 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-KD: An Empirical Study of Distilling CLIP Models
Paper and Code
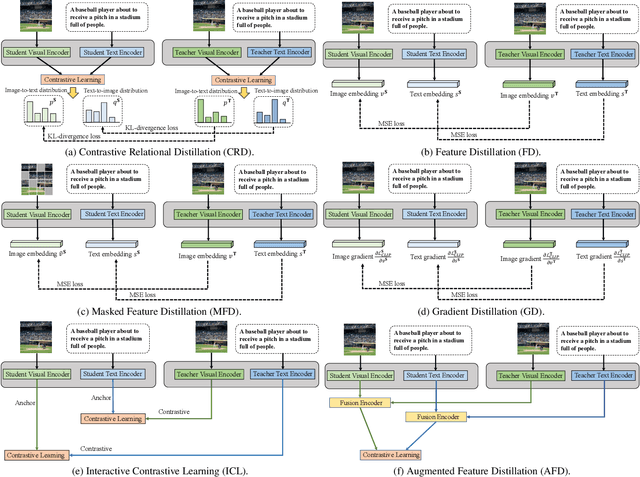
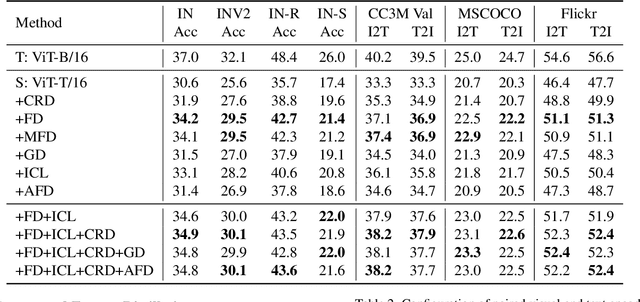
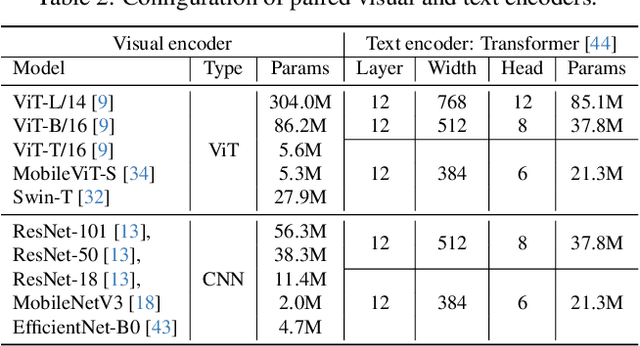
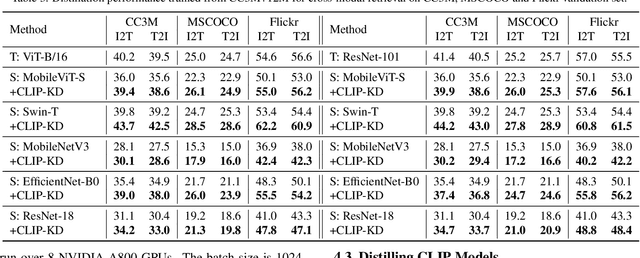
CLIP has become a promising language-supervised visual pre-training framework and achieves excellent performance over a wide range of tasks. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigm, to examine the impact on CLIP distillation. We show that the simplest feature mimicry with MSE loss performs best. Moreover, interactive contrastive learning and relation-based distillation are also critical in performance improvement. We apply the unified method to distill several student networks trained on 15 million (image, text) pairs. Distillation improves the student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. We hope our empirical study will become an important baseline for future CLIP distillation research. The code is available at \url{https://github.com/winycg/CLIP-KD}.