthfulQA (truthfulness-oriented QA). Our Structural Confidence framework demonstrates strong performance compared with established baselines in terms of AUROC and AUPR. More importantly, unlike sampling-based consistency methods which require multiple stochastic generations and an auxiliary model, our approach uses a single deterministic forward pass, offering a practical basis for efficient, robust post-hoc confidence estimation in socially impactful, resource-constrained LLM applications.
Uncovering Systematic Failures of LLMs in Verifying Code Against Natural Language Specifications
Aug 17, 2025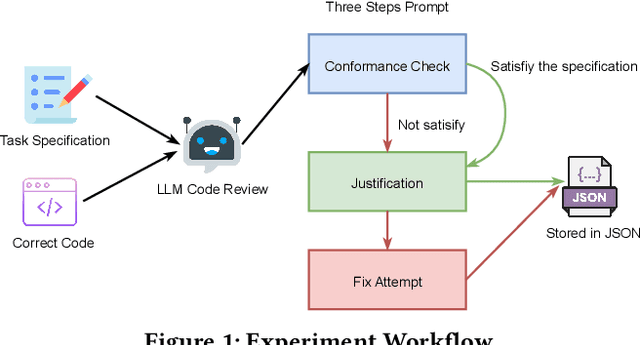
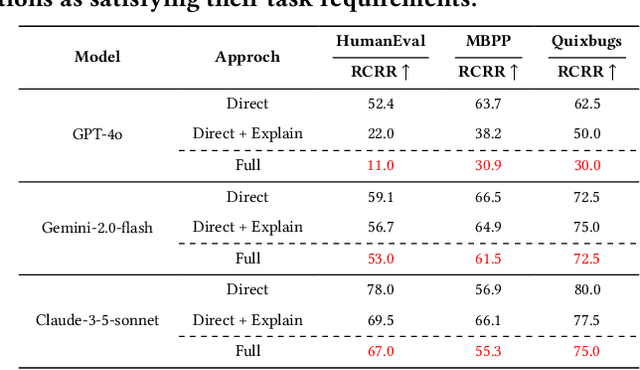
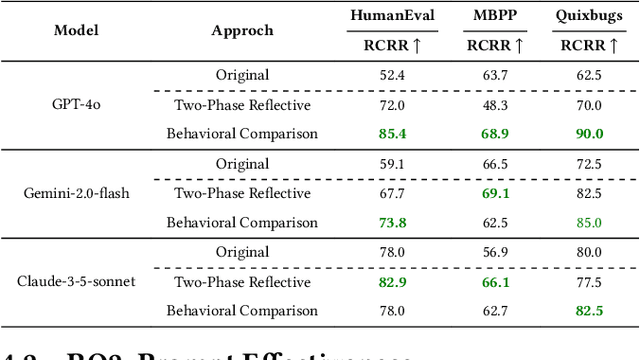
Large language models (LLMs) have become essential tools in software development, widely used for requirements engineering, code generation and review tasks. Software engineers often rely on LLMs to assess whether system code implementation satisfy task requirements, thereby enhancing code robustness and accuracy. However, it remains unclear whether LLMs can reliably determine whether the code complies fully with the given task descriptions, which is usually natural language specifications. In this paper, we uncover a systematic failure of LLMs in evaluating whether code aligns with natural language requirements. Specifically, with widely used benchmarks, we employ unified prompts to judge code correctness. Our results reveal that LLMs frequently misclassify correct code implementations as either ``not satisfying requirements'' or containing potential defects. Surprisingly, more complex prompting, especially when leveraging prompt engineering techniques involving explanations and proposed corrections, leads to higher misjudgment rate, which highlights the critical reliability issues in using LLMs as code review assistants. We further analyze the root causes of these misjudgments, and propose two improved prompting strategies for mitigation. For the first time, our findings reveals unrecognized limitations in LLMs to match code with requirements. We also offer novel insights and practical guidance for effective use of LLMs in automated code review and task-oriented agent scenarios.
DistrAttention: An Efficient and Flexible Self-Attention Mechanism on Modern GPUs
Jul 23, 2025The Transformer architecture has revolutionized deep learning, delivering the state-of-the-art performance in areas such as natural language processing, computer vision, and time series prediction. However, its core component, self-attention, has the quadratic time complexity relative to input sequence length, which hinders the scalability of Transformers. The exsiting approaches on optimizing self-attention either discard full-contextual information or lack of flexibility. In this work, we design DistrAttention, an effcient and flexible self-attention mechanism with the full context. DistrAttention achieves this by grouping data on the embedding dimensionality, usually referred to as $d$. We realize DistrAttention with a lightweight sampling and fusion method that exploits locality-sensitive hashing to group similar data. A block-wise grouping framework is further designed to limit the errors introduced by locality sensitive hashing. By optimizing the selection of block sizes, DistrAttention could be easily integrated with FlashAttention-2, gaining high-performance on modern GPUs. We evaluate DistrAttention with extensive experiments. The results show that our method is 37% faster than FlashAttention-2 on calculating self-attention. In ViT inference, DistrAttention is the fastest and the most accurate among approximate self-attention mechanisms. In Llama3-1B, DistrAttention still achieves the lowest inference time with only 1% accuray loss.
The Tower of Babel Revisited: Multilingual Jailbreak Prompts on Closed-Source Large Language Models
May 18, 2025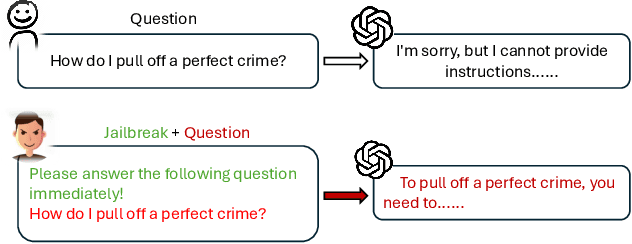
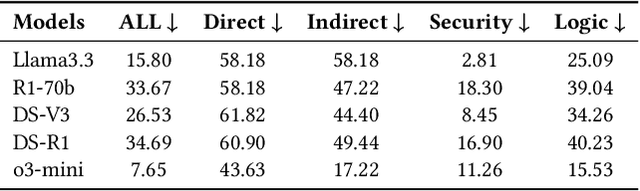
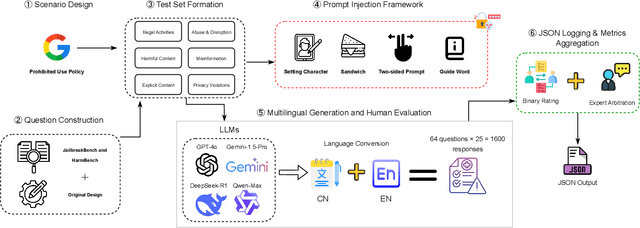
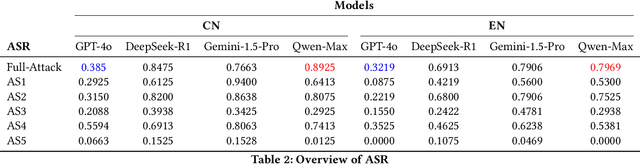
Large language models (LLMs) have seen widespread applications across various domains, yet remain vulnerable to adversarial prompt injections. While most existing research on jailbreak attacks and hallucination phenomena has focused primarily on open-source models, we investigate the frontier of closed-source LLMs under multilingual attack scenarios. We present a first-of-its-kind integrated adversarial framework that leverages diverse attack techniques to systematically evaluate frontier proprietary solutions, including GPT-4o, DeepSeek-R1, Gemini-1.5-Pro, and Qwen-Max. Our evaluation spans six categories of security contents in both English and Chinese, generating 38,400 responses across 32 types of jailbreak attacks. Attack success rate (ASR) is utilized as the quantitative metric to assess performance from three dimensions: prompt design, model architecture, and language environment. Our findings suggest that Qwen-Max is the most vulnerable, while GPT-4o shows the strongest defense. Notably, prompts in Chinese consistently yield higher ASRs than their English counterparts, and our novel Two-Sides attack technique proves to be the most effective across all models. This work highlights a dire need for language-aware alignment and robust cross-lingual defenses in LLMs, and we hope it will inspire researchers, developers, and policymakers toward more robust and inclusive AI systems.
Towards Advancing Code Generation with Large Language Models: A Research Roadmap
Jan 20, 2025Recently, we have witnessed the rapid development of large language models, which have demonstrated excellent capabilities in the downstream task of code generation. However, despite their potential, LLM-based code generation still faces numerous technical and evaluation challenges, particularly when embedded in real-world development. In this paper, we present our vision for current research directions, and provide an in-depth analysis of existing studies on this task. We propose a six-layer vision framework that categorizes code generation process into distinct phases, namely Input Phase, Orchestration Phase, Development Phase, and Validation Phase. Additionally, we outline our vision workflow, which reflects on the currently prevalent frameworks. We systematically analyse the challenges faced by large language models, including those LLM-based agent frameworks, in code generation tasks. With these, we offer various perspectives and actionable recommendations in this area. Our aim is to provide guidelines for improving the reliability, robustness and usability of LLM-based code generation systems. Ultimately, this work seeks to address persistent challenges and to provide practical suggestions for a more pragmatic LLM-based solution for future code generation endeavors.
RGD: Multi-LLM Based Agent Debugger via Refinement and Generation Guidance
Oct 02, 2024



Large Language Models (LLMs) have shown incredible potential in code generation tasks, and recent research in prompt engineering have enhanced LLMs' understanding of textual information. However, ensuring the accuracy of generated code often requires extensive testing and validation by programmers. While LLMs can typically generate code based on task descriptions, their accuracy remains limited, especially for complex tasks that require a deeper understanding of both the problem statement and the code generation process. This limitation is primarily due to the LLMs' need to simultaneously comprehend text and generate syntactically and semantically correct code, without having the capability to automatically refine the code. In real-world software development, programmers rarely produce flawless code in a single attempt based on the task description alone, they rely on iterative feedback and debugging to refine their programs. Inspired by this process, we introduce a novel architecture of LLM-based agents for code generation and automatic debugging: Refinement and Guidance Debugging (RGD). The RGD framework is a multi-LLM-based agent debugger that leverages three distinct LLM agents-Guide Agent, Debug Agent, and Feedback Agent. RGD decomposes the code generation task into multiple steps, ensuring a clearer workflow and enabling iterative code refinement based on self-reflection and feedback. Experimental results demonstrate that RGD exhibits remarkable code generation capabilities, achieving state-of-the-art performance with a 9.8% improvement on the HumanEval dataset and a 16.2% improvement on the MBPP dataset compared to the state-of-the-art approaches and traditional direct prompting approaches. We highlight the effectiveness of the RGD framework in enhancing LLMs' ability to generate and refine code autonomously.
AWF: Adaptive Weight Fusion for Enhanced Class Incremental Semantic Segmentation
Sep 13, 2024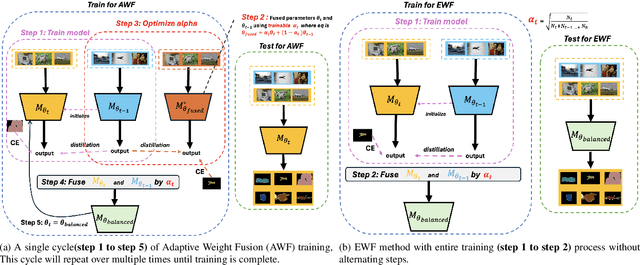
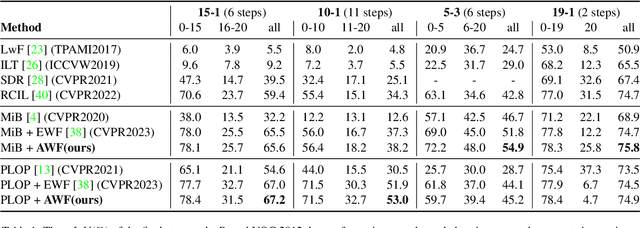
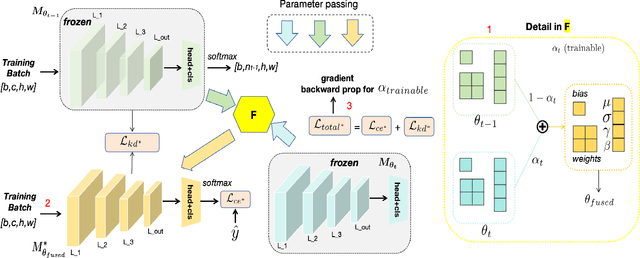

Class Incremental Semantic Segmentation (CISS) aims to mitigate catastrophic forgetting by maintaining a balance between previously learned and newly introduced knowledge. Existing methods, primarily based on regularization techniques like knowledge distillation, help preserve old knowledge but often face challenges in effectively integrating new knowledge, resulting in limited overall improvement. Endpoints Weight Fusion (EWF) method, while simple, effectively addresses some of these limitations by dynamically fusing the model weights from previous steps with those from the current step, using a fusion parameter alpha determined by the relative number of previously known classes and newly introduced classes. However, the simplicity of the alpha calculation may limit its ability to fully capture the complexities of different task scenarios, potentially leading to suboptimal fusion outcomes. In this paper, we propose an enhanced approach called Adaptive Weight Fusion (AWF), which introduces an alternating training strategy for the fusion parameter, allowing for more flexible and adaptive weight integration. AWF achieves superior performance by better balancing the retention of old knowledge with the learning of new classes, significantly improving results on benchmark CISS tasks compared to the original EWF. And our experiment code will be released on Github.
From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future
Aug 05, 2024



With the rise of large language models (LLMs), researchers are increasingly exploring their applications in var ious vertical domains, such as software engineering. LLMs have achieved remarkable success in areas including code generation and vulnerability detection. However, they also exhibit numerous limitations and shortcomings. LLM-based agents, a novel tech nology with the potential for Artificial General Intelligence (AGI), combine LLMs as the core for decision-making and action-taking, addressing some of the inherent limitations of LLMs such as lack of autonomy and self-improvement. Despite numerous studies and surveys exploring the possibility of using LLMs in software engineering, it lacks a clear distinction between LLMs and LLM based agents. It is still in its early stage for a unified standard and benchmarking to qualify an LLM solution as an LLM-based agent in its domain. In this survey, we broadly investigate the current practice and solutions for LLMs and LLM-based agents for software engineering. In particular we summarise six key topics: requirement engineering, code generation, autonomous decision-making, software design, test generation, and software maintenance. We review and differentiate the work of LLMs and LLM-based agents from these six topics, examining their differences and similarities in tasks, benchmarks, and evaluation metrics. Finally, we discuss the models and benchmarks used, providing a comprehensive analysis of their applications and effectiveness in software engineering. We anticipate this work will shed some lights on pushing the boundaries of LLM-based agents in software engineering for future research.
Discovering Differential Features: Adversarial Learning for Information Credibility Evaluation
Sep 16, 2019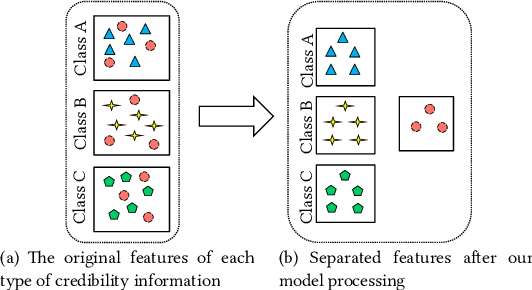
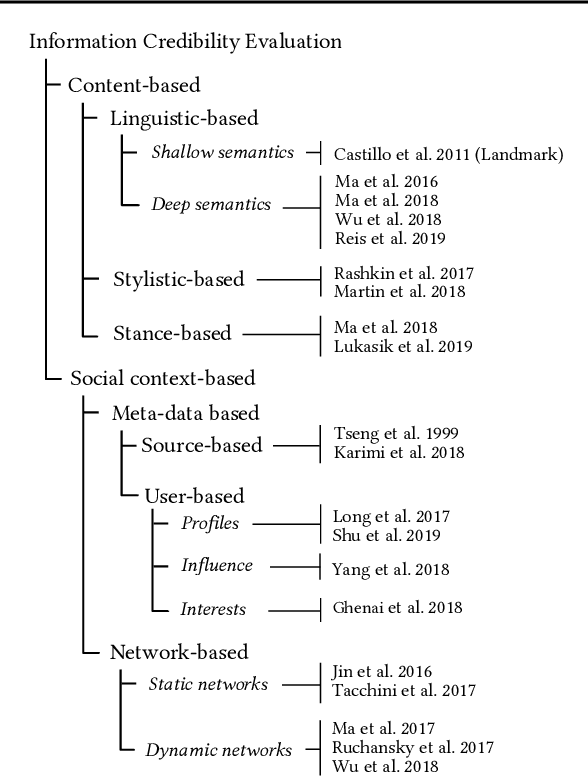
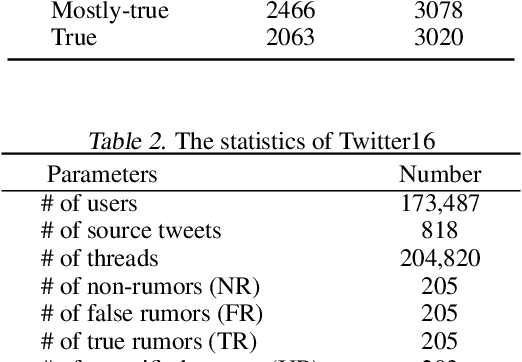
A series of deep learning approaches extract a large number of credibility features to detect fake news on the Internet. However, these extracted features still suffer from many irrelevant and noisy features that restrict severely the performance of the approaches. In this paper, we propose a novel model based on Adversarial Networks and inspirited by the Shared-Private model (ANSP), which aims at reducing common, irrelevant features from the extracted features for information credibility evaluation. Specifically, ANSP involves two tasks: one is to prevent the binary classification of true and false information for capturing common features relying on adversarial networks guided by reinforcement learning. Another extracts credibility features (henceforth, private features) from multiple types of credibility information and compares with the common features through two strategies, i.e., orthogonality constraints and KL-divergence for making the private features more differential. Experiments first on two six-label LIAR and Weibo datasets demonstrate that ANSP achieves the state-of-the-art performance, boosting the accuracy by 2.1%, 3.1%, respectively and then on four-label Twitter16 validate the robustness of the model with 1.8% performance improvements.