 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOphthBench: A Comprehensive Benchmark for Evaluating Large Language Models in Chinese Ophthalmology
Feb 03, 2025Large language models (LLMs) have shown significant promise across various medical applications, with ophthalmology being a notable area of focus. Many ophthalmic tasks have shown substantial improvement through the integration of LLMs. However, before these models can be widely adopted in clinical practice, evaluating their capabilities and identifying their limitations is crucial. To address this research gap and support the real-world application of LLMs, we introduce the OphthBench, a specialized benchmark designed to assess LLM performance within the context of Chinese ophthalmic practices. This benchmark systematically divides a typical ophthalmic clinical workflow into five key scenarios: Education, Triage, Diagnosis, Treatment, and Prognosis. For each scenario, we developed multiple tasks featuring diverse question types, resulting in a comprehensive benchmark comprising 9 tasks and 591 questions. This comprehensive framework allows for a thorough assessment of LLMs' capabilities and provides insights into their practical application in Chinese ophthalmology. Using this benchmark, we conducted extensive experiments and analyzed the results from 39 popular LLMs. Our evaluation highlights the current gap between LLM development and its practical utility in clinical settings, providing a clear direction for future advancements. By bridging this gap, we aim to unlock the potential of LLMs and advance their development in ophthalmology.
LAD-RCNN:A Powerful Tool for Livestock Face Detection and Normalization
Nov 05, 2022With the demand for standardized large-scale livestock farming and the development of artificial intelligence technology, a lot of research in area of animal face recognition were carried on pigs, cattle, sheep and other livestock. Face recognition consists of three sub-task: face detection, face normalizing and face identification. Most of animal face recognition study focuses on face detection and face identification. Animals are often uncooperative when taking photos, so the collected animal face images are often in arbitrary directions. The use of non-standard images may significantly reduce the performance of face recognition system. However, there is no study on normalizing of the animal face image with arbitrary directions. In this study, we developed a light-weight angle detection and region-based convolutional network (LAD-RCNN) containing a new rotation angle coding method that can detect the rotation angle and the location of animal face in one-stage. LAD-RCNN has a frame rate of 72.74 FPS (including all steps) on a single GeForce RTX 2080 Ti GPU. LAD-RCNN has been evaluated on multiple dataset including goat dataset and gaot infrared image. Evaluation result show that the AP of face detection was more than 95% and the deviation between the detected rotation angle and the ground-truth rotation angle were less than 0.036 (i.e. 6.48{\deg}) on all the test dataset. This shows that LAD-RCNN has excellent performance on livestock face and its direction detection, and therefore it is very suitable for livestock face detection and Normalizing. Code is available at https://github.com/SheepBreedingLab-HZAU/LAD-RCNN/
Unified Dual-view Cognitive Model for Interpretable Claim Verification
May 20, 2021
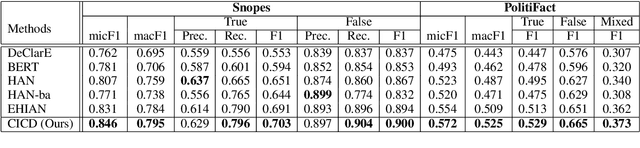
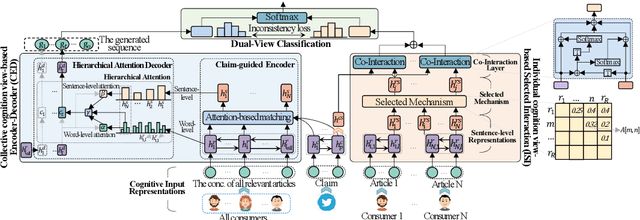
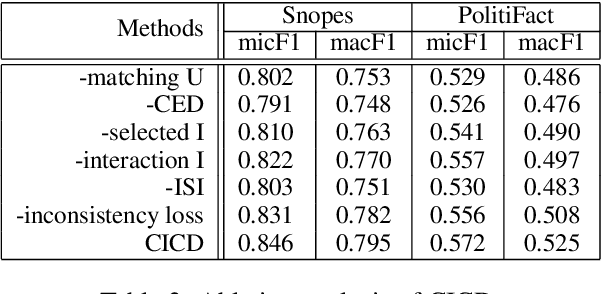
Recent studies constructing direct interactions between the claim and each single user response (a comment or a relevant article) to capture evidence have shown remarkable success in interpretable claim verification. Owing to different single responses convey different cognition of individual users (i.e., audiences), the captured evidence belongs to the perspective of individual cognition. However, individuals' cognition of social things is not always able to truly reflect the objective. There may be one-sided or biased semantics in their opinions on a claim. The captured evidence correspondingly contains some unobjective and biased evidence fragments, deteriorating task performance. In this paper, we propose a Dual-view model based on the views of Collective and Individual Cognition (CICD) for interpretable claim verification. From the view of the collective cognition, we not only capture the word-level semantics based on individual users, but also focus on sentence-level semantics (i.e., the overall responses) among all users and adjust the proportion between them to generate global evidence. From the view of individual cognition, we select the top-$k$ articles with high degree of difference and interact with the claim to explore the local key evidence fragments. To weaken the bias of individual cognition-view evidence, we devise inconsistent loss to suppress the divergence between global and local evidence for strengthening the consistent shared evidence between the both. Experiments on three benchmark datasets confirm that CICD achieves state-of-the-art performance.
Different Absorption from the Same Sharing: Sifted Multi-task Learning for Fake News Detection
Sep 04, 2019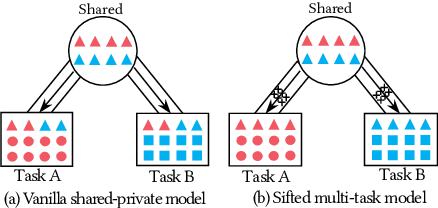
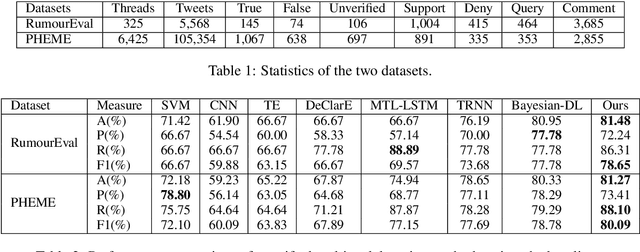
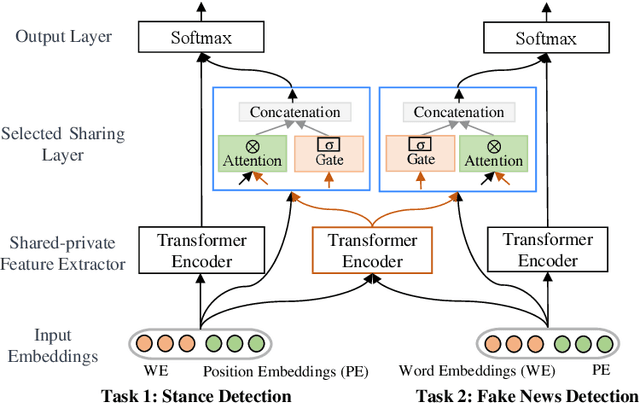
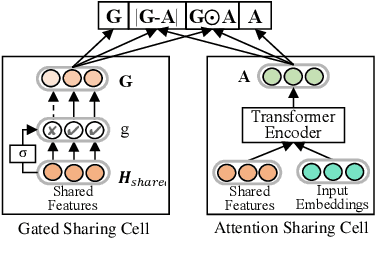
Recently, neural networks based on multi-task learning have achieved promising performance on fake news detection, which focus on learning shared features among tasks as complementary features to serve different tasks. However, in most of the existing approaches, the shared features are completely assigned to different tasks without selection, which may lead to some useless and even adverse features integrated into specific tasks. In this paper, we design a sifted multi-task learning method with a selected sharing layer for fake news detection. The selected sharing layer adopts gate mechanism and attention mechanism to filter and select shared feature flows between tasks. Experiments on two public and widely used competition datasets, i.e. RumourEval and PHEME, demonstrate that our proposed method achieves the state-of-the-art performance and boosts the F1-score by more than 0.87%, 1.31%, respectively.
3D Convolutional Encoder-Decoder Network for Low-Dose CT via Transfer Learning from a 2D Trained Network
Apr 29, 2018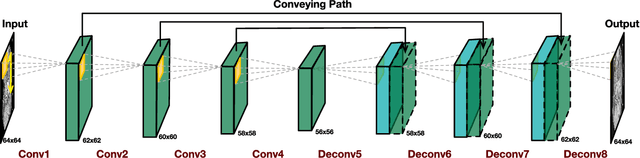
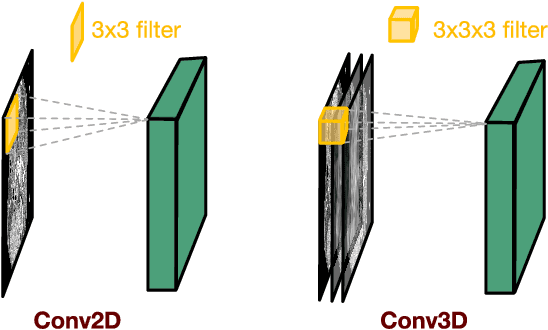
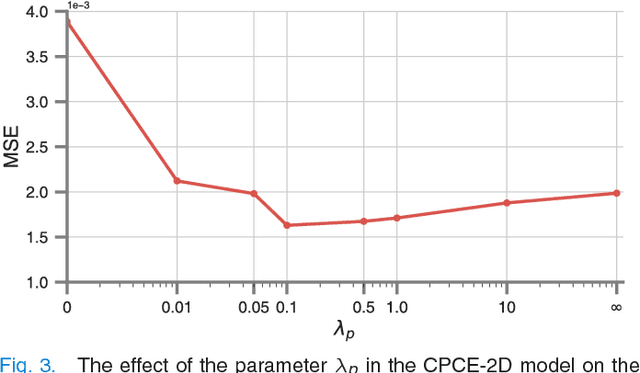
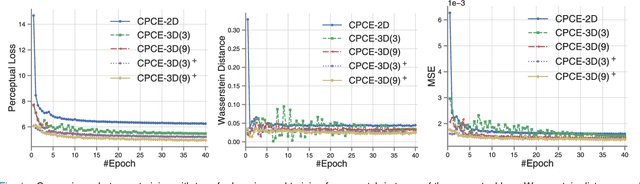
Low-dose computed tomography (CT) has attracted a major attention in the medical imaging field, since CT-associated x-ray radiation carries health risks for patients. The reduction of CT radiation dose, however, compromises the signal-to-noise ratio, and may compromise the image quality and the diagnostic performance. Recently, deep-learning-based algorithms have achieved promising results in low-dose CT denoising, especially convolutional neural network (CNN) and generative adversarial network (GAN). This article introduces a Contracting Path-based Convolutional Encoder-decoder (CPCE) network in 2D and 3D configurations within the GAN framework for low-dose CT denoising. A novel feature of our approach is that an initial 3D CPCE denoising model can be directly obtained by extending a trained 2D CNN and then fine-tuned to incorporate 3D spatial information from adjacent slices. Based on the transfer learning from 2D to 3D, the 3D network converges faster and achieves a better denoising performance than that trained from scratch. By comparing the CPCE with recently published methods based on the simulated Mayo dataset and the real MGH dataset, we demonstrate that the 3D CPCE denoising model has a better performance, suppressing image noise and preserving subtle structures.