 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIGOURATE: Quantifying Scientific Exaggeration with Evidence-Aligned Claim Evaluation
Jan 07, 2026Scientific rigour tends to be sidelined in favour of bold statements, leading authors to overstate claims beyond what their results support. We present RIGOURATE, a two-stage multimodal framework that retrieves supporting evidence from a paper's body and assigns each claim an overstatement score. The framework consists of a dataset of over 10K claim-evidence sets from ICLR and NeurIPS papers, annotated using eight LLMs, with overstatement scores calibrated using peer-review comments and validated through human evaluation. It employes a fine-tuned reranker for evidence retrieval and a fine-tuned model to predict overstatement scores with justification. Compared to strong baselines, RIGOURATE enables improved evidence retrieval and overstatement detection. Overall, our work operationalises evidential proportionality and supports clearer, more transparent scientific communication.
Drivel-ology: Challenging LLMs with Interpreting Nonsense with Depth
Sep 04, 2025



We introduce Drivelology, a unique linguistic phenomenon characterised as "nonsense with depth", utterances that are syntactically coherent yet pragmatically paradoxical, emotionally loaded, or rhetorically subversive. While such expressions may resemble surface-level nonsense, they encode implicit meaning requiring contextual inference, moral reasoning, or emotional interpretation. We find that current large language models (LLMs), despite excelling at many natural language processing (NLP) tasks, consistently fail to grasp the layered semantics of Drivelological text. To investigate this, we construct a small but diverse benchmark dataset of over 1,200 meticulously curated examples, with select instances in English, Mandarin, Spanish, French, Japanese, and Korean. Annotation was especially challenging: each of the examples required careful expert review to verify that it truly reflected Drivelological characteristics. The process involved multiple rounds of discussion and adjudication to address disagreements, highlighting the subtle and subjective nature of the Drivelology. We evaluate a range of LLMs on classification, generation, and reasoning tasks. Our results reveal clear limitations of LLMs: models often confuse Drivelology with shallow nonsense, produce incoherent justifications, or miss the implied rhetorical function altogether. These findings highlight a deeper representational gap in LLMs' pragmatic understanding and challenge the assumption that statistical fluency implies cognitive comprehension. We release our dataset and code to facilitate further research in modelling linguistic depth beyond surface-level coherence.
VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
Jul 30, 2025



Reinforcement learning has proven its effectiveness in enhancing the reasoning capabilities of large language models. Recent research efforts have progressively extended this paradigm to multimodal reasoning tasks. Due to the inherent complexity and diversity of multimodal tasks, especially in semantic content and problem formulations, existing models often exhibit unstable performance across various domains and difficulty levels. To address these limitations, we propose VL-Cogito, an advanced multimodal reasoning model trained via a novel multi-stage Progressive Curriculum Reinforcement Learning (PCuRL) framework. PCuRL systematically guides the model through tasks of gradually increasing difficulty, substantially improving its reasoning abilities across diverse multimodal contexts. The framework introduces two key innovations: (1) an online difficulty soft weighting mechanism, dynamically adjusting training difficulty across successive RL training stages; and (2) a dynamic length reward mechanism, which encourages the model to adaptively regulate its reasoning path length according to task complexity, thus balancing reasoning efficiency with correctness. Experimental evaluations demonstrate that VL-Cogito consistently matches or surpasses existing reasoning-oriented models across mainstream multimodal benchmarks spanning mathematics, science, logic, and general understanding, validating the effectiveness of our approach.
ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning
Jun 11, 2025Though reasoning-based large language models (LLMs) have excelled in mathematics and programming, their capabilities in knowledge-intensive medical question answering remain underexplored. To address this, we introduce ReasonMed, the largest medical reasoning dataset, comprising 370k high-quality examples distilled from 1.7 million initial reasoning paths generated by various LLMs. ReasonMed is constructed through a \textit{multi-agent verification and refinement process}, where we design an \textit{Error Refiner} to enhance the reasoning paths by identifying and correcting error-prone steps flagged by a verifier. Leveraging ReasonMed, we systematically investigate best practices for training medical reasoning models and find that combining detailed Chain-of-Thought (CoT) reasoning with concise answer summaries yields the most effective fine-tuning strategy. Based on this strategy, we train ReasonMed-7B, which sets a new benchmark for sub-10B models, outperforming the prior best by 4.17\% and even exceeding LLaMA3.1-70B on PubMedQA by 4.60\%.
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025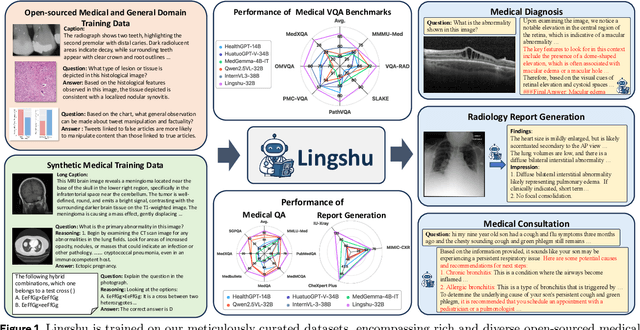
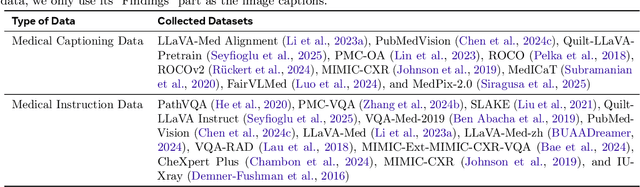
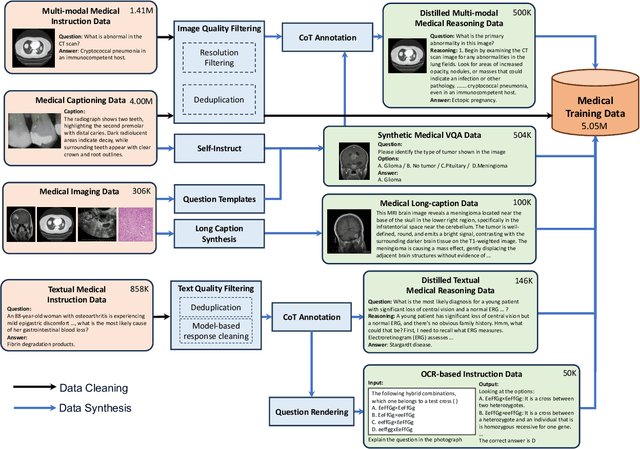

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
Beyond One-Size-Fits-All: Inversion Learning for Highly Effective NLG Evaluation Prompts
Apr 29, 2025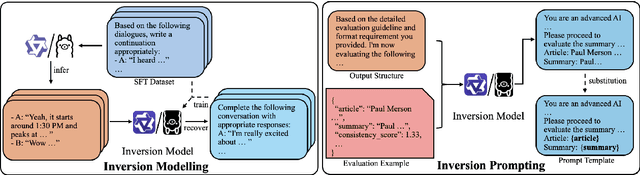
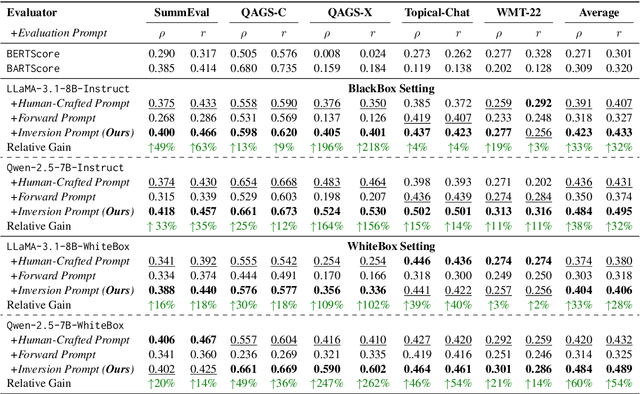

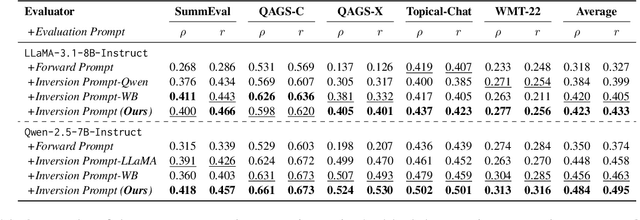
Evaluating natural language generation (NLG) systems is challenging due to the diversity of valid outputs. While human evaluation is the gold standard, it suffers from inconsistencies, lack of standardisation, and demographic biases, limiting reproducibility. LLM-based evaluation offers a scalable alternative but is highly sensitive to prompt design, where small variations can lead to significant discrepancies. In this work, we propose an inversion learning method that learns effective reverse mappings from model outputs back to their input instructions, enabling the automatic generation of highly effective, model-specific evaluation prompts. Our method requires only a single evaluation sample and eliminates the need for time-consuming manual prompt engineering, thereby improving both efficiency and robustness. Our work contributes toward a new direction for more robust and efficient LLM-based evaluation.
Analyzing LLMs' Knowledge Boundary Cognition Across Languages Through the Lens of Internal Representations
Apr 18, 2025While understanding the knowledge boundaries of LLMs is crucial to prevent hallucination, research on knowledge boundaries of LLMs has predominantly focused on English. In this work, we present the first study to analyze how LLMs recognize knowledge boundaries across different languages by probing their internal representations when processing known and unknown questions in multiple languages. Our empirical studies reveal three key findings: 1) LLMs' perceptions of knowledge boundaries are encoded in the middle to middle-upper layers across different languages. 2) Language differences in knowledge boundary perception follow a linear structure, which motivates our proposal of a training-free alignment method that effectively transfers knowledge boundary perception ability across languages, thereby helping reduce hallucination risk in low-resource languages; 3) Fine-tuning on bilingual question pair translation further enhances LLMs' recognition of knowledge boundaries across languages. Given the absence of standard testbeds for cross-lingual knowledge boundary analysis, we construct a multilingual evaluation suite comprising three representative types of knowledge boundary data. Our code and datasets are publicly available at https://github.com/DAMO-NLP-SG/LLM-Multilingual-Knowledge-Boundaries.
MIEB: Massive Image Embedding Benchmark
Apr 14, 2025Image representations are often evaluated through disjointed, task-specific protocols, leading to a fragmented understanding of model capabilities. For instance, it is unclear whether an image embedding model adept at clustering images is equally good at retrieving relevant images given a piece of text. We introduce the Massive Image Embedding Benchmark (MIEB) to evaluate the performance of image and image-text embedding models across the broadest spectrum to date. MIEB spans 38 languages across 130 individual tasks, which we group into 8 high-level categories. We benchmark 50 models across our benchmark, finding that no single method dominates across all task categories. We reveal hidden capabilities in advanced vision models such as their accurate visual representation of texts, and their yet limited capabilities in interleaved encodings and matching images and texts in the presence of confounders. We also show that the performance of vision encoders on MIEB correlates highly with their performance when used in multimodal large language models. Our code, dataset, and leaderboard are publicly available at https://github.com/embeddings-benchmark/mteb.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Everything is a Video: Unifying Modalities through Next-Frame Prediction
Nov 15, 2024Multimodal learning, which involves integrating information from various modalities such as text, images, audio, and video, is pivotal for numerous complex tasks like visual question answering, cross-modal retrieval, and caption generation. Traditional approaches rely on modality-specific encoders and late fusion techniques, which can hinder scalability and flexibility when adapting to new tasks or modalities. To address these limitations, we introduce a novel framework that extends the concept of task reformulation beyond natural language processing (NLP) to multimodal learning. We propose to reformulate diverse multimodal tasks into a unified next-frame prediction problem, allowing a single model to handle different modalities without modality-specific components. This method treats all inputs and outputs as sequential frames in a video, enabling seamless integration of modalities and effective knowledge transfer across tasks. Our approach is evaluated on a range of tasks, including text-to-text, image-to-text, video-to-video, video-to-text, and audio-to-text, demonstrating the model's ability to generalize across modalities with minimal adaptation. We show that task reformulation can significantly simplify multimodal model design across various tasks, laying the groundwork for more generalized multimodal foundation models.