 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pseudo-Labeling for Pre-Ranking with LLMs
Feb 24, 2026Pre-ranking is a critical stage in industrial recommendation systems, tasked with efficiently scoring thousands of recalled items for downstream ranking. A key challenge is the train-serving discrepancy: pre-ranking models are trained only on exposed interactions, yet must score all recalled candidates -- including unexposed items -- during online serving. This mismatch not only induces severe sample selection bias but also degrades generalization, especially for long-tail content. Existing debiasing approaches typically rely on heuristics (e.g., negative sampling) or distillation from biased rankers, which either mislabel plausible unexposed items as negatives or propagate exposure bias into pseudo-labels. In this work, we propose Generative Pseudo-Labeling (GPL), a framework that leverages large language models (LLMs) to generate unbiased, content-aware pseudo-labels for unexposed items, explicitly aligning the training distribution with the online serving space. By offline generating user-specific interest anchors and matching them with candidates in a frozen semantic space, GPL provides high-quality supervision without adding online latency. Deployed in a large-scale production system, GPL improves click-through rate by 3.07%, while significantly enhancing recommendation diversity and long-tail item discovery.
HiSAC: Hierarchical Sparse Activation Compression for Ultra-long Sequence Modeling in Recommenders
Feb 24, 2026Modern recommender systems leverage ultra-long user behavior sequences to capture dynamic preferences, but end-to-end modeling is infeasible in production due to latency and memory constraints. While summarizing history via interest centers offers a practical alternative, existing methods struggle to (1) identify user-specific centers at appropriate granularity and (2) accurately assign behaviors, leading to quantization errors and loss of long-tail preferences. To alleviate these issues, we propose Hierarchical Sparse Activation Compression (HiSAC), an efficient framework for personalized sequence modeling. HiSAC encodes interactions into multi-level semantic IDs and constructs a global hierarchical codebook. A hierarchical voting mechanism sparsely activates personalized interest-agents as fine-grained preference centers. Guided by these agents, Soft-Routing Attention aggregates historical signals in semantic space, weighting by similarity to minimize quantization error and retain long-tail behaviors. Deployed on Taobao's "Guess What You Like" homepage, HiSAC achieves significant compression and cost reduction, with online A/B tests showing a consistent 1.65% CTR uplift -- demonstrating its scalability and real-world effectiveness.
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Jun 20, 2024Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization. In this paper, we explore supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of Instruction Pre-Training. In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B. Our model, code, and data are available at https://github.com/microsoft/LMOps.
CLIP-KD: An Empirical Study of Distilling CLIP Models
Jul 24, 2023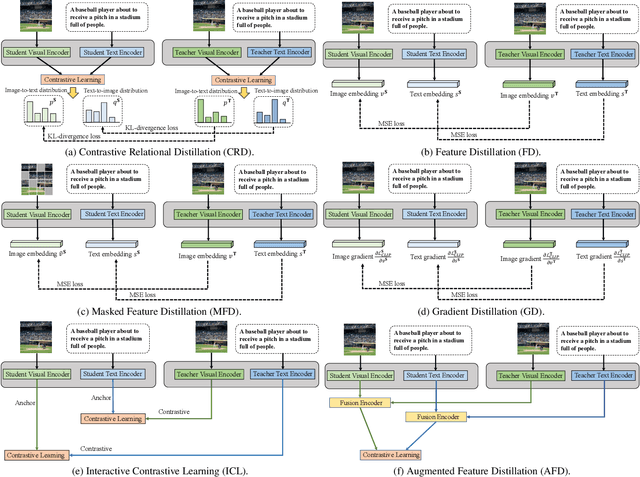
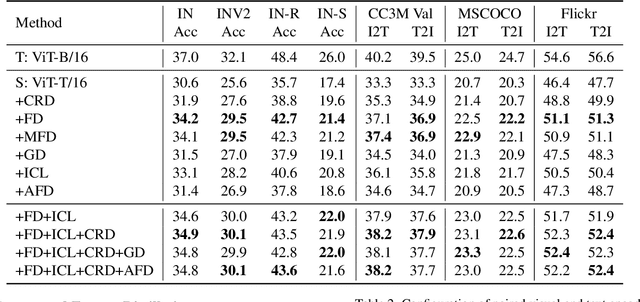
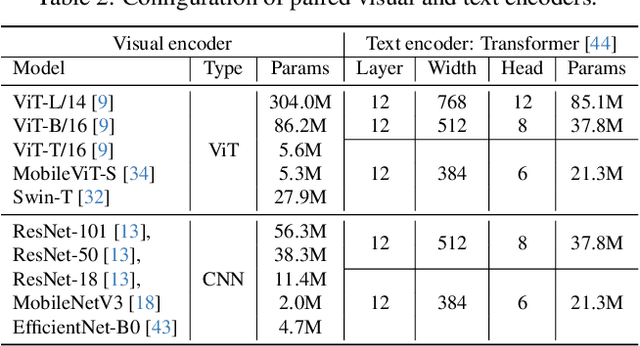
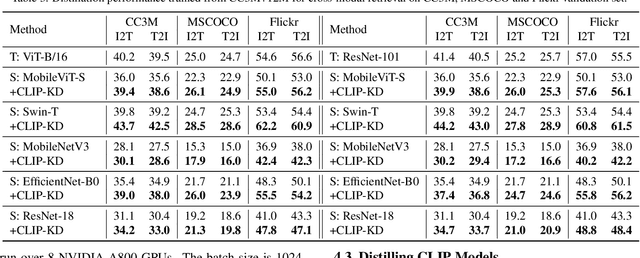
CLIP has become a promising language-supervised visual pre-training framework and achieves excellent performance over a wide range of tasks. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigm, to examine the impact on CLIP distillation. We show that the simplest feature mimicry with MSE loss performs best. Moreover, interactive contrastive learning and relation-based distillation are also critical in performance improvement. We apply the unified method to distill several student networks trained on 15 million (image, text) pairs. Distillation improves the student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. We hope our empirical study will become an important baseline for future CLIP distillation research. The code is available at \url{https://github.com/winycg/CLIP-KD}.
UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation
Mar 22, 2023



Large Language Models (LLMs) are popular for their impressive abilities, but the need for model-specific fine-tuning or task-specific prompt engineering can hinder their generalization. We propose UPRISE (Universal Prompt Retrieval for Improving zero-Shot Evaluation), which tunes a lightweight and versatile retriever that automatically retrieves prompts for a given zero-shot task input. Specifically, we demonstrate universality in a cross-task and cross-model scenario: the retriever is tuned on a diverse set of tasks, but tested on unseen task types; we use a small frozen LLM, GPT-Neo-2.7B, for tuning the retriever, but test the retriever on different LLMs of much larger scales, such as BLOOM-7.1B, OPT-66B and GPT3-175B. Additionally, we show that UPRISE mitigates the hallucination problem in our experiments with ChatGPT, suggesting its potential to improve even the strongest LLMs. Our model and code are available at https://github.com/microsoft/LMOps.