 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatQuant: Flatness Matters for LLM Quantization
Oct 12, 2024



Recently, quantization has been widely used for the compression and acceleration of large language models~(LLMs). Due to the outliers in LLMs, it is crucial to flatten weights and activations to minimize quantization error with the equally spaced quantization points. Prior research explores various pre-quantization transformations to suppress outliers, such as per-channel scaling and Hadamard transformation. However, we observe that these transformed weights and activations can still remain steep and outspread. In this paper, we propose FlatQuant (Fast and Learnable Affine Transformation), a new post-training quantization approach to enhance flatness of weights and activations. Our approach identifies optimal affine transformations tailored to each linear layer, calibrated in hours via a lightweight objective. To reduce runtime overhead, we apply Kronecker decomposition to the transformation matrices, and fuse all operations in FlatQuant into a single kernel. Extensive experiments show that FlatQuant sets up a new state-of-the-art quantization benchmark. For instance, it achieves less than $\textbf{1}\%$ accuracy drop for W4A4 quantization on the LLaMA-3-70B model, surpassing SpinQuant by $\textbf{7.5}\%$. For inference latency, FlatQuant reduces the slowdown induced by pre-quantization transformation from 0.26x of QuaRot to merely $\textbf{0.07x}$, bringing up to $\textbf{2.3x}$ speedup for prefill and $\textbf{1.7x}$ speedup for decoding, respectively. Code is available at: \url{https://github.com/ruikangliu/FlatQuant}.
Hyperspectral Unmixing Under Endmember Variability: A Variational Inference Framework
Jul 20, 2024



This work proposes a variational inference (VI) framework for hyperspectral unmixing in the presence of endmember variability (HU-EV). An EV-accounted noisy linear mixture model (LMM) is considered, and the presence of outliers is also incorporated into the model. Following the marginalized maximum likelihood (MML) principle, a VI algorithmic structure is designed for probabilistic inference for HU-EV. Specifically, a patch-wise static endmember assumption is employed to exploit spatial smoothness and to try to overcome the ill-posed nature of the HU-EV problem. The design facilitates lightweight, continuous optimization-based updates under a variety of endmember priors. Some of the priors, such as the Beta prior, were previously used under computationally heavy, sampling-based probabilistic HU-EV methods. The effectiveness of the proposed framework is demonstrated through synthetic, semi-real, and real-data experiments.
IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact
Mar 02, 2024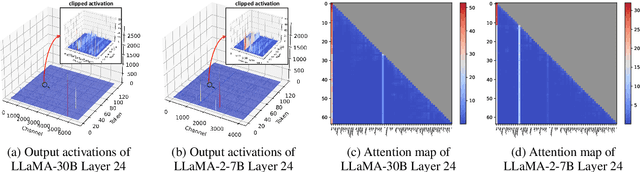
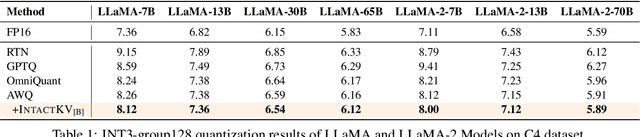

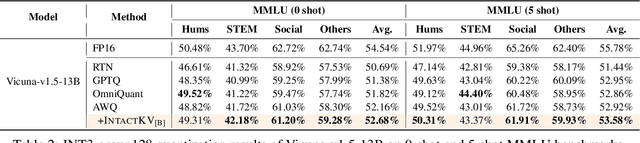
Large language models (LLMs) excel in natural language processing but demand intensive computation. To mitigate this, various quantization methods have been explored, yet they compromise LLM performance. This paper unveils a previously overlooked type of outlier in LLMs. Such outliers are found to allocate most of the attention scores on initial tokens of input, termed as pivot tokens, which is crucial to the performance of quantized LLMs. Given that, we propose IntactKV to generate the KV cache of pivot tokens losslessly from the full-precision model. The approach is simple and easy to combine with existing quantization solutions. Besides, IntactKV can be calibrated as additional LLM parameters to boost the quantized LLMs further. Mathematical analysis also proves that IntactKV effectively reduces the upper bound of quantization error. Empirical results show that IntactKV brings consistent improvement and achieves lossless weight-only INT4 quantization on various downstream tasks, leading to the new state-of-the-art for LLM quantization.
Wisdom of Committee: Distilling from Foundation Model to Specialized Application Model
Feb 27, 2024Recent advancements in foundation models have yielded impressive performance across a wide range of tasks. Meanwhile, for specific applications, practitioners have been developing specialized application models. To enjoy the benefits of both kinds of models, one natural path is to transfer the knowledge in foundation models into specialized application models, which are generally more efficient for serving. Techniques from knowledge distillation may be applied here, where the application model learns to mimic the foundation model. However, specialized application models and foundation models have substantial gaps in capacity, employing distinct architectures, using different input features from different modalities, and being optimized on different distributions. These differences in model characteristics lead to significant challenges for distillation methods. In this work, we propose creating a teaching committee comprising both foundation model teachers and complementary teachers. Complementary teachers possess model characteristics akin to the student's, aiming to bridge the gap between the foundation model and specialized application models for a smoother knowledge transfer. Further, to accommodate the dissimilarity among the teachers in the committee, we introduce DiverseDistill, which allows the student to understand the expertise of each teacher and extract task knowledge. Our evaluations demonstrate that adding complementary teachers enhances student performance. Finally, DiverseDistill consistently outperforms baseline distillation methods, regardless of the teacher choices, resulting in significantly improved student performance.
Multilayer Simplex-structured Matrix Factorization for Hyperspectral Unmixing with Endmember Variability
Jan 26, 2024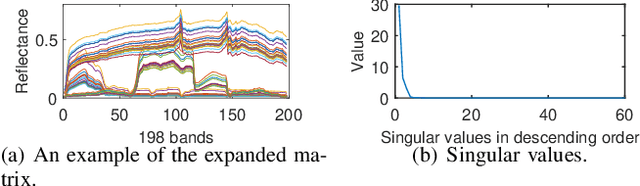
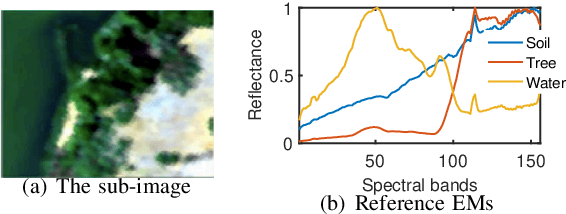
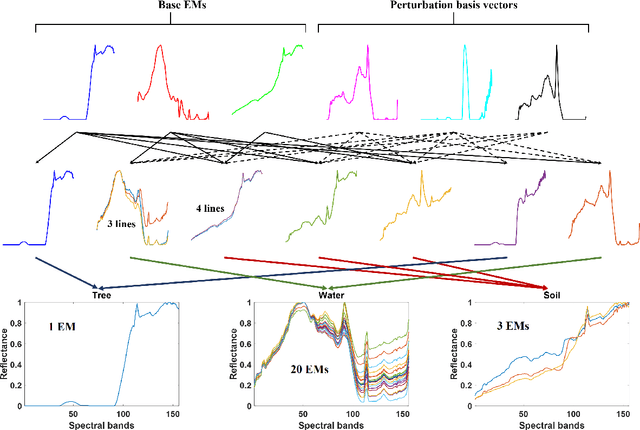
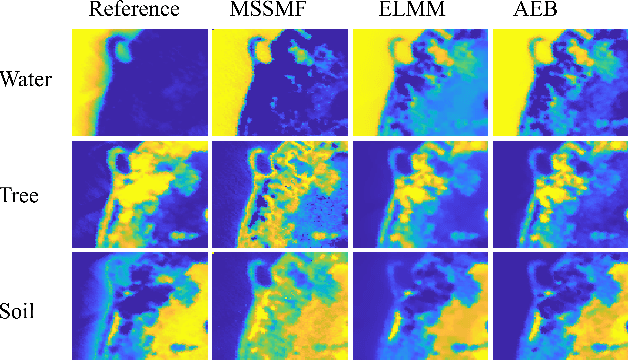
Given a hyperspectral image, the problem of hyperspectral unmixing (HU) is to identify the endmembers (or materials) and the abundance (or endmembers' contributions on pixels) that underlie the image. HU can be seen as a matrix factorization problem with a simplex structure in the abundance matrix factor. In practice, hyperspectral images may exhibit endmember variability (EV) effects -- the endmember matrix factor varies from one pixel to another. In this paper we consider a multilayer simplex-structured matrix factorization model to account for the EV effects. Our multilayer model is based on the postulate that if we arrange the varied endmembers as an expanded endmember matrix, that matrix exhibits a low-rank structure. A variational inference-based maximum-likelihood estimation method is employed to tackle the multilayer factorization problem. Simulation results are provided to demonstrate the performance of our multilayer factorization method.
Value of Exploration: Measurements, Findings and Algorithms
May 12, 2023



Effective exploration is believed to positively influence the long-term user experience on recommendation platforms. Determining its exact benefits, however, has been challenging. Regular A/B tests on exploration often measure neutral or even negative engagement metrics while failing to capture its long-term benefits. To address this, we present a systematic study to formally quantify the value of exploration by examining its effects on the content corpus, a key entity in the recommender system that directly affects user experiences. Specifically, we introduce new metrics and the associated experiment design to measure the benefit of exploration on the corpus change, and further connect the corpus change to the long-term user experience. Furthermore, we investigate the possibility of introducing the Neural Linear Bandit algorithm to build an exploration-based ranking system, and use it as the backbone algorithm for our case study. We conduct extensive live experiments on a large-scale commercial recommendation platform that serves billions of users to validate the new experiment designs, quantify the long-term values of exploration, and to verify the effectiveness of the adopted neural linear bandit algorithm for exploration.
Learning Disentangled Representations for Time Series
May 21, 2021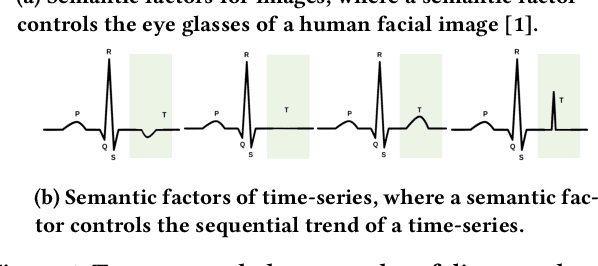
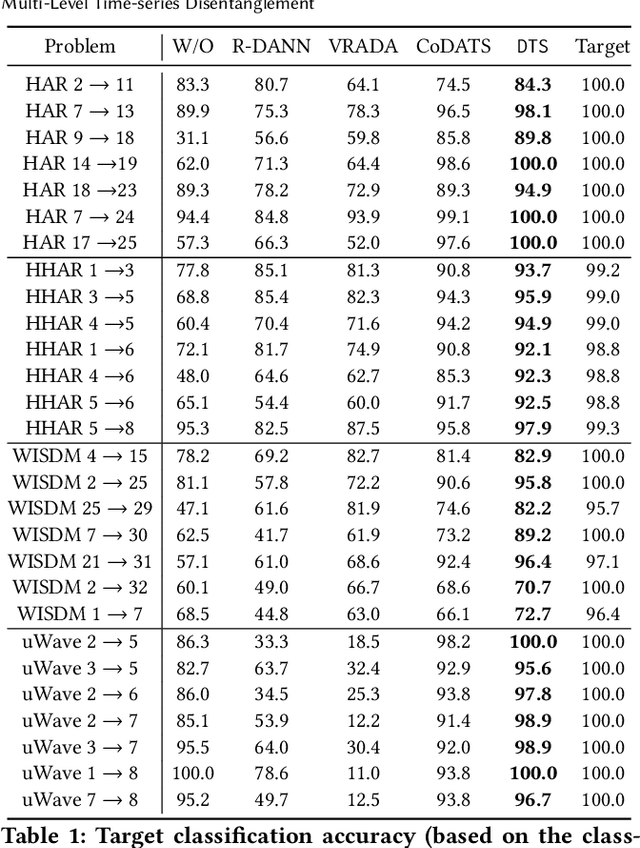
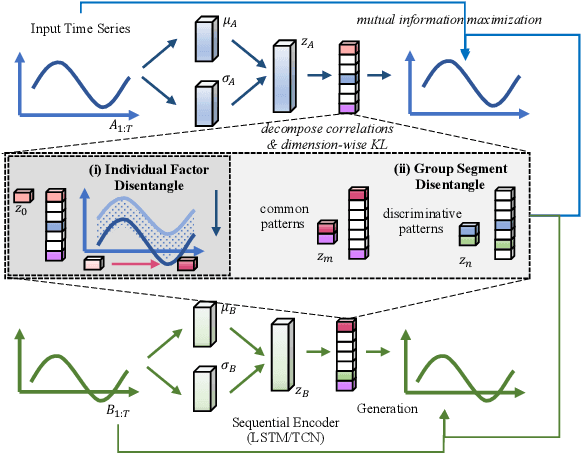
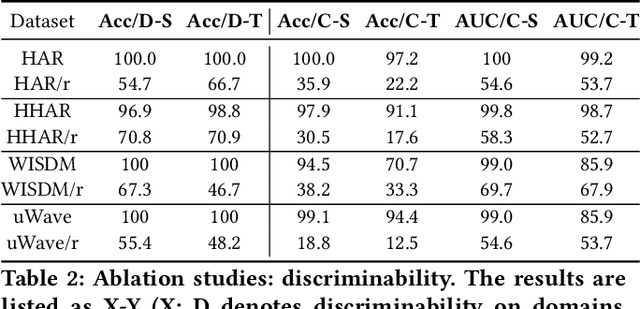
Time-series representation learning is a fundamental task for time-series analysis. While significant progress has been made to achieve accurate representations for downstream applications, the learned representations often lack interpretability and do not expose semantic meanings. Different from previous efforts on the entangled feature space, we aim to extract the semantic-rich temporal correlations in the latent interpretable factorized representation of the data. Motivated by the success of disentangled representation learning in computer vision, we study the possibility of learning semantic-rich time-series representations, which remains unexplored due to three main challenges: 1) sequential data structure introduces complex temporal correlations and makes the latent representations hard to interpret, 2) sequential models suffer from KL vanishing problem, and 3) interpretable semantic concepts for time-series often rely on multiple factors instead of individuals. To bridge the gap, we propose Disentangle Time Series (DTS), a novel disentanglement enhancement framework for sequential data. Specifically, to generate hierarchical semantic concepts as the interpretable and disentangled representation of time-series, DTS introduces multi-level disentanglement strategies by covering both individual latent factors and group semantic segments. We further theoretically show how to alleviate the KL vanishing problem: DTS introduces a mutual information maximization term, while preserving a heavier penalty on the total correlation and the dimension-wise KL to keep the disentanglement property. Experimental results on various real-world benchmark datasets demonstrate that the representations learned by DTS achieve superior performance in downstream applications, with high interpretability of semantic concepts.
Probabilistic Simplex Component Analysis
Mar 18, 2021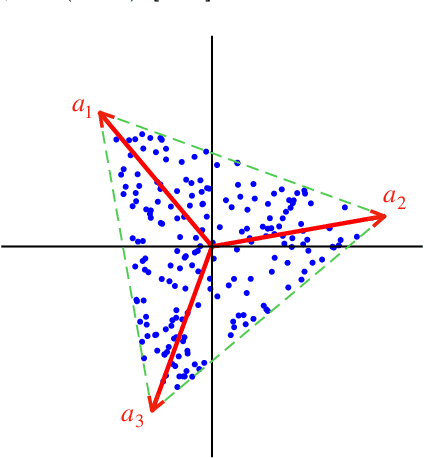
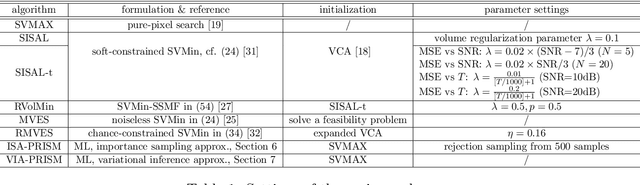
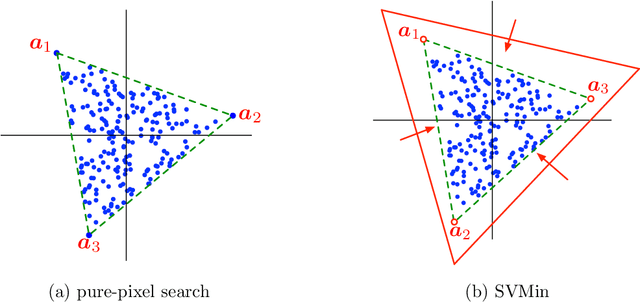

This study presents PRISM, a probabilistic simplex component analysis approach to identifying the vertices of a data-circumscribing simplex from data. The problem has a rich variety of applications, the most notable being hyperspectral unmixing in remote sensing and non-negative matrix factorization in machine learning. PRISM uses a simple probabilistic model, namely, uniform simplex data distribution and additive Gaussian noise, and it carries out inference by maximum likelihood. The inference model is sound in the sense that the vertices are provably identifiable under some assumptions, and it suggests that PRISM can be effective in combating noise when the number of data points is large. PRISM has strong, but hidden, relationships with simplex volume minimization, a powerful geometric approach for the same problem. We study these fundamental aspects, and we also consider algorithmic schemes based on importance sampling and variational inference. In particular, the variational inference scheme is shown to resemble a matrix factorization problem with a special regularizer, which draws an interesting connection to the matrix factorization approach. Numerical results are provided to demonstrate the potential of PRISM.
AutoOD: Automated Outlier Detection via Curiosity-guided Search and Self-imitation Learning
Jun 19, 2020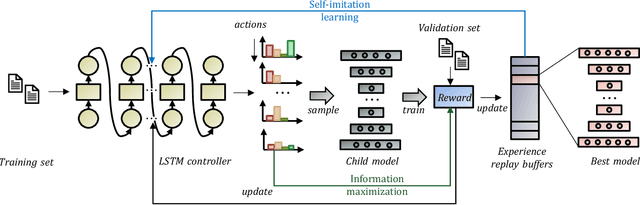
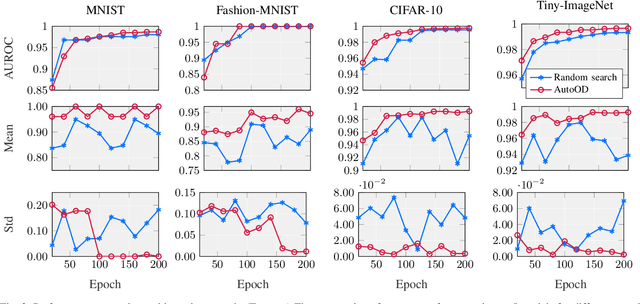
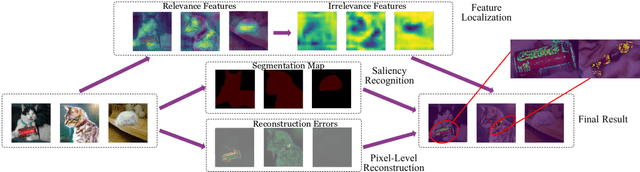
Outlier detection is an important data mining task with numerous practical applications such as intrusion detection, credit card fraud detection, and video surveillance. However, given a specific complicated task with big data, the process of building a powerful deep learning based system for outlier detection still highly relies on human expertise and laboring trials. Although Neural Architecture Search (NAS) has shown its promise in discovering effective deep architectures in various domains, such as image classification, object detection, and semantic segmentation, contemporary NAS methods are not suitable for outlier detection due to the lack of intrinsic search space, unstable search process, and low sample efficiency. To bridge the gap, in this paper, we propose AutoOD, an automated outlier detection framework, which aims to search for an optimal neural network model within a predefined search space. Specifically, we firstly design a curiosity-guided search strategy to overcome the curse of local optimality. A controller, which acts as a search agent, is encouraged to take actions to maximize the information gain about the controller's internal belief. We further introduce an experience replay mechanism based on self-imitation learning to improve the sample efficiency. Experimental results on various real-world benchmark datasets demonstrate that the deep model identified by AutoOD achieves the best performance, comparing with existing handcrafted models and traditional search methods.
Mitigating Gender Bias in Captioning Systems
Jun 15, 2020
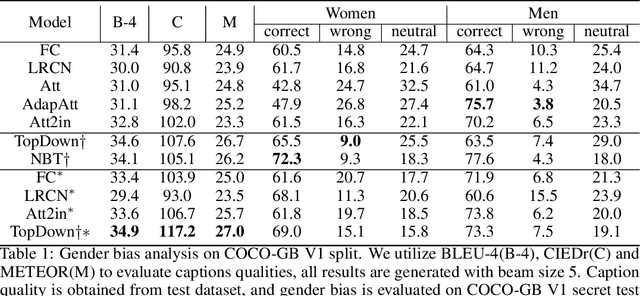
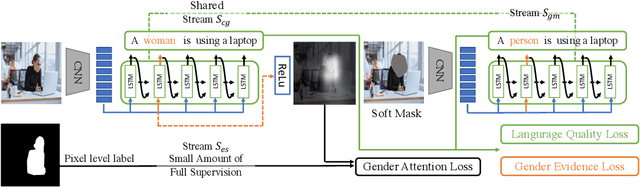
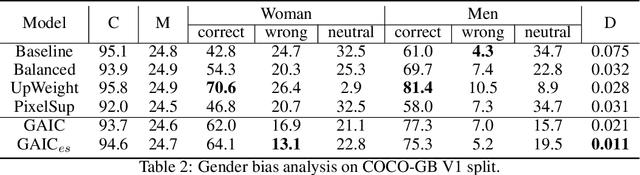
Recent studies have shown that captioning datasets, such as the COCO dataset, may contain severe social bias which could potentially lead to unintentional discrimination in learning models. In this work, we specifically focus on the gender bias problem. The existing dataset fails to quantify bias because models that intrinsically memorize gender bias from training data could still achieve a competitive performance on the biased test dataset. To bridge the gap, we create two new splits: COCO-GB v1 and v2 to quantify the inherent gender bias which could be learned by models. Several widely used baselines are evaluated on our new settings, and experimental results indicate that most models learn gender bias from the training data, leading to an undesirable gender prediction error towards women. To overcome the unwanted bias, we propose a novel Guided Attention Image Captioning model (GAIC) which provides self-guidance on visual attention to encourage the model to explore correct gender visual evidence. Experimental results validate that GAIC can significantly reduce gender prediction error, with a competitive caption quality. Our codes and the designed benchmark datasets are available at https://github.com/CaptionGenderBias2020.