 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-in-Sandbox Elicits General Agentic Intelligence
Jan 22, 2026We introduce LLM-in-Sandbox, enabling LLMs to explore within a code sandbox (i.e., a virtual computer), to elicit general intelligence in non-code domains. We first demonstrate that strong LLMs, without additional training, exhibit generalization capabilities to leverage the code sandbox for non-code tasks. For example, LLMs spontaneously access external resources to acquire new knowledge, leverage the file system to handle long contexts, and execute scripts to satisfy formatting requirements. We further show that these agentic capabilities can be enhanced through LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL), which uses only non-agentic data to train models for sandbox exploration. Experiments demonstrate that LLM-in-Sandbox, in both training-free and post-trained settings, achieves robust generalization spanning mathematics, physics, chemistry, biomedicine, long-context understanding, and instruction following. Finally, we analyze LLM-in-Sandbox's efficiency from computational and system perspectives, and open-source it as a Python package to facilitate real-world deployment.
Trust-Region Adaptive Policy Optimization
Dec 19, 2025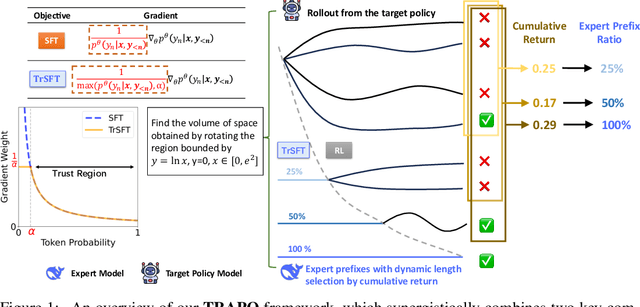
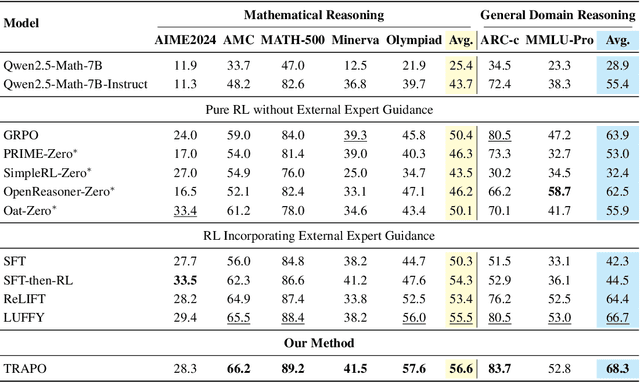
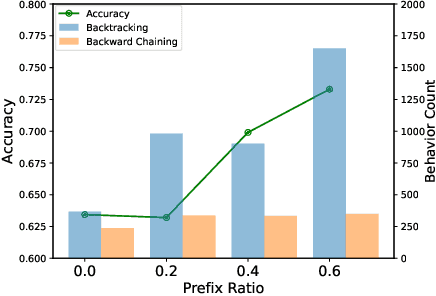

Post-training methods, especially Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), play an important role in improving large language models' (LLMs) complex reasoning abilities. However, the dominant two-stage pipeline (SFT then RL) suffers from a key inconsistency: SFT enforces rigid imitation that suppresses exploration and induces forgetting, limiting RL's potential for improvements. We address this inefficiency with TRAPO (\textbf{T}rust-\textbf{R}egion \textbf{A}daptive \textbf{P}olicy \textbf{O}ptimization), a hybrid framework that interleaves SFT and RL within each training instance by optimizing SFT loss on expert prefixes and RL loss on the model's own completions, unifying external supervision and self-exploration. To stabilize training, we introduce Trust-Region SFT (TrSFT), which minimizes forward KL divergence inside a trust region but attenuates optimization outside, effectively shifting toward reverse KL and yielding stable, mode-seeking updates favorable for RL. An adaptive prefix-selection mechanism further allocates expert guidance based on measured utility. Experiments on five mathematical reasoning benchmarks show that TRAPO consistently surpasses standard SFT, RL, and SFT-then-RL pipelines, as well as recent state-of-the-art approaches, establishing a strong new paradigm for reasoning-enhanced LLMs.
Data-Efficient RLVR via Off-Policy Influence Guidance
Oct 30, 2025Data selection is a critical aspect of Reinforcement Learning with Verifiable Rewards (RLVR) for enhancing the reasoning capabilities of large language models (LLMs). Current data selection methods are largely heuristic-based, lacking theoretical guarantees and generalizability. This work proposes a theoretically-grounded approach using influence functions to estimate the contribution of each data point to the learning objective. To overcome the prohibitive computational cost of policy rollouts required for online influence estimation, we introduce an off-policy influence estimation method that efficiently approximates data influence using pre-collected offline trajectories. Furthermore, to manage the high-dimensional gradients of LLMs, we employ sparse random projection to reduce dimensionality and improve storage and computation efficiency. Leveraging these techniques, we develop \textbf{C}urriculum \textbf{R}L with \textbf{O}ff-\textbf{P}olicy \text{I}nfluence guidance (\textbf{CROPI}), a multi-stage RL framework that iteratively selects the most influential data for the current policy. Experiments on models up to 7B parameters demonstrate that CROPI significantly accelerates training. On a 1.5B model, it achieves a 2.66x step-level acceleration while using only 10\% of the data per stage compared to full-dataset training. Our results highlight the substantial potential of influence-based data selection for efficient RLVR.
NVILA: Efficient Frontier Visual Language Models
Dec 05, 2024
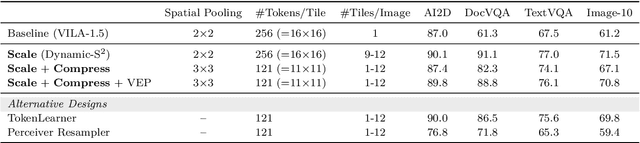

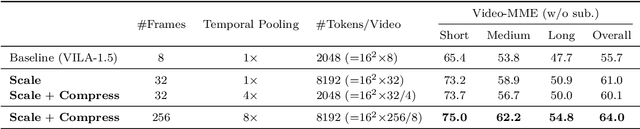
Visual language models (VLMs) have made significant advances in accuracy in recent years. However, their efficiency has received much less attention. This paper introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6-2.2X, and decoding latency by 1.2-2.8X. We will soon make our code and models available to facilitate reproducibility.
MiniPLM: Knowledge Distillation for Pre-Training Language Models
Oct 22, 2024Knowledge distillation (KD) is widely used to train small, high-performing student language models (LMs) using large teacher LMs. While effective in fine-tuning, KD during pre-training faces challenges in efficiency, flexibility, and effectiveness. Existing methods either incur high computational costs due to online teacher inference, require tokenization matching between teacher and student LMs, or risk losing the difficulty and diversity of the teacher-generated training data. To address these issues, we propose MiniPLM, a KD framework for pre-training LMs by refining the training data distribution with the teacher's knowledge. For efficiency, MiniPLM performs offline teacher LM inference, allowing KD for multiple student LMs without adding training-time costs. For flexibility, MiniPLM operates solely on the training corpus, enabling KD across model families. For effectiveness, MiniPLM leverages the differences between large and small LMs to enhance the difficulty and diversity of the training data, helping student LMs acquire versatile and sophisticated knowledge. Extensive experiments demonstrate that MiniPLM boosts the student LMs' performance on 9 widely used downstream tasks, improves the language modeling capabilities, and reduces pre-training computation. The benefit of MiniPLM extends to large pre-training scales, evidenced by the extrapolation of the scaling curves. Further analysis reveals that MiniPLM supports KD across model families and enhances the utilization of pre-training data. Our model, code, and data are available at https://github.com/thu-coai/MiniPLM.
Data Selection via Optimal Control for Language Models
Oct 09, 2024



This work investigates the selection of high-quality pre-training data from massive corpora to enhance LMs' capabilities for downstream usage. We formulate data selection as a generalized Optimal Control problem, which can be solved theoretically by Pontryagin's Maximum Principle (PMP), yielding a set of necessary conditions that characterize the relationship between optimal data selection and LM training dynamics. Based on these theoretical results, we introduce PMP-based Data Selection (PDS), a framework that approximates optimal data selection by solving the PMP conditions. In our experiments, we adopt PDS to select data from CommmonCrawl and show that the PDS-selected corpus accelerates the learning of LMs and constantly boosts their performance on a wide range of downstream tasks across various model sizes. Moreover, the benefits of PDS extend to ~400B models trained on ~10T tokens, as evidenced by the extrapolation of the test loss curves according to the Scaling Laws. PDS also improves data utilization when the pre-training data is limited, by reducing the data demand by 1.8 times, which mitigates the quick exhaustion of available web-crawled corpora. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/data_selection.
Direct Preference Knowledge Distillation for Large Language Models
Jun 28, 2024



In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models. However, existing KD methods face limitations and challenges in distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence. It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function. We re-formulate KD of LLMs into two stages: first optimizing and objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs. We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrate the broad applicability and effectiveness of our DPKD approach. Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage. Code and data are available at https://aka.ms/dpkd.
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Jun 20, 2024Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization. In this paper, we explore supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of Instruction Pre-Training. In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B. Our model, code, and data are available at https://github.com/microsoft/LMOps.
Towards Optimal Learning of Language Models
Mar 03, 2024This work studies the general principles of improving the learning of language models (LMs), which aims at reducing the necessary training steps for achieving superior performance. Specifically, we present a theory for the optimal learning of LMs. We first propose an objective that optimizes LM learning by maximizing the data compression ratio in an "LM-training-as-lossless-compression" view. Then, we derive a theorem, named Learning Law, to reveal the properties of the dynamics in the optimal learning process under our objective. The theorem is then validated by experiments on a linear classification and a real-world language modeling task. Finally, we empirically verify that the optimal learning of LMs essentially stems from the improvement of the coefficients in the scaling law of LMs, indicating great promise and significance for designing practical learning acceleration methods. Our code can be found at https://aka.ms/LearningLaw.
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.