 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKerasCV and KerasNLP: Vision and Language Power-Ups
May 31, 2024
We present the Keras domain packages KerasCV and KerasNLP, extensions of the Keras API for Computer Vision and Natural Language Processing workflows, capable of running on either JAX, TensorFlow, or PyTorch. These domain packages are designed to enable fast experimentation, with a focus on ease-of-use and performance. We adopt a modular, layered design: at the library's lowest level of abstraction, we provide building blocks for creating models and data preprocessing pipelines, and at the library's highest level of abstraction, we provide pretrained ``task" models for popular architectures such as Stable Diffusion, YOLOv8, GPT2, BERT, Mistral, CLIP, Gemma, T5, etc. Task models have built-in preprocessing, pretrained weights, and can be fine-tuned on raw inputs. To enable efficient training, we support XLA compilation for all models, and run all preprocessing via a compiled graph of TensorFlow operations using the tf.data API. The libraries are fully open-source (Apache 2.0 license) and available on GitHub.
DivAug: Plug-in Automated Data Augmentation with Explicit Diversity Maximization
Mar 26, 2021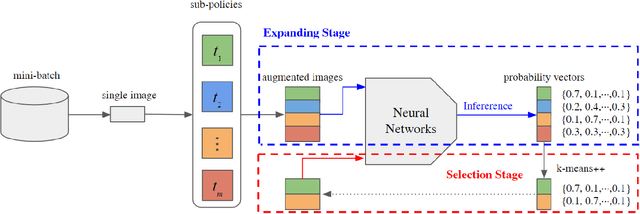

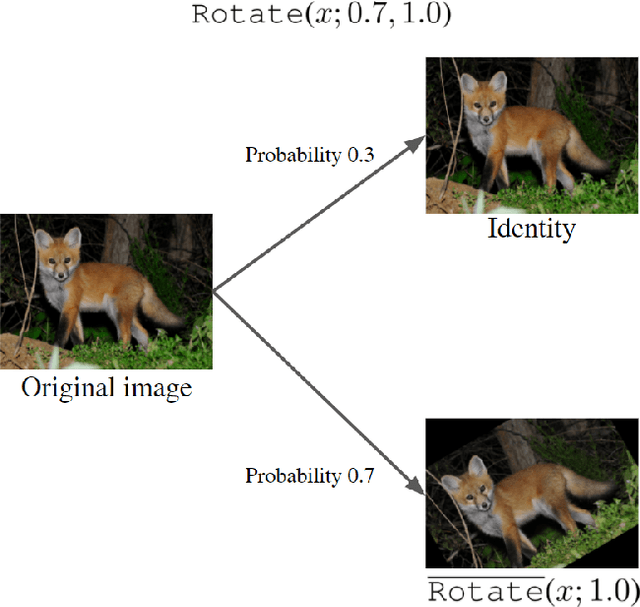
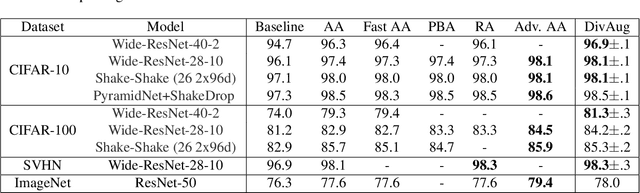
Human-designed data augmentation strategies have been replaced by automatically learned augmentation policy in the past two years. Specifically, recent work has empirically shown that the superior performance of the automated data augmentation methods stems from increasing the diversity of augmented data. However, two factors regarding the diversity of augmented data are still missing: 1) the explicit definition (and thus measurement) of diversity and 2) the quantifiable relationship between diversity and its regularization effects. To bridge this gap, we propose a diversity measure called Variance Diversity and theoretically show that the regularization effect of data augmentation is promised by Variance Diversity. We validate in experiments that the relative gain from automated data augmentation in test accuracy is highly correlated to Variance Diversity. An unsupervised sampling-based framework, DivAug, is designed to directly maximize Variance Diversity and hence strengthen the regularization effect. Without requiring a separate search process, the performance gain from DivAug is comparable with the state-of-the-art method with better efficiency. Moreover, under the semi-supervised setting, our framework can further improve the performance of semi-supervised learning algorithms when compared to RandAugment, making it highly applicable to real-world problems, where labeled data is scarce.
AutoRec: An Automated Recommender System
Jun 26, 2020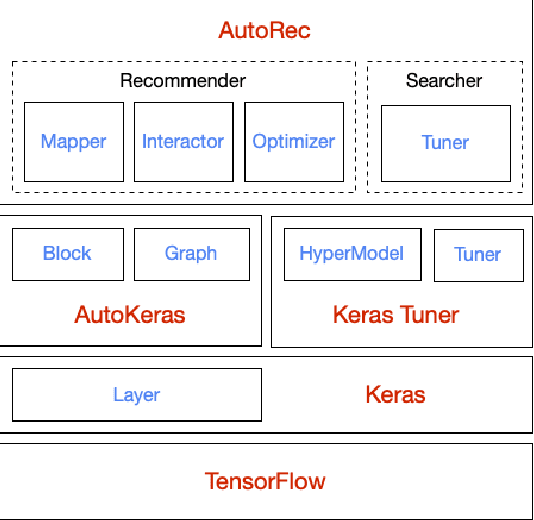
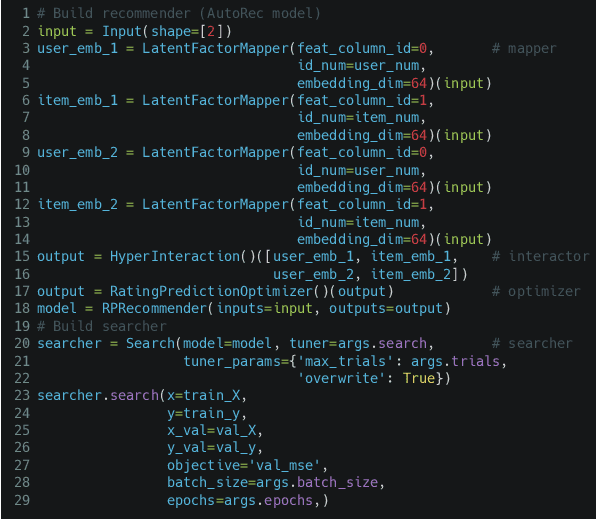
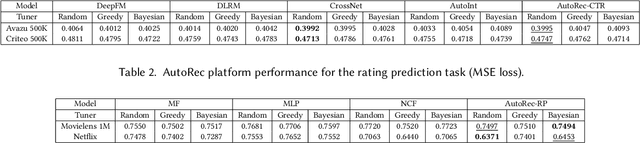
Realistic recommender systems are often required to adapt to ever-changing data and tasks or to explore different models systematically. To address the need, we present AutoRec, an open-source automated machine learning (AutoML) platform extended from the TensorFlow ecosystem and, to our knowledge, the first framework to leverage AutoML for model search and hyperparameter tuning in deep recommendation models. AutoRec also supports a highly flexible pipeline that accommodates both sparse and dense inputs, rating prediction and click-through rate (CTR) prediction tasks, and an array of recommendation models. Lastly, AutoRec provides a simple, user-friendly API. Experiments conducted on the benchmark datasets reveal AutoRec is reliable and can identify models which resemble the best model without prior knowledge.
AutoOD: Automated Outlier Detection via Curiosity-guided Search and Self-imitation Learning
Jun 19, 2020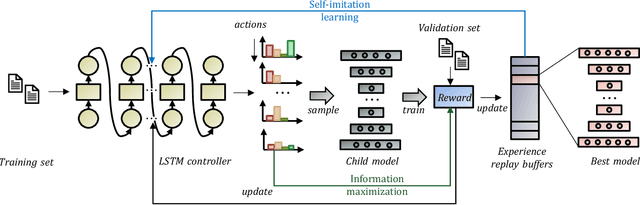
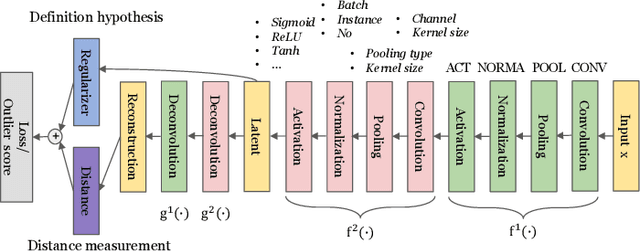
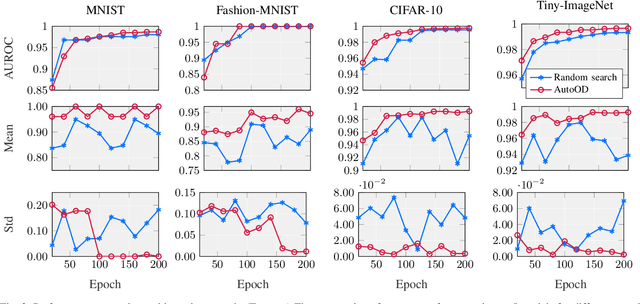
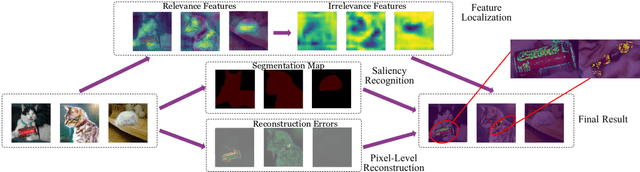
Outlier detection is an important data mining task with numerous practical applications such as intrusion detection, credit card fraud detection, and video surveillance. However, given a specific complicated task with big data, the process of building a powerful deep learning based system for outlier detection still highly relies on human expertise and laboring trials. Although Neural Architecture Search (NAS) has shown its promise in discovering effective deep architectures in various domains, such as image classification, object detection, and semantic segmentation, contemporary NAS methods are not suitable for outlier detection due to the lack of intrinsic search space, unstable search process, and low sample efficiency. To bridge the gap, in this paper, we propose AutoOD, an automated outlier detection framework, which aims to search for an optimal neural network model within a predefined search space. Specifically, we firstly design a curiosity-guided search strategy to overcome the curse of local optimality. A controller, which acts as a search agent, is encouraged to take actions to maximize the information gain about the controller's internal belief. We further introduce an experience replay mechanism based on self-imitation learning to improve the sample efficiency. Experimental results on various real-world benchmark datasets demonstrate that the deep model identified by AutoOD achieves the best performance, comparing with existing handcrafted models and traditional search methods.
Multi-Label Adversarial Perturbations
Jan 02, 2019
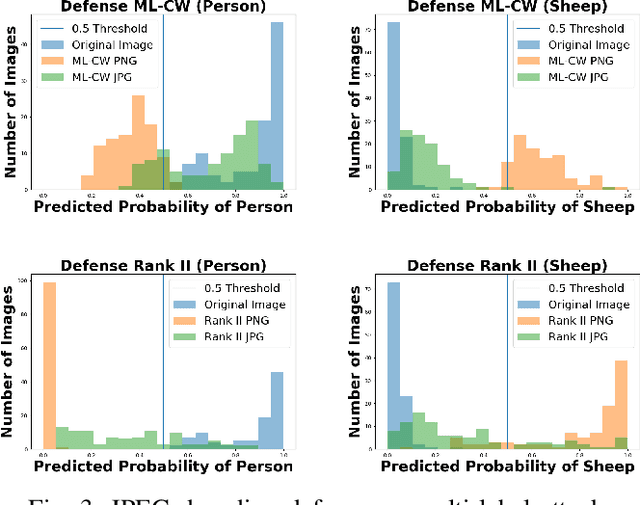
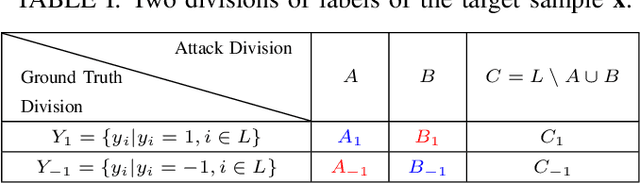

Adversarial examples are delicately perturbed inputs, which aim to mislead machine learning models towards incorrect outputs. While most of the existing work focuses on generating adversarial perturbations in multi-class classification problems, many real-world applications fall into the multi-label setting in which one instance could be associated with more than one label. For example, a spammer may generate adversarial spams with malicious advertising while maintaining the other labels such as topic labels unchanged. To analyze the vulnerability and robustness of multi-label learning models, we investigate the generation of multi-label adversarial perturbations. This is a challenging task due to the uncertain number of positive labels associated with one instance, as well as the fact that multiple labels are usually not mutually exclusive with each other. To bridge this gap, in this paper, we propose a general attacking framework targeting on multi-label classification problem and conduct a premier analysis on the perturbations for deep neural networks. Leveraging the ranking relationships among labels, we further design a ranking-based framework to attack multi-label ranking algorithms. We specify the connection between the two proposed frameworks and separately design two specific methods grounded on each of them to generate targeted multi-label perturbations. Experiments on real-world multi-label image classification and ranking problems demonstrate the effectiveness of our proposed frameworks and provide insights of the vulnerability of multi-label deep learning models under diverse targeted attacking strategies. Several interesting findings including an unpolished defensive strategy, which could potentially enhance the interpretability and robustness of multi-label deep learning models, are further presented and discussed at the end.
Auto-Keras: Efficient Neural Architecture Search with Network Morphism
Oct 03, 2018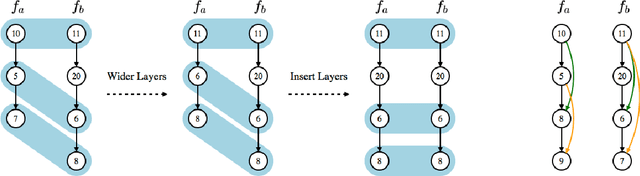
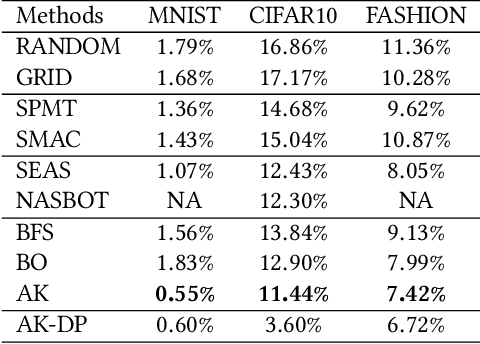
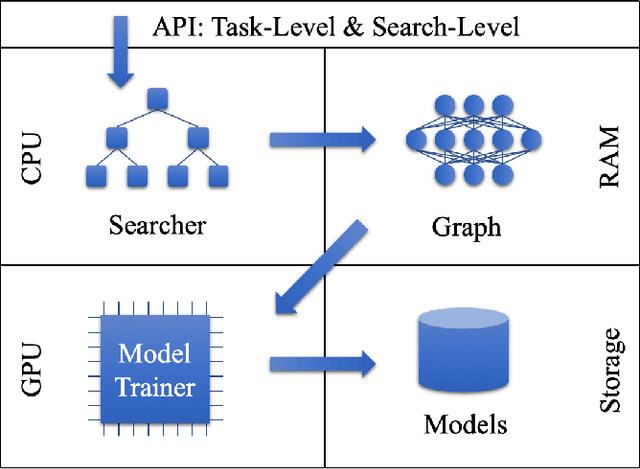
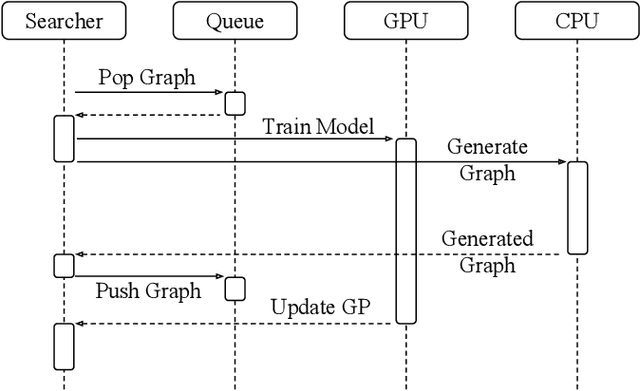
Neural architecture search (NAS) has been proposed to automatically tune deep neural networks, but existing search algorithms usually suffer from expensive computational cost. Network morphism, which keeps the functionality of a neural network while changing its neural architecture, could be helpful for NAS by enabling a more efficient training during the search. In this paper, we propose a novel framework enabling Bayesian optimization to guide the network morphism for efficient neural architecture search by introducing a neural network kernel and a tree-structured acquisition function optimization algorithm, which more efficiently explores the search space. Intensive experiments have been done to demonstrate the superior performance of the developed framework over the state-of-the-art methods. Moreover, we build an open-source AutoML system on our method, namely Auto-Keras. The system runs in parallel on CPU and GPU, with an adaptive search strategy for different GPU memory limits.