 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpha Discovery via Grammar-Guided Learning and Search
Jan 29, 2026Automatically discovering formulaic alpha factors is a central problem in quantitative finance. Existing methods often ignore syntactic and semantic constraints, relying on exhaustive search over unstructured and unbounded spaces. We present AlphaCFG, a grammar-based framework for defining and discovering alpha factors that are syntactically valid, financially interpretable, and computationally efficient. AlphaCFG uses an alpha-oriented context-free grammar to define a tree-structured, size-controlled search space, and formulates alpha discovery as a tree-structured linguistic Markov decision process, which is then solved using a grammar-aware Monte Carlo Tree Search guided by syntax-sensitive value and policy networks. Experiments on Chinese and U.S. stock market datasets show that AlphaCFG outperforms state-of-the-art baselines in both search efficiency and trading profitability. Beyond trading strategies, AlphaCFG serves as a general framework for symbolic factor discovery and refinement across quantitative finance, including asset pricing and portfolio construction.
Enhancing 3D Semantic Scene Completion with a Refinement Module
Dec 20, 2025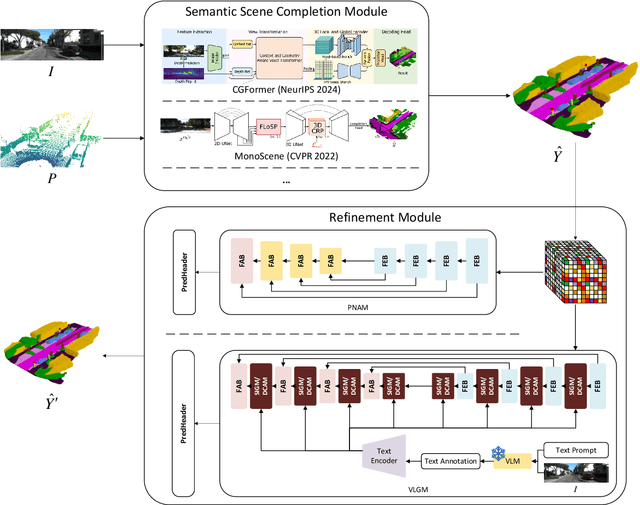
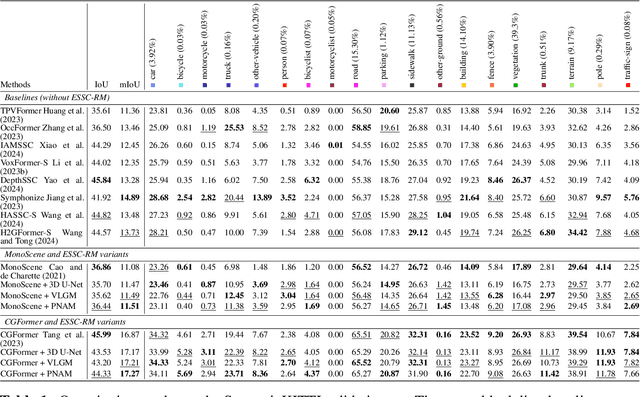
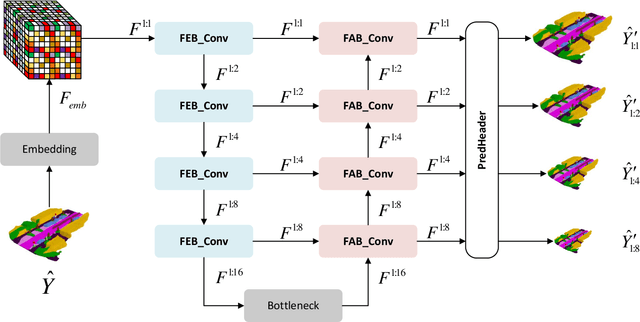

We propose ESSC-RM, a plug-and-play Enhancing framework for Semantic Scene Completion with a Refinement Module, which can be seamlessly integrated into existing SSC models. ESSC-RM operates in two phases: a baseline SSC network first produces a coarse voxel prediction, which is subsequently refined by a 3D U-Net-based Prediction Noise-Aware Module (PNAM) and Voxel-level Local Geometry Module (VLGM) under multiscale supervision. Experiments on SemanticKITTI show that ESSC-RM consistently improves semantic prediction performance. When integrated into CGFormer and MonoScene, the mean IoU increases from 16.87% to 17.27% and from 11.08% to 11.51%, respectively. These results demonstrate that ESSC-RM serves as a general refinement framework applicable to a wide range of SSC models.
A two-stream network with global-local feature fusion for bone age assessment
Dec 20, 2025



Bone Age Assessment (BAA) is a widely used clinical technique that can accurately reflect an individual's growth and development level, as well as maturity. In recent years, although deep learning has advanced the field of bone age assessment, existing methods face challenges in efficiently balancing global features and local skeletal details. This study aims to develop an automated bone age assessment system based on a two-stream deep learning architecture to achieve higher accuracy in bone age assessment. We propose the BoNet+ model incorporating global and local feature extraction channels. A Transformer module is introduced into the global feature extraction channel to enhance the ability in extracting global features through multi-head self-attention mechanism. A RFAConv module is incorporated into the local feature extraction channel to generate adaptive attention maps within multiscale receptive fields, enhancing local feature extraction capabilities. Global and local features are concatenated along the channel dimension and optimized by an Inception-V3 network. The proposed method has been validated on the Radiological Society of North America (RSNA) and Radiological Hand Pose Estimation (RHPE) test datasets, achieving mean absolute errors (MAEs) of 3.81 and 5.65 months, respectively. These results are comparable to the state-of-the-art. The BoNet+ model reduces the clinical workload and achieves automatic, high-precision, and more objective bone age assessment.
Authority Backdoor: A Certifiable Backdoor Mechanism for Authoring DNNs
Dec 11, 2025



Deep Neural Networks (DNNs), as valuable intellectual property, face unauthorized use. Existing protections, such as digital watermarking, are largely passive; they provide only post-hoc ownership verification and cannot actively prevent the illicit use of a stolen model. This work proposes a proactive protection scheme, dubbed ``Authority Backdoor," which embeds access constraints directly into the model. In particular, the scheme utilizes a backdoor learning framework to intrinsically lock a model's utility, such that it performs normally only in the presence of a specific trigger (e.g., a hardware fingerprint). But in its absence, the DNN's performance degrades to be useless. To further enhance the security of the proposed authority scheme, the certifiable robustness is integrated to prevent an adaptive attacker from removing the implanted backdoor. The resulting framework establishes a secure authority mechanism for DNNs, combining access control with certifiable robustness against adversarial attacks. Extensive experiments on diverse architectures and datasets validate the effectiveness and certifiable robustness of the proposed framework.
Referring Camouflaged Object Detection With Multi-Context Overlapped Windows Cross-Attention
Nov 17, 2025Referring camouflaged object detection (Ref-COD) aims to identify hidden objects by incorporating reference information such as images and text descriptions. Previous research has transformed reference images with salient objects into one-dimensional prompts, yielding significant results. We explore ways to enhance performance through multi-context fusion of rich salient image features and camouflaged object features. Therefore, we propose RFMNet, which utilizes features from multiple encoding stages of the reference salient images and performs interactive fusion with the camouflage features at the corresponding encoding stages. Given that the features in salient object images contain abundant object-related detail information, performing feature fusion within local areas is more beneficial for detecting camouflaged objects. Therefore, we propose an Overlapped Windows Cross-attention mechanism to enable the model to focus more attention on the local information matching based on reference features. Besides, we propose the Referring Feature Aggregation (RFA) module to decode and segment the camouflaged objects progressively. Extensive experiments on the Ref-COD benchmark demonstrate that our method achieves state-of-the-art performance.
A Dynamic Knowledge Distillation Method Based on the Gompertz Curve
Oct 24, 2025This paper introduces a novel dynamic knowledge distillation framework, Gompertz-CNN, which integrates the Gompertz growth model into the training process to address the limitations of traditional knowledge distillation. Conventional methods often fail to capture the evolving cognitive capacity of student models, leading to suboptimal knowledge transfer. To overcome this, we propose a stage-aware distillation strategy that dynamically adjusts the weight of distillation loss based on the Gompertz curve, reflecting the student's learning progression: slow initial growth, rapid mid-phase improvement, and late-stage saturation. Our framework incorporates Wasserstein distance to measure feature-level discrepancies and gradient matching to align backward propagation behaviors between teacher and student models. These components are unified under a multi-loss objective, where the Gompertz curve modulates the influence of distillation losses over time. Extensive experiments on CIFAR-10 and CIFAR-100 using various teacher-student architectures (e.g., ResNet50 and MobileNet_v2) demonstrate that Gompertz-CNN consistently outperforms traditional distillation methods, achieving up to 8% and 4% accuracy gains on CIFAR-10 and CIFAR-100, respectively.
Enhancing Robustness of Autoregressive Language Models against Orthographic Attacks via Pixel-based Approach
Aug 28, 2025Autoregressive language models are vulnerable to orthographic attacks, where input text is perturbed with characters from multilingual alphabets, leading to substantial performance degradation. This vulnerability primarily stems from the out-of-vocabulary issue inherent in subword tokenizers and their embeddings. To address this limitation, we propose a pixel-based generative language model that replaces the text-based embeddings with pixel-based representations by rendering words as individual images. This design provides stronger robustness to noisy inputs, while an extension of compatibility to multilingual text across diverse writing systems. We evaluate the proposed method on the multilingual LAMBADA dataset, WMT24 dataset and the SST-2 benchmark, demonstrating both its resilience to orthographic noise and its effectiveness in multilingual settings.
$\text{S}^2$Q-VDiT: Accurate Quantized Video Diffusion Transformer with Salient Data and Sparse Token Distillation
Aug 06, 2025Diffusion transformers have emerged as the mainstream paradigm for video generation models. However, the use of up to billions of parameters incurs significant computational costs. Quantization offers a promising solution by reducing memory usage and accelerating inference. Nonetheless, we observe that the joint modeling of spatial and temporal information in video diffusion models (V-DMs) leads to extremely long token sequences, which introduces high calibration variance and learning challenges. To address these issues, we propose \textbf{$\text{S}^2$Q-VDiT}, a post-training quantization framework for V-DMs that leverages \textbf{S}alient data and \textbf{S}parse token distillation. During the calibration phase, we identify that quantization performance is highly sensitive to the choice of calibration data. To mitigate this, we introduce \textit{Hessian-aware Salient Data Selection}, which constructs high-quality calibration datasets by considering both diffusion and quantization characteristics unique to V-DMs. To tackle the learning challenges, we further analyze the sparse attention patterns inherent in V-DMs. Based on this observation, we propose \textit{Attention-guided Sparse Token Distillation}, which exploits token-wise attention distributions to emphasize tokens that are more influential to the model's output. Under W4A6 quantization, $\text{S}^2$Q-VDiT achieves lossless performance while delivering $3.9\times$ model compression and $1.3\times$ inference acceleration. Code will be available at \href{https://github.com/wlfeng0509/s2q-vdit}{https://github.com/wlfeng0509/s2q-vdit}.
Automating Expert-Level Medical Reasoning Evaluation of Large Language Models
Jul 10, 2025As large language models (LLMs) become increasingly integrated into clinical decision-making, ensuring transparent and trustworthy reasoning is essential. However, existing evaluation strategies of LLMs' medical reasoning capability either suffer from unsatisfactory assessment or poor scalability, and a rigorous benchmark remains lacking. To address this, we introduce MedThink-Bench, a benchmark designed for rigorous, explainable, and scalable assessment of LLMs' medical reasoning. MedThink-Bench comprises 500 challenging questions across ten medical domains, each annotated with expert-crafted step-by-step rationales. Building on this, we propose LLM-w-Ref, a novel evaluation framework that leverages fine-grained rationales and LLM-as-a-Judge mechanisms to assess intermediate reasoning with expert-level fidelity while maintaining scalability. Experiments show that LLM-w-Ref exhibits a strong positive correlation with expert judgments. Benchmarking twelve state-of-the-art LLMs, we find that smaller models (e.g., MedGemma-27B) can surpass larger proprietary counterparts (e.g., OpenAI-o3). Overall, MedThink-Bench offers a foundational tool for evaluating LLMs' medical reasoning, advancing their safe and responsible deployment in clinical practice.
Intriguing Frequency Interpretation of Adversarial Robustness for CNNs and ViTs
Jun 15, 2025Adversarial examples have attracted significant attention over the years, yet understanding their frequency-based characteristics remains insufficient. In this paper, we investigate the intriguing properties of adversarial examples in the frequency domain for the image classification task, with the following key findings. (1) As the high-frequency components increase, the performance gap between adversarial and natural examples becomes increasingly pronounced. (2) The model performance against filtered adversarial examples initially increases to a peak and declines to its inherent robustness. (3) In Convolutional Neural Networks, mid- and high-frequency components of adversarial examples exhibit their attack capabilities, while in Transformers, low- and mid-frequency components of adversarial examples are particularly effective. These results suggest that different network architectures have different frequency preferences and that differences in frequency components between adversarial and natural examples may directly influence model robustness. Based on our findings, we further conclude with three useful proposals that serve as a valuable reference to the AI model security community.