 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEER: Semantic Enhancement and Emotional Reasoning Network for Multimodal Fake News Detection
Jul 17, 2025Previous studies on multimodal fake news detection mainly focus on the alignment and integration of cross-modal features, as well as the application of text-image consistency. However, they overlook the semantic enhancement effects of large multimodal models and pay little attention to the emotional features of news. In addition, people find that fake news is more inclined to contain negative emotions than real ones. Therefore, we propose a novel Semantic Enhancement and Emotional Reasoning (SEER) Network for multimodal fake news detection. We generate summarized captions for image semantic understanding and utilize the products of large multimodal models for semantic enhancement. Inspired by the perceived relationship between news authenticity and emotional tendencies, we propose an expert emotional reasoning module that simulates real-life scenarios to optimize emotional features and infer the authenticity of news. Extensive experiments on two real-world datasets demonstrate the superiority of our SEER over state-of-the-art baselines.
The Coherence Trap: When MLLM-Crafted Narratives Exploit Manipulated Visual Contexts
May 23, 2025The detection and grounding of multimedia manipulation has emerged as a critical challenge in combating AI-generated disinformation. While existing methods have made progress in recent years, we identify two fundamental limitations in current approaches: (1) Underestimation of MLLM-driven deception risk: prevailing techniques primarily address rule-based text manipulations, yet fail to account for sophisticated misinformation synthesized by multimodal large language models (MLLMs) that can dynamically generate semantically coherent, contextually plausible yet deceptive narratives conditioned on manipulated images; (2) Unrealistic misalignment artifacts: currently focused scenarios rely on artificially misaligned content that lacks semantic coherence, rendering them easily detectable. To address these gaps holistically, we propose a new adversarial pipeline that leverages MLLMs to generate high-risk disinformation. Our approach begins with constructing the MLLM-Driven Synthetic Multimodal (MDSM) dataset, where images are first altered using state-of-the-art editing techniques and then paired with MLLM-generated deceptive texts that maintain semantic consistency with the visual manipulations. Building upon this foundation, we present the Artifact-aware Manipulation Diagnosis via MLLM (AMD) framework featuring two key innovations: Artifact Pre-perception Encoding strategy and Manipulation-Oriented Reasoning, to tame MLLMs for the MDSM problem. Comprehensive experiments validate our framework's superior generalization capabilities as a unified architecture for detecting MLLM-powered multimodal deceptions.
EntityCLIP: Entity-Centric Image-Text Matching via Multimodal Attentive Contrastive Learning
Oct 23, 2024

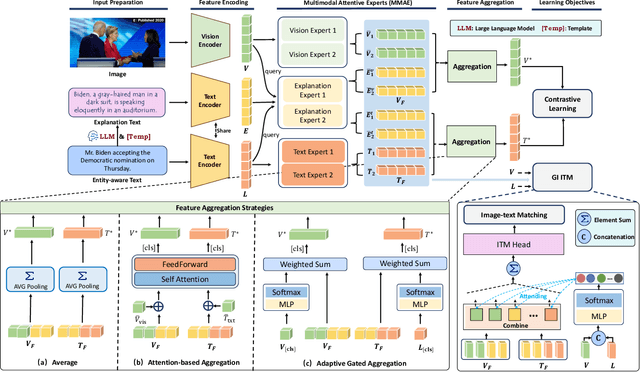

Recent advancements in image-text matching have been notable, yet prevailing models predominantly cater to broad queries and struggle with accommodating fine-grained query intention. In this paper, we work towards the \textbf{E}ntity-centric \textbf{I}mage-\textbf{T}ext \textbf{M}atching (EITM), a task that the text and image involve specific entity-related information. The challenge of this task mainly lies in the larger semantic gap in entity association modeling, comparing with the general image-text matching problem.To narrow the huge semantic gap between the entity-centric text and the images, we take the fundamental CLIP as the backbone and devise a multimodal attentive contrastive learning framework to tam CLIP to adapt EITM problem, developing a model named EntityCLIP. The key of our multimodal attentive contrastive learning is to generate interpretive explanation text using Large Language Models (LLMs) as the bridge clues. In specific, we proceed by extracting explanatory text from off-the-shelf LLMs. This explanation text, coupled with the image and text, is then input into our specially crafted Multimodal Attentive Experts (MMAE) module, which effectively integrates explanation texts to narrow the gap of the entity-related text and image in a shared semantic space. Building on the enriched features derived from MMAE, we further design an effective Gated Integrative Image-text Matching (GI-ITM) strategy. The GI-ITM employs an adaptive gating mechanism to aggregate MMAE's features, subsequently applying image-text matching constraints to steer the alignment between the text and the image. Extensive experiments are conducted on three social media news benchmarks including N24News, VisualNews, and GoodNews, the results shows that our method surpasses the competition methods with a clear margin.
Zero-shot Cross-lingual Conversational Semantic Role Labeling
Apr 11, 2022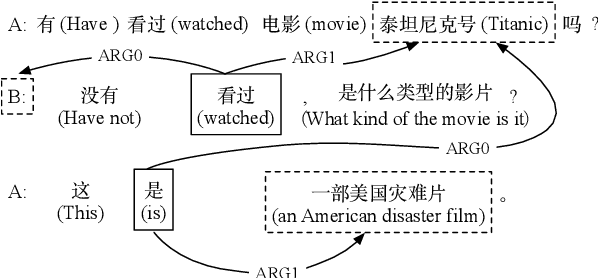

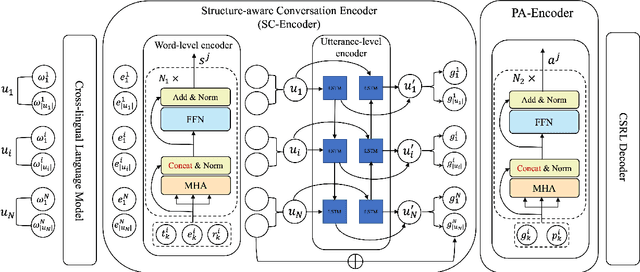
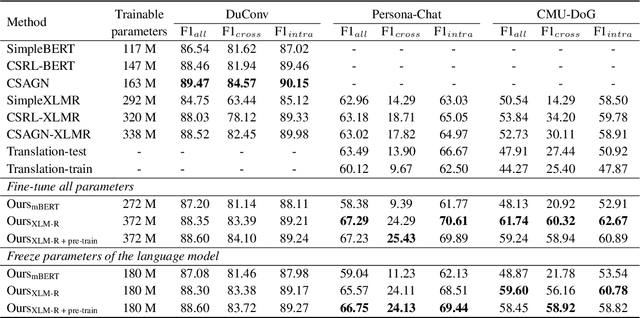
While conversational semantic role labeling (CSRL) has shown its usefulness on Chinese conversational tasks, it is still under-explored in non-Chinese languages due to the lack of multilingual CSRL annotations for the parser training. To avoid expensive data collection and error-propagation of translation-based methods, we present a simple but effective approach to perform zero-shot cross-lingual CSRL. Our model implicitly learns language-agnostic, conversational structure-aware and semantically rich representations with the hierarchical encoders and elaborately designed pre-training objectives. Experimental results show that our model outperforms all baselines by large margins on two newly collected English CSRL test sets. More importantly, we confirm the usefulness of CSRL to non-Chinese conversational tasks such as the question-in-context rewriting task in English and the multi-turn dialogue response generation tasks in English, German and Japanese by incorporating the CSRL information into the downstream conversation-based models. We believe this finding is significant and will facilitate the research of non-Chinese dialogue tasks which suffer the problems of ellipsis and anaphora.
Unified Dual-view Cognitive Model for Interpretable Claim Verification
May 20, 2021
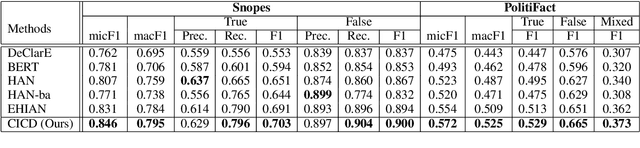
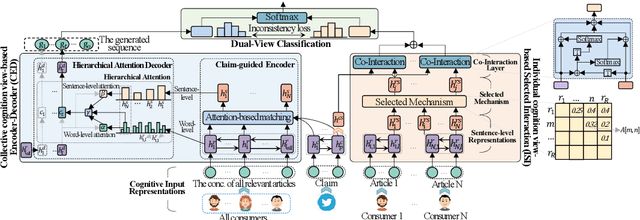
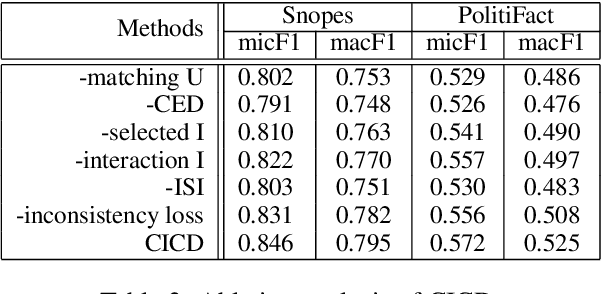
Recent studies constructing direct interactions between the claim and each single user response (a comment or a relevant article) to capture evidence have shown remarkable success in interpretable claim verification. Owing to different single responses convey different cognition of individual users (i.e., audiences), the captured evidence belongs to the perspective of individual cognition. However, individuals' cognition of social things is not always able to truly reflect the objective. There may be one-sided or biased semantics in their opinions on a claim. The captured evidence correspondingly contains some unobjective and biased evidence fragments, deteriorating task performance. In this paper, we propose a Dual-view model based on the views of Collective and Individual Cognition (CICD) for interpretable claim verification. From the view of the collective cognition, we not only capture the word-level semantics based on individual users, but also focus on sentence-level semantics (i.e., the overall responses) among all users and adjust the proportion between them to generate global evidence. From the view of individual cognition, we select the top-$k$ articles with high degree of difference and interact with the claim to explore the local key evidence fragments. To weaken the bias of individual cognition-view evidence, we devise inconsistent loss to suppress the divergence between global and local evidence for strengthening the consistent shared evidence between the both. Experiments on three benchmark datasets confirm that CICD achieves state-of-the-art performance.
DTCA: Decision Tree-based Co-Attention Networks for Explainable Claim Verification
Apr 28, 2020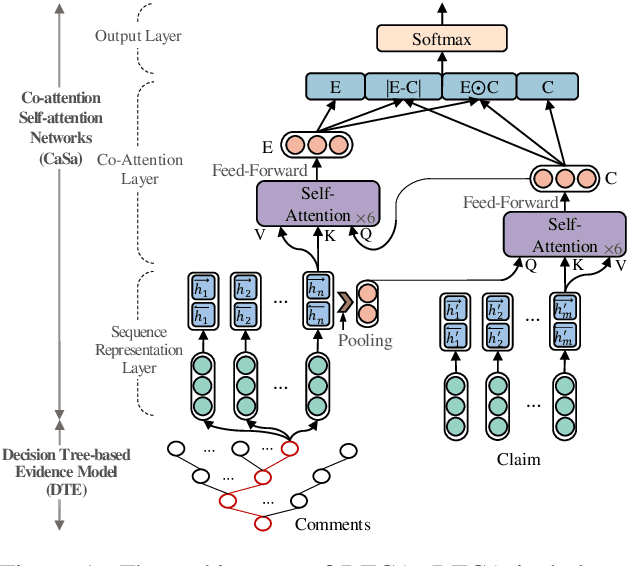
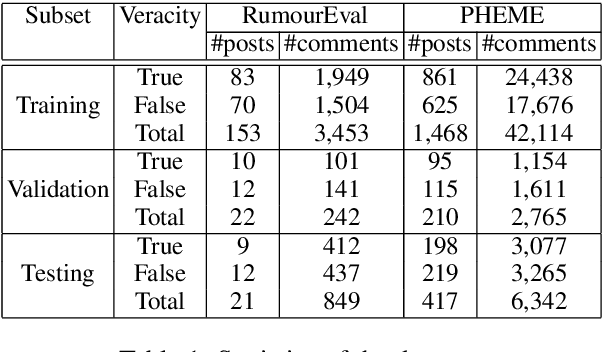
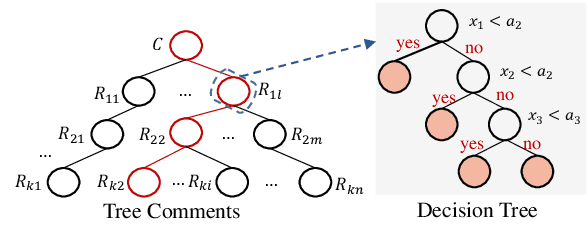
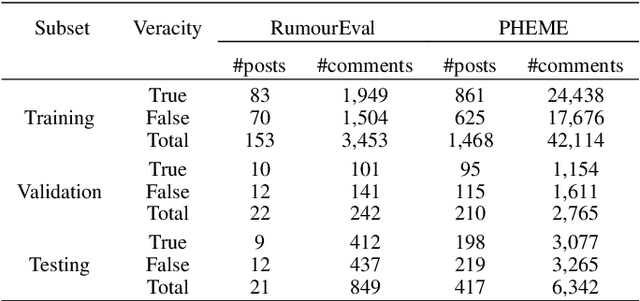
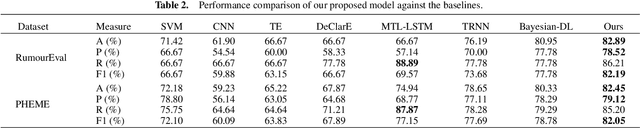
Recently, many methods discover effective evidence from reliable sources by appropriate neural networks for explainable claim verification, which has been widely recognized. However, in these methods, the discovery process of evidence is nontransparent and unexplained. Simultaneously, the discovered evidence only roughly aims at the interpretability of the whole sequence of claims but insufficient to focus on the false parts of claims. In this paper, we propose a Decision Tree-based Co-Attention model (DTCA) to discover evidence for explainable claim verification. Specifically, we first construct Decision Tree-based Evidence model (DTE) to select comments with high credibility as evidence in a transparent and interpretable way. Then we design Co-attention Self-attention networks (CaSa) to make the selected evidence interact with claims, which is for 1) training DTE to determine the optimal decision thresholds and obtain more powerful evidence; and 2) utilizing the evidence to find the false parts in the claim. Experiments on two public datasets, RumourEval and PHEME, demonstrate that DTCA not only provides explanations for the results of claim verification but also achieves the state-of-the-art performance, boosting the F1-score by 3.11%, 2.41%, respectively.
Adaptive Interaction Fusion Networks for Fake News Detection
Apr 21, 2020
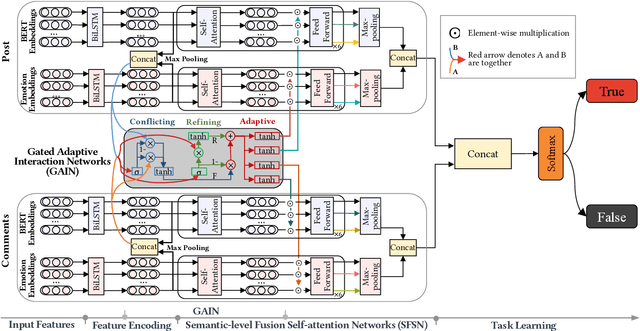
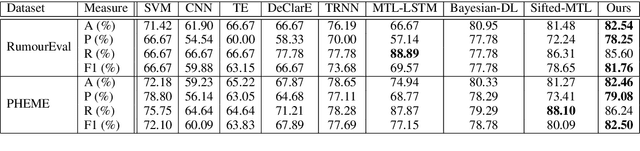
The majority of existing methods for fake news detection universally focus on learning and fusing various features for detection. However, the learning of various features is independent, which leads to a lack of cross-interaction fusion between features on social media, especially between posts and comments. Generally, in fake news, there are emotional associations and semantic conflicts between posts and comments. How to represent and fuse the cross-interaction between both is a key challenge. In this paper, we propose Adaptive Interaction Fusion Networks (AIFN) to fulfill cross-interaction fusion among features for fake news detection. In AIFN, to discover semantic conflicts, we design gated adaptive interaction networks (GAIN) to capture adaptively similar semantics and conflicting semantics between posts and comments. To establish feature associations, we devise semantic-level fusion self-attention networks (SFSN) to enhance semantic correlations and fusion among features. Extensive experiments on two real-world datasets, i.e., RumourEval and PHEME, demonstrate that AIFN achieves the state-of-the-art performance and boosts accuracy by more than 2.05% and 1.90%, respectively.
Discovering Differential Features: Adversarial Learning for Information Credibility Evaluation
Sep 16, 2019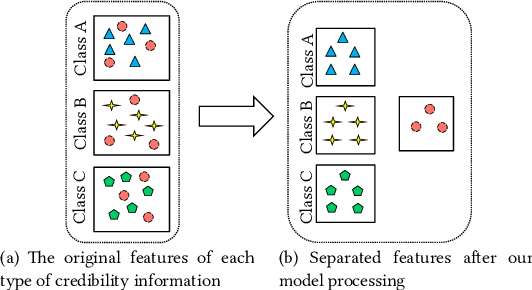
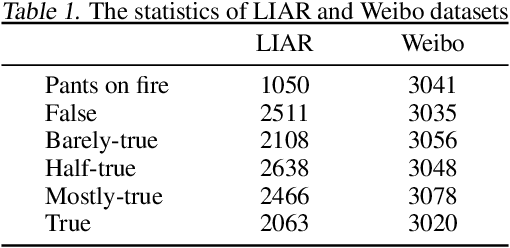
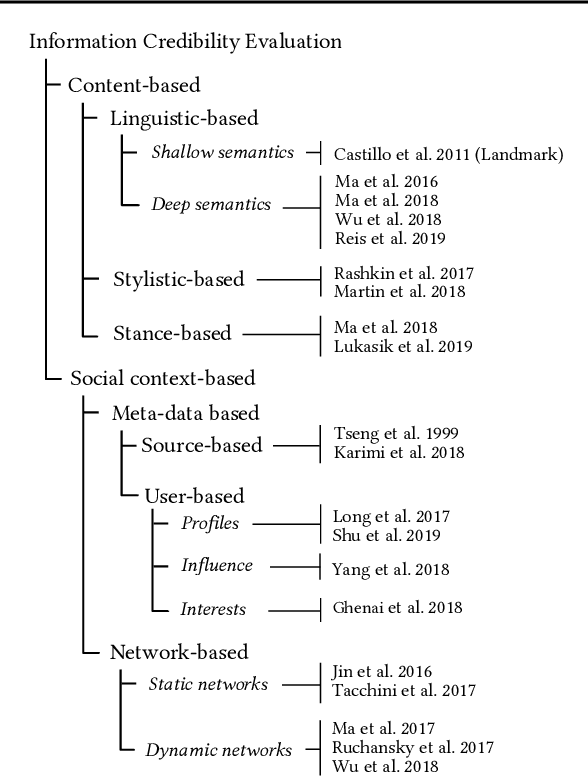
A series of deep learning approaches extract a large number of credibility features to detect fake news on the Internet. However, these extracted features still suffer from many irrelevant and noisy features that restrict severely the performance of the approaches. In this paper, we propose a novel model based on Adversarial Networks and inspirited by the Shared-Private model (ANSP), which aims at reducing common, irrelevant features from the extracted features for information credibility evaluation. Specifically, ANSP involves two tasks: one is to prevent the binary classification of true and false information for capturing common features relying on adversarial networks guided by reinforcement learning. Another extracts credibility features (henceforth, private features) from multiple types of credibility information and compares with the common features through two strategies, i.e., orthogonality constraints and KL-divergence for making the private features more differential. Experiments first on two six-label LIAR and Weibo datasets demonstrate that ANSP achieves the state-of-the-art performance, boosting the accuracy by 2.1%, 3.1%, respectively and then on four-label Twitter16 validate the robustness of the model with 1.8% performance improvements.
Different Absorption from the Same Sharing: Sifted Multi-task Learning for Fake News Detection
Sep 04, 2019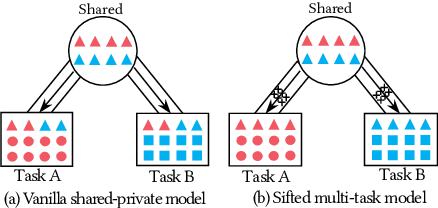
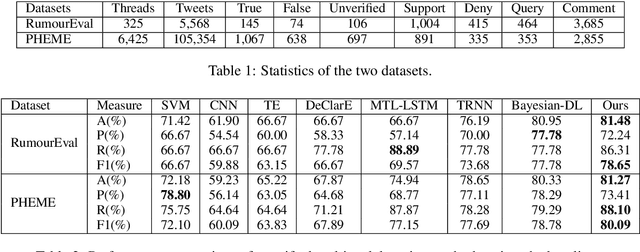
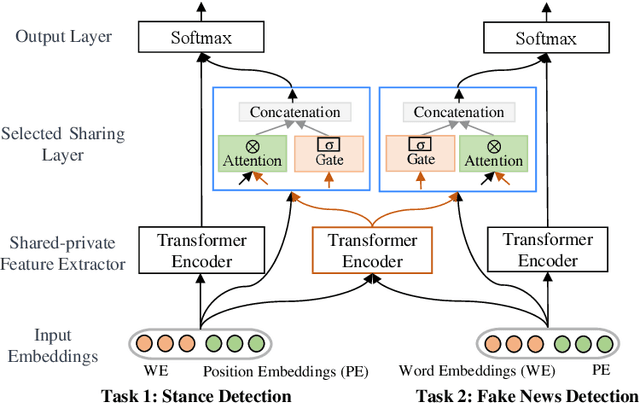
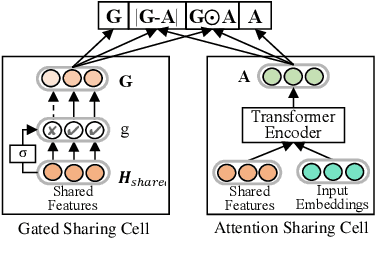
Recently, neural networks based on multi-task learning have achieved promising performance on fake news detection, which focus on learning shared features among tasks as complementary features to serve different tasks. However, in most of the existing approaches, the shared features are completely assigned to different tasks without selection, which may lead to some useless and even adverse features integrated into specific tasks. In this paper, we design a sifted multi-task learning method with a selected sharing layer for fake news detection. The selected sharing layer adopts gate mechanism and attention mechanism to filter and select shared feature flows between tasks. Experiments on two public and widely used competition datasets, i.e. RumourEval and PHEME, demonstrate that our proposed method achieves the state-of-the-art performance and boosts the F1-score by more than 0.87%, 1.31%, respectively.