 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.
Multi-Teacher Knowledge Distillation with Reinforcement Learning for Visual Recognition
Feb 22, 2025Multi-teacher Knowledge Distillation (KD) transfers diverse knowledge from a teacher pool to a student network. The core problem of multi-teacher KD is how to balance distillation strengths among various teachers. Most existing methods often develop weighting strategies from an individual perspective of teacher performance or teacher-student gaps, lacking comprehensive information for guidance. This paper proposes Multi-Teacher Knowledge Distillation with Reinforcement Learning (MTKD-RL) to optimize multi-teacher weights. In this framework, we construct both teacher performance and teacher-student gaps as state information to an agent. The agent outputs the teacher weight and can be updated by the return reward from the student. MTKD-RL reinforces the interaction between the student and teacher using an agent in an RL-based decision mechanism, achieving better matching capability with more meaningful weights. Experimental results on visual recognition tasks, including image classification, object detection, and semantic segmentation tasks, demonstrate that MTKD-RL achieves state-of-the-art performance compared to the existing multi-teacher KD works.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


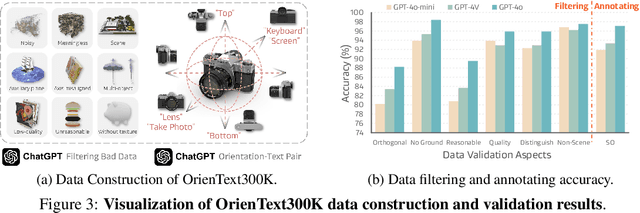
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes
Oct 30, 2024



Grasping in cluttered scenes remains highly challenging for dexterous hands due to the scarcity of data. To address this problem, we present a large-scale synthetic benchmark, encompassing 1319 objects, 8270 scenes, and 427 million grasps. Beyond benchmarking, we also propose a novel two-stage grasping method that learns efficiently from data by using a diffusion model that conditions on local geometry. Our proposed generative method outperforms all baselines in simulation experiments. Furthermore, with the aid of test-time-depth restoration, our method demonstrates zero-shot sim-to-real transfer, attaining 90.7% real-world dexterous grasping success rate in cluttered scenes.
Online Policy Distillation with Decision-Attention
Jun 08, 2024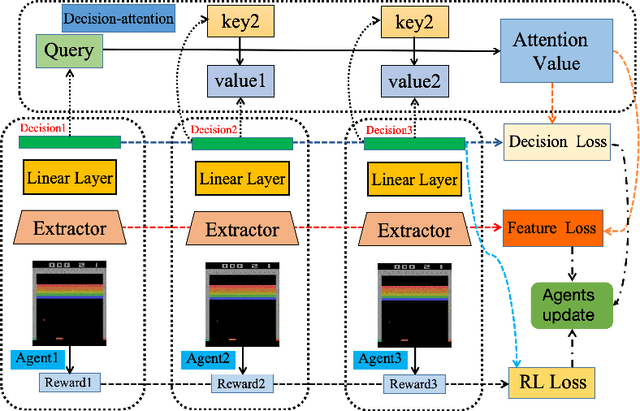
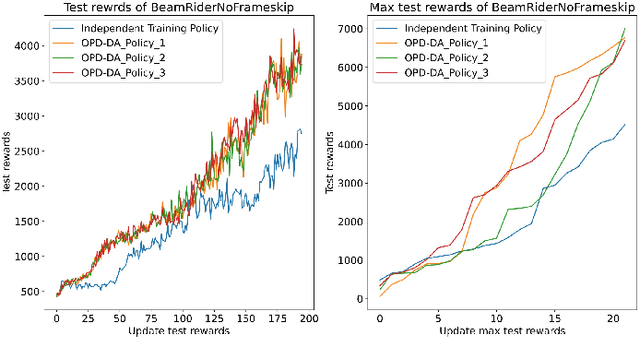
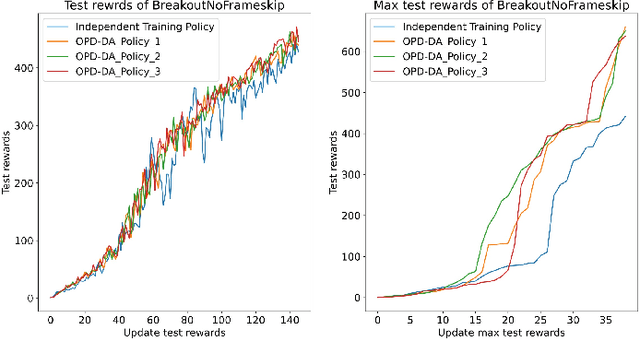
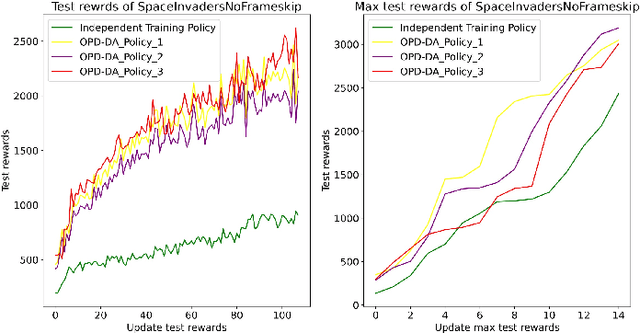
Policy Distillation (PD) has become an effective method to improve deep reinforcement learning tasks. The core idea of PD is to distill policy knowledge from a teacher agent to a student agent. However, the teacher-student framework requires a well-trained teacher model which is computationally expensive.In the light of online knowledge distillation, we study the knowledge transfer between different policies that can learn diverse knowledge from the same environment.In this work, we propose Online Policy Distillation (OPD) with Decision-Attention (DA), an online learning framework in which different policies operate in the same environment to learn different perspectives of the environment and transfer knowledge to each other to obtain better performance together. With the absence of a well-performance teacher policy, the group-derived targets play a key role in transferring group knowledge to each student policy. However, naive aggregation functions tend to cause student policies quickly homogenize. To address the challenge, we introduce the Decision-Attention module to the online policies distillation framework. The Decision-Attention module can generate a distinct set of weights for each policy to measure the importance of group members. We use the Atari platform for experiments with various reinforcement learning algorithms, including PPO and DQN. In different tasks, our method can perform better than an independent training policy on both PPO and DQN algorithms. This suggests that our OPD-DA can transfer knowledge between different policies well and help agents obtain more rewards.
Exemplar-Free Class Incremental Learning via Incremental Representation
Mar 24, 2024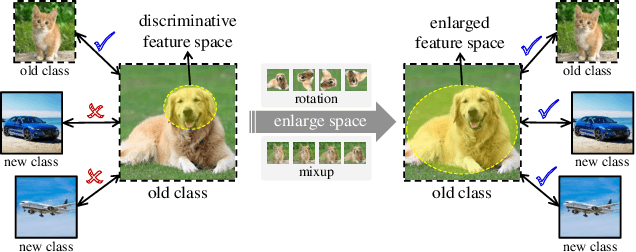
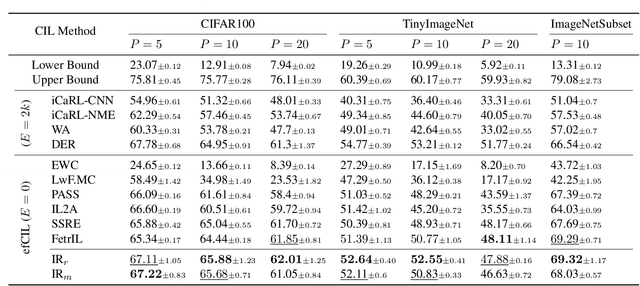
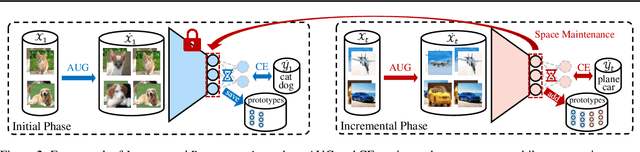
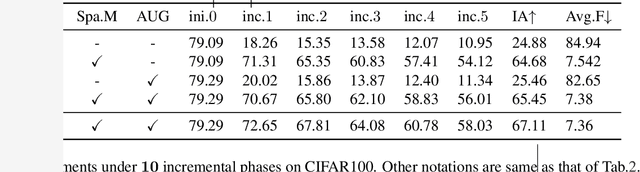
Exemplar-Free Class Incremental Learning (efCIL) aims to continuously incorporate the knowledge from new classes while retaining previously learned information, without storing any old-class exemplars (i.e., samples). For this purpose, various efCIL methods have been proposed over the past few years, generally with elaborately constructed old pseudo-features, increasing the difficulty of model development and interpretation. In contrast, we propose a \textbf{simple Incremental Representation (IR) framework} for efCIL without constructing old pseudo-features. IR utilizes dataset augmentation to cover a suitable feature space and prevents the model from forgetting by using a single L2 space maintenance loss. We discard the transient classifier trained on each one of the sequence tasks and instead replace it with a 1-near-neighbor classifier for inference, ensuring the representation is incrementally updated during CIL. Extensive experiments demonstrate that our proposed IR achieves comparable performance while significantly preventing the model from forgetting on CIFAR100, TinyImageNet, and ImageNetSubset datasets.
CLIP-KD: An Empirical Study of Distilling CLIP Models
Jul 24, 2023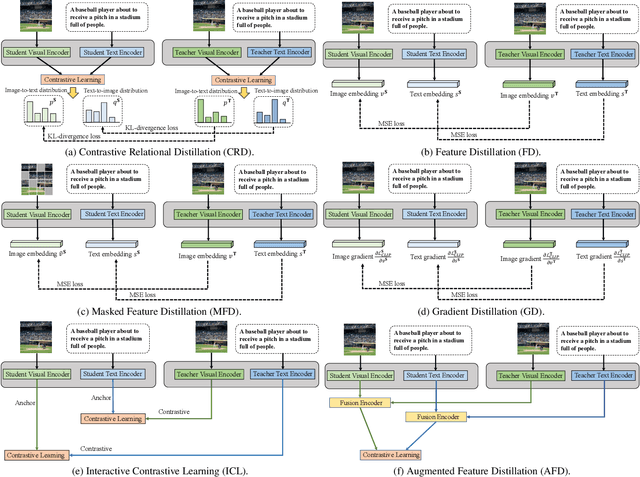
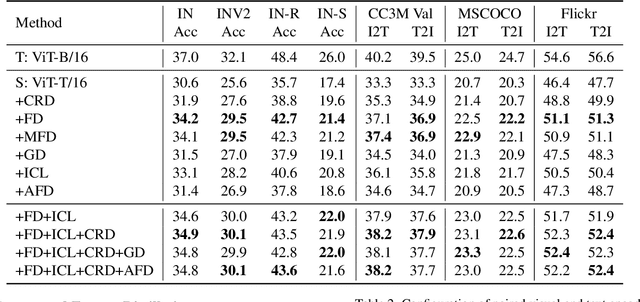
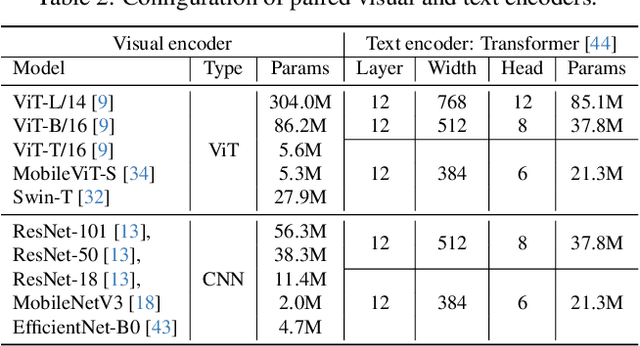
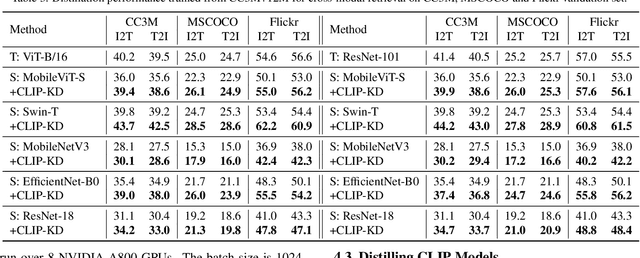
CLIP has become a promising language-supervised visual pre-training framework and achieves excellent performance over a wide range of tasks. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigm, to examine the impact on CLIP distillation. We show that the simplest feature mimicry with MSE loss performs best. Moreover, interactive contrastive learning and relation-based distillation are also critical in performance improvement. We apply the unified method to distill several student networks trained on 15 million (image, text) pairs. Distillation improves the student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. We hope our empirical study will become an important baseline for future CLIP distillation research. The code is available at \url{https://github.com/winycg/CLIP-KD}.
Categories of Response-Based, Feature-Based, and Relation-Based Knowledge Distillation
Jun 19, 2023



Deep neural networks have achieved remarkable performance for artificial intelligence tasks. The success behind intelligent systems often relies on large-scale models with high computational complexity and storage costs. The over-parameterized networks are often easy to optimize and can achieve better performance. However, it is challenging to deploy them over resource-limited edge-devices. Knowledge Distillation (KD) aims to optimize a lightweight network from the perspective of over-parameterized training. The traditional offline KD transfers knowledge from a cumbersome teacher to a small and fast student network. When a sizeable pre-trained teacher network is unavailable, online KD can improve a group of models by collaborative or mutual learning. Without needing extra models, Self-KD boosts the network itself using attached auxiliary architectures. KD mainly involves knowledge extraction and distillation strategies these two aspects. Beyond KD schemes, various KD algorithms are widely used in practical applications, such as multi-teacher KD, cross-modal KD, attention-based KD, data-free KD and adversarial KD. This paper provides a comprehensive KD survey, including knowledge categories, distillation schemes and algorithms, as well as some empirical studies on performance comparison. Finally, we discuss the open challenges of existing KD works and prospect the future directions.