 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025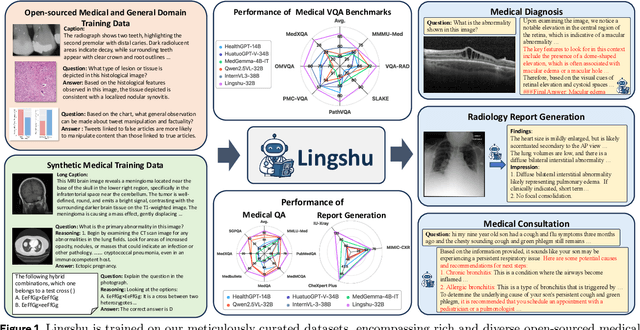
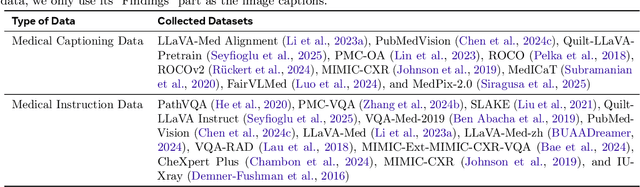
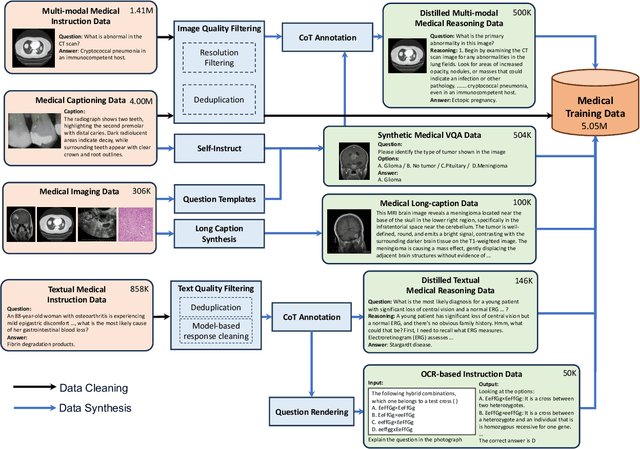

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.
Progressive Translation: Improving Domain Robustness of Neural Machine Translation with Intermediate Sequences
May 16, 2023Previous studies show that intermediate supervision signals benefit various Natural Language Processing tasks. However, it is not clear whether there exist intermediate signals that benefit Neural Machine Translation (NMT). Borrowing techniques from Statistical Machine Translation, we propose intermediate signals which are intermediate sequences from the "source-like" structure to the "target-like" structure. Such intermediate sequences introduce an inductive bias that reflects a domain-agnostic principle of translation, which reduces spurious correlations that are harmful to out-of-domain generalisation. Furthermore, we introduce a full-permutation multi-task learning to alleviate the spurious causal relations from intermediate sequences to the target, which results from exposure bias. The Minimum Bayes Risk decoding algorithm is used to pick the best candidate translation from all permutations to further improve the performance. Experiments show that the introduced intermediate signals can effectively improve the domain robustness of NMT and reduces the amount of hallucinations on out-of-domain translation. Further analysis shows that our methods are especially promising in low-resource scenarios.
On Exposure Bias, Hallucination and Domain Shift in Neural Machine Translation
May 07, 2020

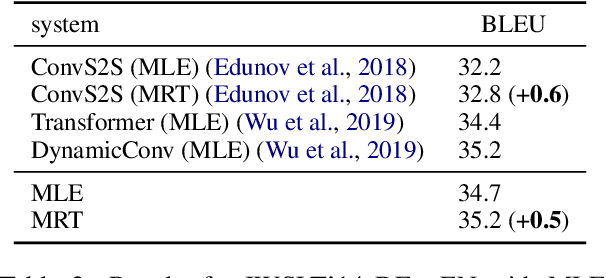

The standard training algorithm in neural machine translation (NMT) suffers from exposure bias, and alternative algorithms have been proposed to mitigate this. However, the practical impact of exposure bias is under debate. In this paper, we link exposure bias to another well-known problem in NMT, namely the tendency to generate hallucinations under domain shift. In experiments on three datasets with multiple test domains, we show that exposure bias is partially to blame for hallucinations, and that training with Minimum Risk Training, which avoids exposure bias, can mitigate this. Our analysis explains why exposure bias is more problematic under domain shift, and also links exposure bias to the beam search problem, i.e. performance deterioration with increasing beam size. Our results provide a new justification for methods that reduce exposure bias: even if they do not increase performance on in-domain test sets, they can increase model robustness to domain shift.