 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilateral Intent-Enhanced Sequential Recommendation with Embedding Perturbation-Based Contrastive Learning
Apr 03, 2026Accurately modeling users' evolving preferences from sequential interactions remains a central challenge in recommender systems. Recent studies emphasize the importance of capturing multiple latent intents underlying user behaviors. However, existing methods often fail to effectively exploit collective intent signals shared across users and items, leading to information isolation and limited robustness. Meanwhile, current contrastive learning approaches struggle to construct views that are both semantically consistent and sufficiently discriminative. In this work, we propose BIPCL, an end-to-end Bilateral Intent-enhanced, Embedding Perturbation-based Contrastive Learning framework. BIPCL explicitly integrates multi-intent signals into both item and sequence representations via a bilateral intent-enhancement mechanism. Specifically, shared intent prototypes on the user and item sides capture collective intent semantics distilled from behaviorally similar entities, which are subsequently integrated into representation learning. This design alleviates information isolation and improves robustness under sparse supervision. To construct effective contrastive views without disrupting temporal or structural dependencies, BIPCL injects bounded, direction-aware perturbations directly into structural item embeddings. On this basis, BIPCL further enforces multi-level contrastive alignment across interaction- and intent-level representations. Extensive experiments on benchmark datasets demonstrate that BIPCL consistently outperforms state-of-the-art baselines, with ablation studies confirming the contribution of each component.
VADTree: Explainable Training-Free Video Anomaly Detection via Hierarchical Granularity-Aware Tree
Oct 26, 2025Video anomaly detection (VAD) focuses on identifying anomalies in videos. Supervised methods demand substantial in-domain training data and fail to deliver clear explanations for anomalies. In contrast, training-free methods leverage the knowledge reserves and language interactivity of large pre-trained models to detect anomalies. However, the current fixed-length temporal window sampling approaches struggle to accurately capture anomalies with varying temporal spans. Therefore, we propose VADTree that utilizes a Hierarchical Granularityaware Tree (HGTree) structure for flexible sampling in VAD. VADTree leverages the knowledge embedded in a pre-trained Generic Event Boundary Detection (GEBD) model to characterize potential anomaly event boundaries. Specifically, VADTree decomposes the video into generic event nodes based on boundary confidence, and performs adaptive coarse-fine hierarchical structuring and redundancy removal to construct the HGTree. Then, the multi-dimensional priors are injected into the visual language models (VLMs) to enhance the node-wise anomaly perception, and anomaly reasoning for generic event nodes is achieved via large language models (LLMs). Finally, an inter-cluster node correlation method is used to integrate the multi-granularity anomaly scores. Extensive experiments on three challenging datasets demonstrate that VADTree achieves state-of-the-art performance in training-free settings while drastically reducing the number of sampled video segments. The code will be available at https://github.com/wenlongli10/VADTree.
Dual-View Disentangled Multi-Intent Learning for Enhanced Collaborative Filtering
Jun 13, 2025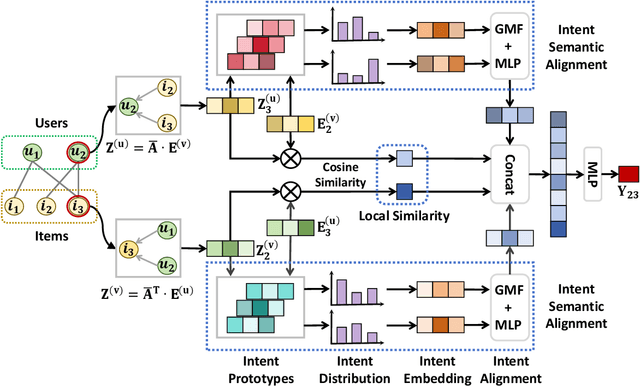
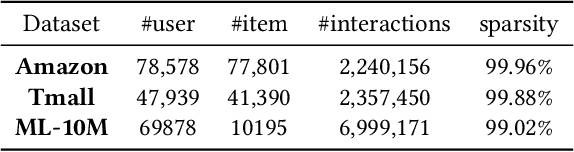
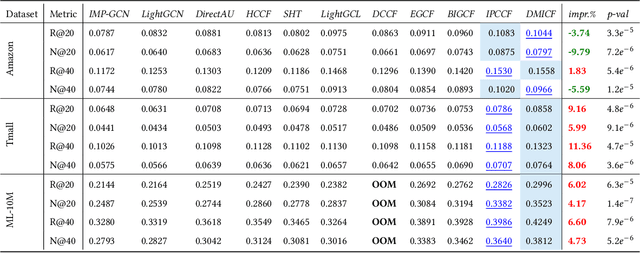
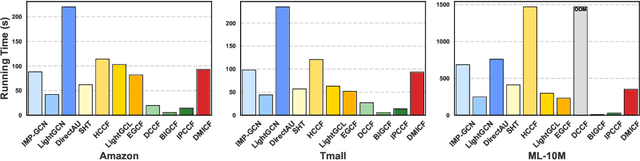
Disentangling user intentions from implicit feedback has become a promising strategy to enhance recommendation accuracy and interpretability. Prior methods often model intentions independently and lack explicit supervision, thus failing to capture the joint semantics that drive user-item interactions. To address these limitations, we propose DMICF, a unified framework that explicitly models interaction-level intent alignment while leveraging structural signals from both user and item perspectives. DMICF adopts a dual-view architecture that jointly encodes user-item interaction graphs from both sides, enabling bidirectional information fusion. This design enhances robustness under data sparsity by allowing the structural redundancy of one view to compensate for the limitations of the other. To model fine-grained user-item compatibility, DMICF introduces an intent interaction encoder that performs sub-intent alignment within each view, uncovering shared semantic structures that underlie user decisions. This localized alignment enables adaptive refinement of intent embeddings based on interaction context, thus improving the model's generalization and expressiveness, particularly in long-tail scenarios. Furthermore, DMICF integrates an intent-aware scoring mechanism that aggregates compatibility signals from matched intent pairs across user and item subspaces, enabling personalized prediction grounded in semantic congruence rather than entangled representations. To facilitate semantic disentanglement, we design a discriminative training signal via multi-negative sampling and softmax normalization, which pulls together semantically aligned intent pairs while pushing apart irrelevant or noisy ones. Extensive experiments demonstrate that DMICF consistently delivers robust performance across datasets with diverse interaction distributions.
Aerial Multi-View Stereo via Adaptive Depth Range Inference and Normal Cues
Jun 06, 2025Three-dimensional digital urban reconstruction from multi-view aerial images is a critical application where deep multi-view stereo (MVS) methods outperform traditional techniques. However, existing methods commonly overlook the key differences between aerial and close-range settings, such as varying depth ranges along epipolar lines and insensitive feature-matching associated with low-detailed aerial images. To address these issues, we propose an Adaptive Depth Range MVS (ADR-MVS), which integrates monocular geometric cues to improve multi-view depth estimation accuracy. The key component of ADR-MVS is the depth range predictor, which generates adaptive range maps from depth and normal estimates using cross-attention discrepancy learning. In the first stage, the range map derived from monocular cues breaks through predefined depth boundaries, improving feature-matching discriminability and mitigating convergence to local optima. In later stages, the inferred range maps are progressively narrowed, ultimately aligning with the cascaded MVS framework for precise depth regression. Moreover, a normal-guided cost aggregation operation is specially devised for aerial stereo images to improve geometric awareness within the cost volume. Finally, we introduce a normal-guided depth refinement module that surpasses existing RGB-guided techniques. Experimental results demonstrate that ADR-MVS achieves state-of-the-art performance on the WHU, LuoJia-MVS, and M\"unchen datasets, while exhibits superior computational complexity.
Unified Dual-view Cognitive Model for Interpretable Claim Verification
May 20, 2021
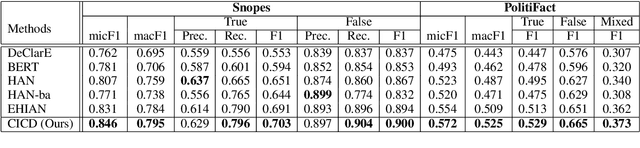
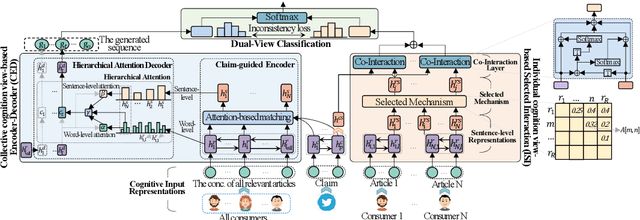
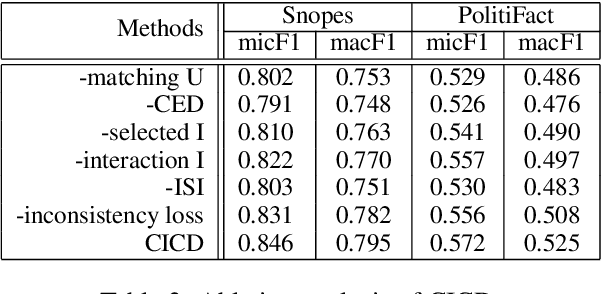
Recent studies constructing direct interactions between the claim and each single user response (a comment or a relevant article) to capture evidence have shown remarkable success in interpretable claim verification. Owing to different single responses convey different cognition of individual users (i.e., audiences), the captured evidence belongs to the perspective of individual cognition. However, individuals' cognition of social things is not always able to truly reflect the objective. There may be one-sided or biased semantics in their opinions on a claim. The captured evidence correspondingly contains some unobjective and biased evidence fragments, deteriorating task performance. In this paper, we propose a Dual-view model based on the views of Collective and Individual Cognition (CICD) for interpretable claim verification. From the view of the collective cognition, we not only capture the word-level semantics based on individual users, but also focus on sentence-level semantics (i.e., the overall responses) among all users and adjust the proportion between them to generate global evidence. From the view of individual cognition, we select the top-$k$ articles with high degree of difference and interact with the claim to explore the local key evidence fragments. To weaken the bias of individual cognition-view evidence, we devise inconsistent loss to suppress the divergence between global and local evidence for strengthening the consistent shared evidence between the both. Experiments on three benchmark datasets confirm that CICD achieves state-of-the-art performance.
DTCA: Decision Tree-based Co-Attention Networks for Explainable Claim Verification
Apr 28, 2020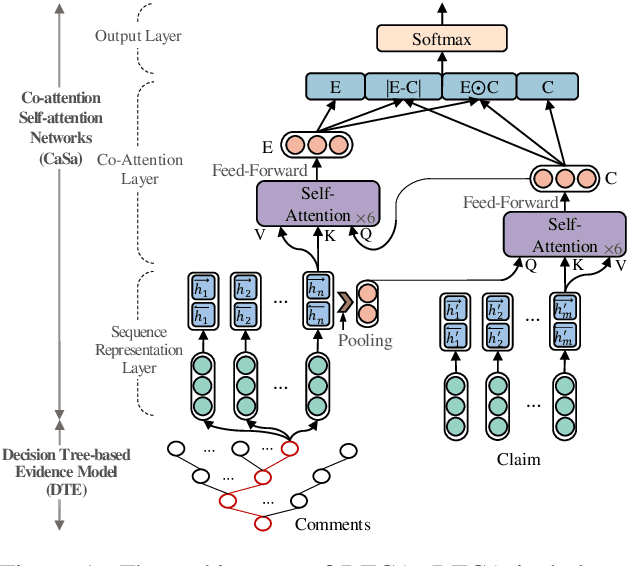
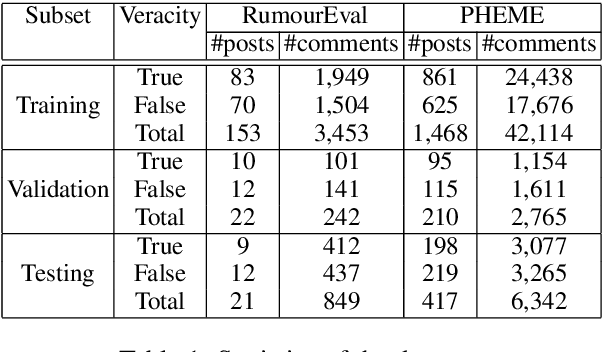
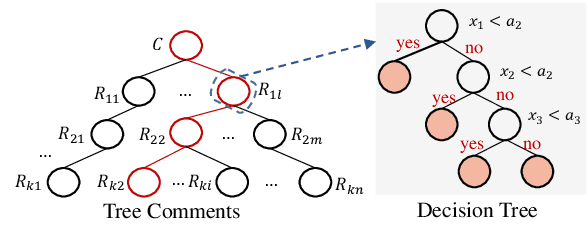
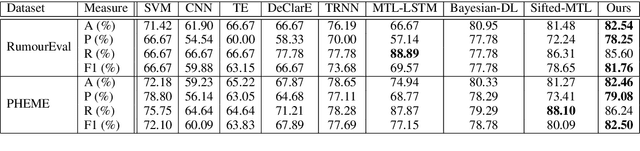
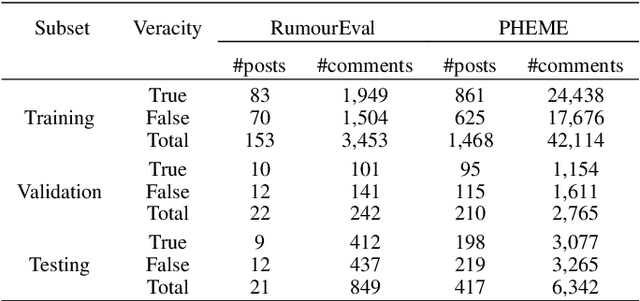
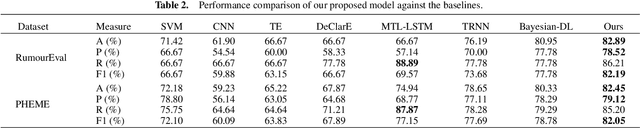
Recently, many methods discover effective evidence from reliable sources by appropriate neural networks for explainable claim verification, which has been widely recognized. However, in these methods, the discovery process of evidence is nontransparent and unexplained. Simultaneously, the discovered evidence only roughly aims at the interpretability of the whole sequence of claims but insufficient to focus on the false parts of claims. In this paper, we propose a Decision Tree-based Co-Attention model (DTCA) to discover evidence for explainable claim verification. Specifically, we first construct Decision Tree-based Evidence model (DTE) to select comments with high credibility as evidence in a transparent and interpretable way. Then we design Co-attention Self-attention networks (CaSa) to make the selected evidence interact with claims, which is for 1) training DTE to determine the optimal decision thresholds and obtain more powerful evidence; and 2) utilizing the evidence to find the false parts in the claim. Experiments on two public datasets, RumourEval and PHEME, demonstrate that DTCA not only provides explanations for the results of claim verification but also achieves the state-of-the-art performance, boosting the F1-score by 3.11%, 2.41%, respectively.
Adaptive Interaction Fusion Networks for Fake News Detection
Apr 21, 2020
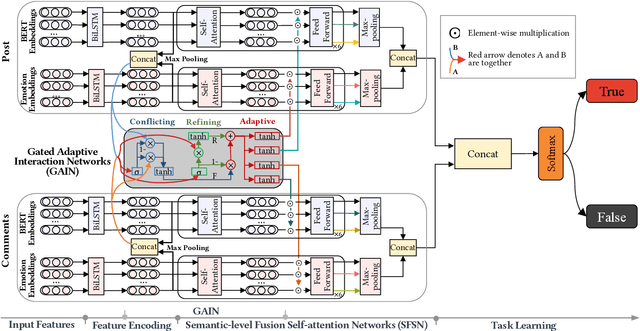
The majority of existing methods for fake news detection universally focus on learning and fusing various features for detection. However, the learning of various features is independent, which leads to a lack of cross-interaction fusion between features on social media, especially between posts and comments. Generally, in fake news, there are emotional associations and semantic conflicts between posts and comments. How to represent and fuse the cross-interaction between both is a key challenge. In this paper, we propose Adaptive Interaction Fusion Networks (AIFN) to fulfill cross-interaction fusion among features for fake news detection. In AIFN, to discover semantic conflicts, we design gated adaptive interaction networks (GAIN) to capture adaptively similar semantics and conflicting semantics between posts and comments. To establish feature associations, we devise semantic-level fusion self-attention networks (SFSN) to enhance semantic correlations and fusion among features. Extensive experiments on two real-world datasets, i.e., RumourEval and PHEME, demonstrate that AIFN achieves the state-of-the-art performance and boosts accuracy by more than 2.05% and 1.90%, respectively.
Discovering Differential Features: Adversarial Learning for Information Credibility Evaluation
Sep 16, 2019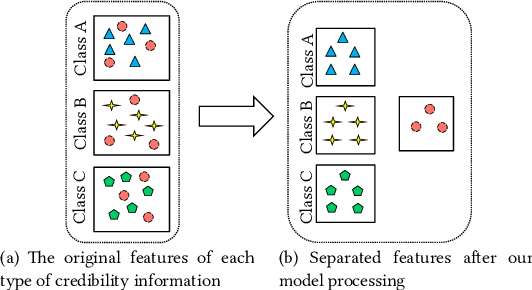
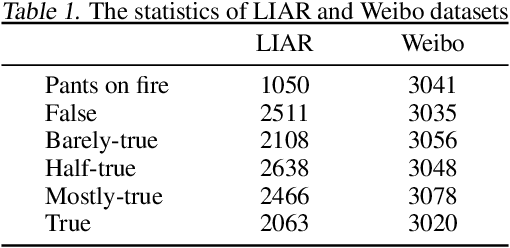
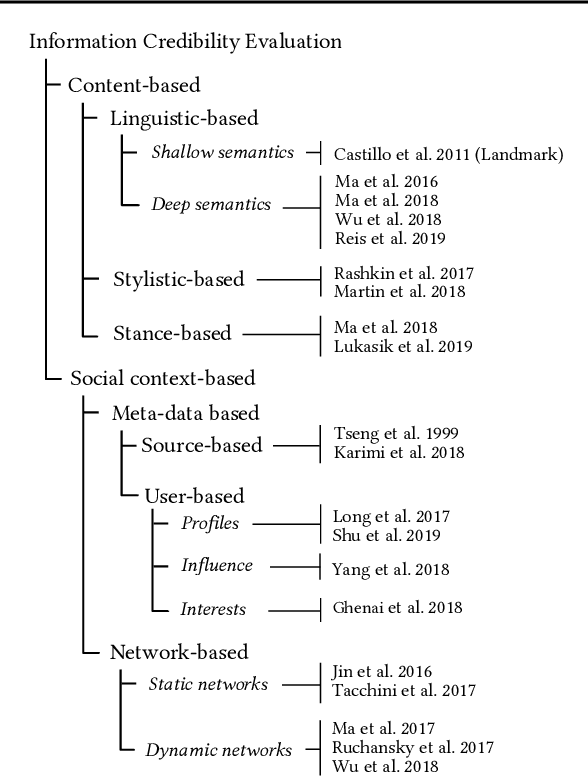
A series of deep learning approaches extract a large number of credibility features to detect fake news on the Internet. However, these extracted features still suffer from many irrelevant and noisy features that restrict severely the performance of the approaches. In this paper, we propose a novel model based on Adversarial Networks and inspirited by the Shared-Private model (ANSP), which aims at reducing common, irrelevant features from the extracted features for information credibility evaluation. Specifically, ANSP involves two tasks: one is to prevent the binary classification of true and false information for capturing common features relying on adversarial networks guided by reinforcement learning. Another extracts credibility features (henceforth, private features) from multiple types of credibility information and compares with the common features through two strategies, i.e., orthogonality constraints and KL-divergence for making the private features more differential. Experiments first on two six-label LIAR and Weibo datasets demonstrate that ANSP achieves the state-of-the-art performance, boosting the accuracy by 2.1%, 3.1%, respectively and then on four-label Twitter16 validate the robustness of the model with 1.8% performance improvements.
Different Absorption from the Same Sharing: Sifted Multi-task Learning for Fake News Detection
Sep 04, 2019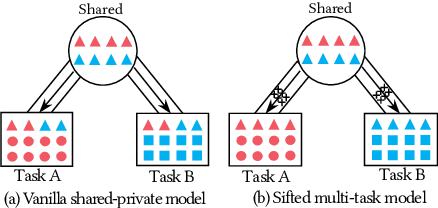
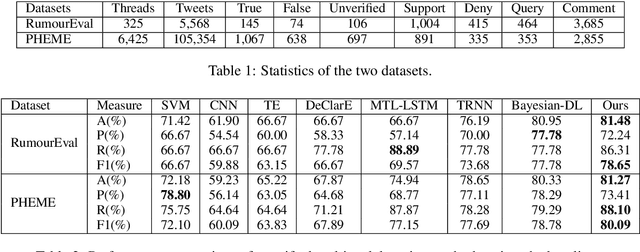
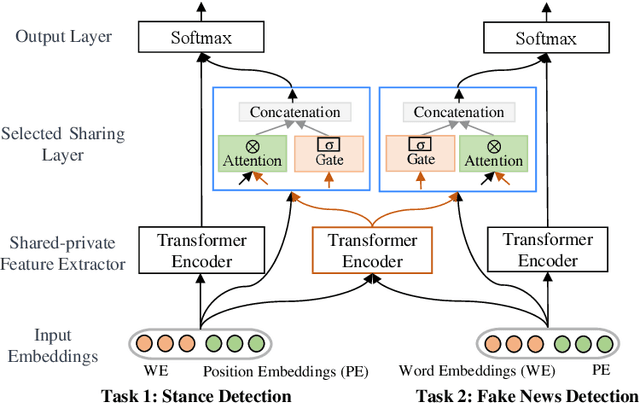
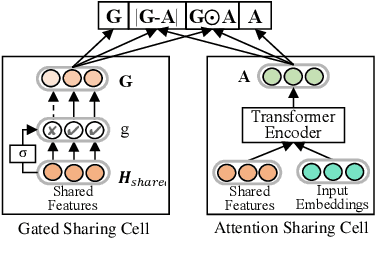
Recently, neural networks based on multi-task learning have achieved promising performance on fake news detection, which focus on learning shared features among tasks as complementary features to serve different tasks. However, in most of the existing approaches, the shared features are completely assigned to different tasks without selection, which may lead to some useless and even adverse features integrated into specific tasks. In this paper, we design a sifted multi-task learning method with a selected sharing layer for fake news detection. The selected sharing layer adopts gate mechanism and attention mechanism to filter and select shared feature flows between tasks. Experiments on two public and widely used competition datasets, i.e. RumourEval and PHEME, demonstrate that our proposed method achieves the state-of-the-art performance and boosts the F1-score by more than 0.87%, 1.31%, respectively.