 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRovoDev Code Reviewer: A Large-Scale Online Evaluation of LLM-based Code Review Automation at Atlassian
Jan 03, 2026Large Language Models (LLMs)-powered code review automation has the potential to transform code review workflows. Despite the advances of LLM-powered code review comment generation approaches, several practical challenges remain for designing enterprise-grade code review automation tools. In particular, this paper aims at answering the practical question: how can we design a review-guided, context-aware, quality-checked code review comment generation without fine-tuning? In this paper, we present RovoDev Code Reviewer, an enterprise-grade LLM-based code review automation tool designed and deployed at scale within Atlassian's development ecosystem with seamless integration into Atlassian's Bitbucket. Through the offline, online, user feedback evaluations over a one-year period, we conclude that RovoDev Code Reviewer is (1) effective in generating code review comments that could lead to code resolution for 38.70% (i.e., comments that triggered code changes in the subsequent commits); and (2) offers the promise of accelerating feedback cycles (i.e., decreasing the PR cycle time by 30.8%), alleviating reviewer workload (i.e., reducing the number of human-written comments by 35.6%), and improving overall software quality (i.e., finding errors with actionable suggestions).
WildLive: Near Real-time Visual Wildlife Tracking onboard UAVs
Apr 15, 2025Live tracking of wildlife via high-resolution video processing directly onboard drones is widely unexplored and most existing solutions rely on streaming video to ground stations to support navigation. Yet, both autonomous animal-reactive flight control beyond visual line of sight and/or mission-specific individual and behaviour recognition tasks rely to some degree on this capability. In response, we introduce WildLive -- a near real-time animal detection and tracking framework for high-resolution imagery running directly onboard uncrewed aerial vehicles (UAVs). The system performs multi-animal detection and tracking at 17fps+ for HD and 7fps+ on 4K video streams suitable for operation during higher altitude flights to minimise animal disturbance. Our system is optimised for Jetson Orin AGX onboard hardware. It integrates the efficiency of sparse optical flow tracking and mission-specific sampling with device-optimised and proven YOLO-driven object detection and segmentation techniques. Essentially, computational resource is focused onto spatio-temporal regions of high uncertainty to significantly improve UAV processing speeds without domain-specific loss of accuracy. Alongside, we introduce our WildLive dataset, which comprises 200k+ annotated animal instances across 19k+ frames from 4K UAV videos collected at the Ol Pejeta Conservancy in Kenya. All frames contain ground truth bounding boxes, segmentation masks, as well as individual tracklets and tracking point trajectories. We compare our system against current object tracking approaches including OC-SORT, ByteTrack, and SORT. Our materials are available at: https://dat-nguyenvn.github.io/WildLive/
MMLA: Multi-Environment, Multi-Species, Low-Altitude Aerial Footage Dataset
Apr 10, 2025Real-time wildlife detection in drone imagery is critical for numerous applications, including animal ecology, conservation, and biodiversity monitoring. Low-altitude drone missions are effective for collecting fine-grained animal movement and behavior data, particularly if missions are automated for increased speed and consistency. However, little work exists on evaluating computer vision models on low-altitude aerial imagery and generalizability across different species and settings. To fill this gap, we present a novel multi-environment, multi-species, low-altitude aerial footage (MMLA) dataset. MMLA consists of drone footage collected across three diverse environments: Ol Pejeta Conservancy and Mpala Research Centre in Kenya, and The Wilds Conservation Center in Ohio, which includes five species: Plains zebras, Grevy's zebras, giraffes, onagers, and African Painted Dogs. We comprehensively evaluate three YOLO models (YOLOv5m, YOLOv8m, and YOLOv11m) for detecting animals. Results demonstrate significant performance disparities across locations and species-specific detection variations. Our work highlights the importance of evaluating detection algorithms across different environments for robust wildlife monitoring applications using drones.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
KerasCV and KerasNLP: Vision and Language Power-Ups
May 31, 2024
We present the Keras domain packages KerasCV and KerasNLP, extensions of the Keras API for Computer Vision and Natural Language Processing workflows, capable of running on either JAX, TensorFlow, or PyTorch. These domain packages are designed to enable fast experimentation, with a focus on ease-of-use and performance. We adopt a modular, layered design: at the library's lowest level of abstraction, we provide building blocks for creating models and data preprocessing pipelines, and at the library's highest level of abstraction, we provide pretrained ``task" models for popular architectures such as Stable Diffusion, YOLOv8, GPT2, BERT, Mistral, CLIP, Gemma, T5, etc. Task models have built-in preprocessing, pretrained weights, and can be fine-tuned on raw inputs. To enable efficient training, we support XLA compilation for all models, and run all preprocessing via a compiled graph of TensorFlow operations using the tf.data API. The libraries are fully open-source (Apache 2.0 license) and available on GitHub.
AttenCraft: Attention-guided Disentanglement of Multiple Concepts for Text-to-Image Customization
May 28, 2024



With the unprecedented performance being achieved by text-to-image (T2I) diffusion models, T2I customization further empowers users to tailor the diffusion model to new concepts absent in the pre-training dataset, termed subject-driven generation. Moreover, extracting several new concepts from a single image enables the model to learn multiple concepts, and simultaneously decreases the difficulties of training data preparation, urging the disentanglement of multiple concepts to be a new challenge. However, existing models for disentanglement commonly require pre-determined masks or retain background elements. To this end, we propose an attention-guided method, AttenCraft, for multiple concept disentanglement. In particular, our method leverages self-attention and cross-attention maps to create accurate masks for each concept within a single initialization step, omitting any required mask preparation by humans or other models. The created masks are then applied to guide the cross-attention activation of each target concept during training and achieve concept disentanglement. Additionally, we introduce Uniform sampling and Reweighted sampling schemes to alleviate the non-synchronicity of feature acquisition from different concepts, and improve generation quality. Our method outperforms baseline models in terms of image-alignment, and behaves comparably on text-alignment. Finally, we showcase the applicability of AttenCraft to more complicated settings, such as an input image containing three concepts. The project is available at https://github.com/junjie-shentu/AttenCraft.
Textual Localization: Decomposing Multi-concept Images for Subject-Driven Text-to-Image Generation
Feb 15, 2024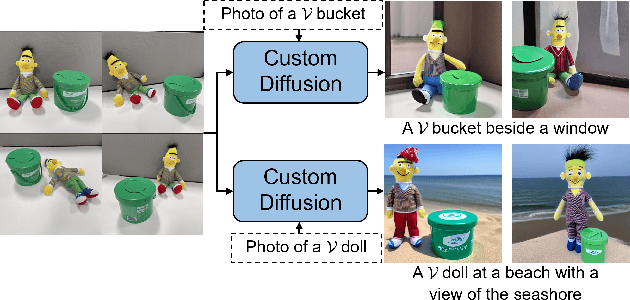

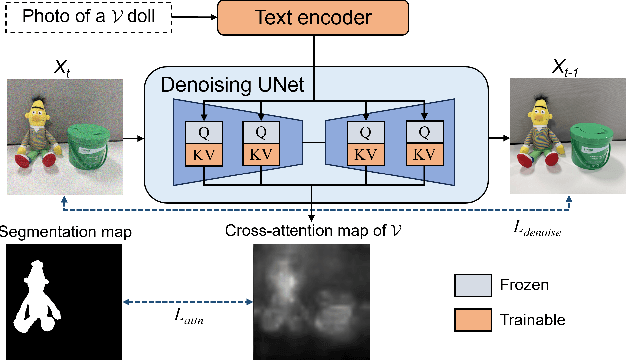
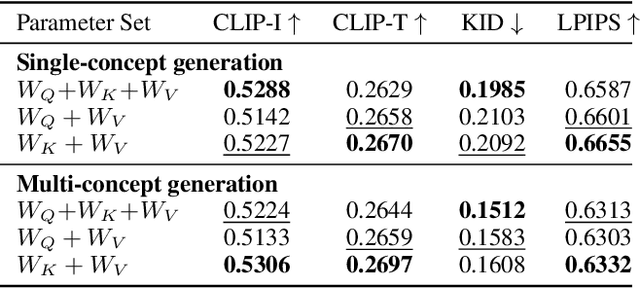
Subject-driven text-to-image diffusion models empower users to tailor the model to new concepts absent in the pre-training dataset using a few sample images. However, prevalent subject-driven models primarily rely on single-concept input images, facing challenges in specifying the target concept when dealing with multi-concept input images. To this end, we introduce a textual localized text-to-image model (Texual Localization) to handle multi-concept input images. During fine-tuning, our method incorporates a novel cross-attention guidance to decompose multiple concepts, establishing distinct connections between the visual representation of the target concept and the identifier token in the text prompt. Experimental results reveal that our method outperforms or performs comparably to the baseline models in terms of image fidelity and image-text alignment on multi-concept input images. In comparison to Custom Diffusion, our method with hard guidance achieves CLIP-I scores that are 7.04%, 8.13% higher and CLIP-T scores that are 2.22%, 5.85% higher in single-concept and multi-concept generation, respectively. Notably, our method generates cross-attention maps consistent with the target concept in the generated images, a capability absent in existing models.
Agree to Disagree: When Deep Learning Models With Identical Architectures Produce Distinct Explanations
May 14, 2021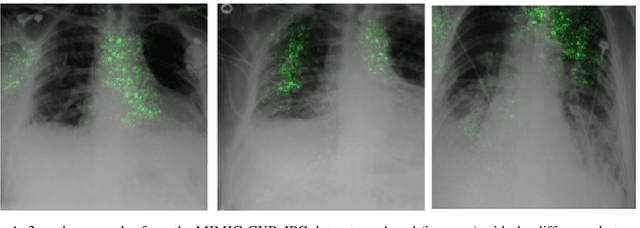
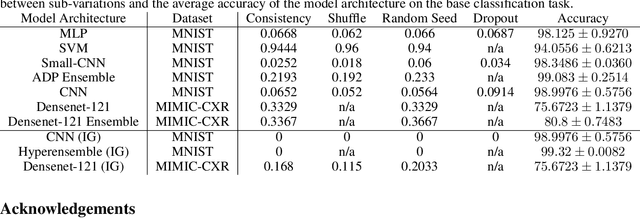
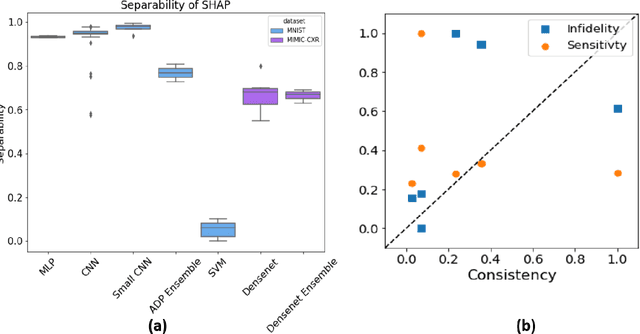
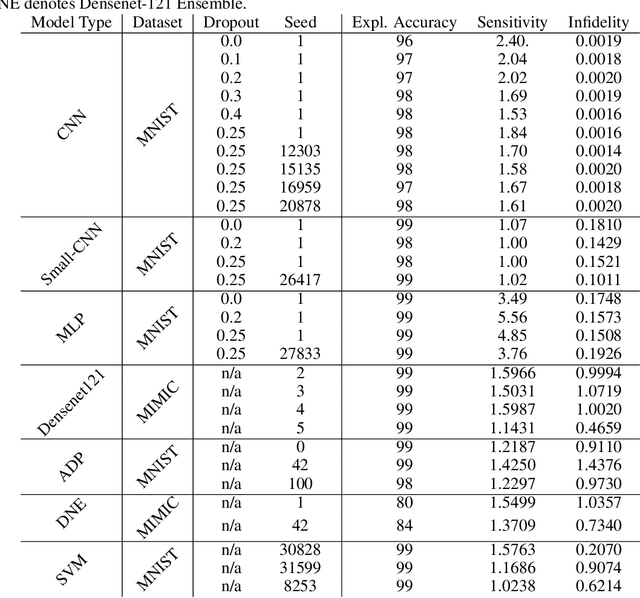
Deep Learning of neural networks has progressively become more prominent in healthcare with models reaching, or even surpassing, expert accuracy levels. However, these success stories are tainted by concerning reports on the lack of model transparency and bias against some medical conditions or patients' sub-groups. Explainable methods are considered the gateway to alleviate many of these concerns. In this study we demonstrate that the generated explanations are volatile to changes in model training that are perpendicular to the classification task and model structure. This raises further questions about trust in deep learning models for healthcare. Mainly, whether the models capture underlying causal links in the data or just rely on spurious correlations that are made visible via explanation methods. We demonstrate that the output of explainability methods on deep neural networks can vary significantly by changes of hyper-parameters, such as the random seed or how the training set is shuffled. We introduce a measure of explanation consistency which we use to highlight the identified problems on the MIMIC-CXR dataset. We find explanations of identical models but with different training setups have a low consistency: $\approx$ 33% on average. On the contrary, kernel methods are robust against any orthogonal changes, with explanation consistency at 94%. We conclude that current trends in model explanation are not sufficient to mitigate the risks of deploying models in real life healthcare applications.
Attack-agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
May 05, 2021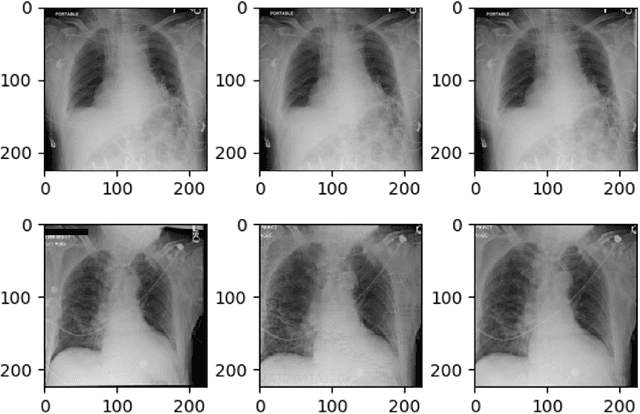

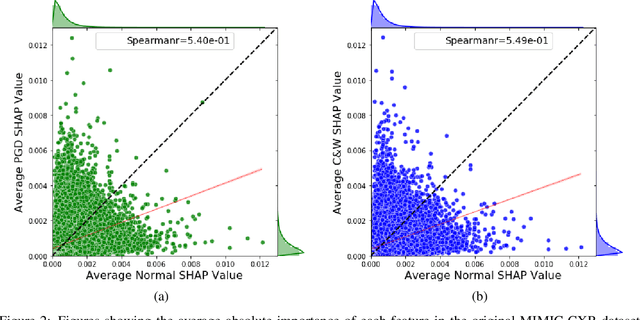

Explainable machine learning has become increasingly prevalent, especially in healthcare where explainable models are vital for ethical and trusted automated decision making. Work on the susceptibility of deep learning models to adversarial attacks has shown the ease of designing samples to mislead a model into making incorrect predictions. In this work, we propose a model agnostic explainability-based method for the accurate detection of adversarial samples on two datasets with different complexity and properties: Electronic Health Record (EHR) and chest X-ray (CXR) data. On the MIMIC-III and Henan-Renmin EHR datasets, we report a detection accuracy of 77% against the Longitudinal Adversarial Attack. On the MIMIC-CXR dataset, we achieve an accuracy of 88%; significantly improving on the state of the art of adversarial detection in both datasets by over 10% in all settings. We propose an anomaly detection based method using explainability techniques to detect adversarial samples which is able to generalise to different attack methods without a need for retraining.