 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything is a Video: Unifying Modalities through Next-Frame Prediction
Nov 15, 2024Multimodal learning, which involves integrating information from various modalities such as text, images, audio, and video, is pivotal for numerous complex tasks like visual question answering, cross-modal retrieval, and caption generation. Traditional approaches rely on modality-specific encoders and late fusion techniques, which can hinder scalability and flexibility when adapting to new tasks or modalities. To address these limitations, we introduce a novel framework that extends the concept of task reformulation beyond natural language processing (NLP) to multimodal learning. We propose to reformulate diverse multimodal tasks into a unified next-frame prediction problem, allowing a single model to handle different modalities without modality-specific components. This method treats all inputs and outputs as sequential frames in a video, enabling seamless integration of modalities and effective knowledge transfer across tasks. Our approach is evaluated on a range of tasks, including text-to-text, image-to-text, video-to-video, video-to-text, and audio-to-text, demonstrating the model's ability to generalize across modalities with minimal adaptation. We show that task reformulation can significantly simplify multimodal model design across various tasks, laying the groundwork for more generalized multimodal foundation models.
AttenCraft: Attention-guided Disentanglement of Multiple Concepts for Text-to-Image Customization
May 28, 2024



With the unprecedented performance being achieved by text-to-image (T2I) diffusion models, T2I customization further empowers users to tailor the diffusion model to new concepts absent in the pre-training dataset, termed subject-driven generation. Moreover, extracting several new concepts from a single image enables the model to learn multiple concepts, and simultaneously decreases the difficulties of training data preparation, urging the disentanglement of multiple concepts to be a new challenge. However, existing models for disentanglement commonly require pre-determined masks or retain background elements. To this end, we propose an attention-guided method, AttenCraft, for multiple concept disentanglement. In particular, our method leverages self-attention and cross-attention maps to create accurate masks for each concept within a single initialization step, omitting any required mask preparation by humans or other models. The created masks are then applied to guide the cross-attention activation of each target concept during training and achieve concept disentanglement. Additionally, we introduce Uniform sampling and Reweighted sampling schemes to alleviate the non-synchronicity of feature acquisition from different concepts, and improve generation quality. Our method outperforms baseline models in terms of image-alignment, and behaves comparably on text-alignment. Finally, we showcase the applicability of AttenCraft to more complicated settings, such as an input image containing three concepts. The project is available at https://github.com/junjie-shentu/AttenCraft.
Textual Localization: Decomposing Multi-concept Images for Subject-Driven Text-to-Image Generation
Feb 15, 2024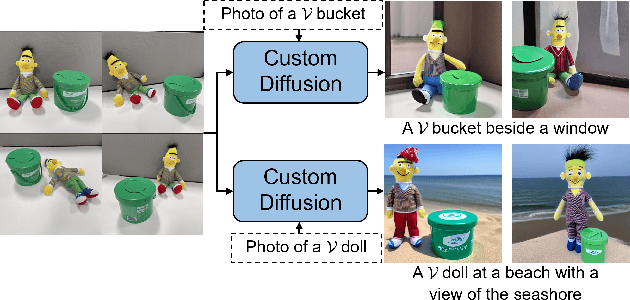

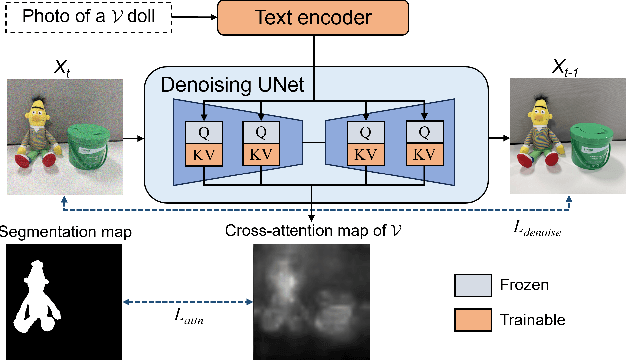
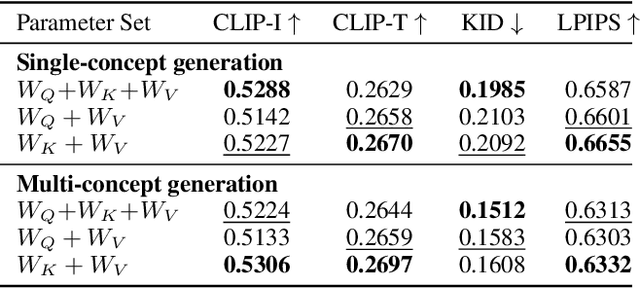
Subject-driven text-to-image diffusion models empower users to tailor the model to new concepts absent in the pre-training dataset using a few sample images. However, prevalent subject-driven models primarily rely on single-concept input images, facing challenges in specifying the target concept when dealing with multi-concept input images. To this end, we introduce a textual localized text-to-image model (Texual Localization) to handle multi-concept input images. During fine-tuning, our method incorporates a novel cross-attention guidance to decompose multiple concepts, establishing distinct connections between the visual representation of the target concept and the identifier token in the text prompt. Experimental results reveal that our method outperforms or performs comparably to the baseline models in terms of image fidelity and image-text alignment on multi-concept input images. In comparison to Custom Diffusion, our method with hard guidance achieves CLIP-I scores that are 7.04%, 8.13% higher and CLIP-T scores that are 2.22%, 5.85% higher in single-concept and multi-concept generation, respectively. Notably, our method generates cross-attention maps consistent with the target concept in the generated images, a capability absent in existing models.