 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
ACT: Automated Constraint Targeting for Multi-Objective Recommender Systems
Sep 03, 2025Recommender systems often must maximize a primary objective while ensuring secondary ones satisfy minimum thresholds, or "guardrails." This is critical for maintaining a consistent user experience and platform ecosystem, but enforcing these guardrails despite orthogonal system changes is challenging and often requires manual hyperparameter tuning. We introduce the Automated Constraint Targeting (ACT) framework, which automatically finds the minimal set of hyperparameter changes needed to satisfy these guardrails. ACT uses an offline pairwise evaluation on unbiased data to find solutions and continuously retrains to adapt to system and user behavior changes. We empirically demonstrate its efficacy and describe its deployment in a large-scale production environment.
Learned Ranking Function: From Short-term Behavior Predictions to Long-term User Satisfaction
Aug 12, 2024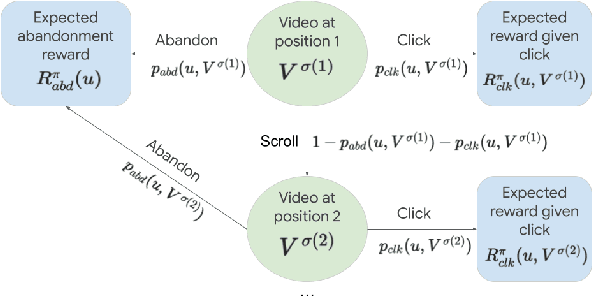
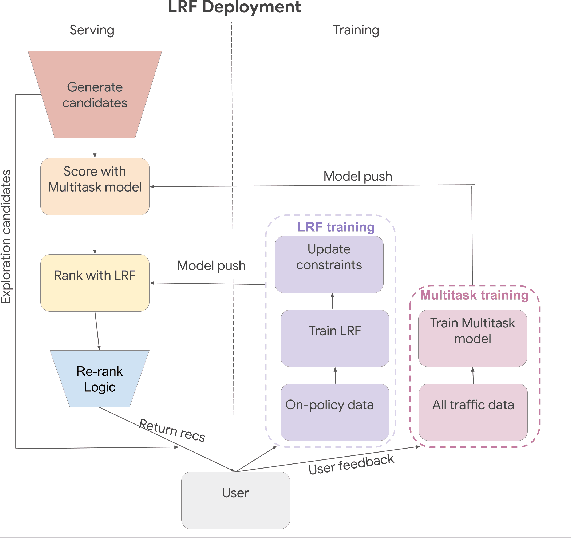
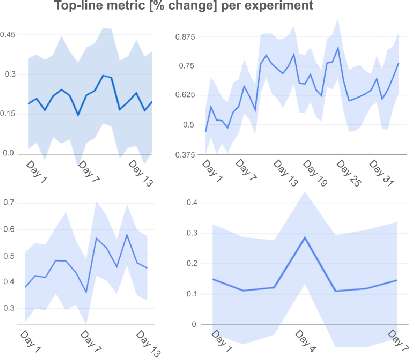
We present the Learned Ranking Function (LRF), a system that takes short-term user-item behavior predictions as input and outputs a slate of recommendations that directly optimizes for long-term user satisfaction. Most previous work is based on optimizing the hyperparameters of a heuristic function. We propose to model the problem directly as a slate optimization problem with the objective of maximizing long-term user satisfaction. We also develop a novel constraint optimization algorithm that stabilizes objective trade-offs for multi-objective optimization. We evaluate our approach with live experiments and describe its deployment on YouTube.
Aligning Large Language Models with Recommendation Knowledge
Mar 30, 2024



Large language models (LLMs) have recently been used as backbones for recommender systems. However, their performance often lags behind conventional methods in standard tasks like retrieval. We attribute this to a mismatch between LLMs' knowledge and the knowledge crucial for effective recommendations. While LLMs excel at natural language reasoning, they cannot model complex user-item interactions inherent in recommendation tasks. We propose bridging the knowledge gap and equipping LLMs with recommendation-specific knowledge to address this. Operations such as Masked Item Modeling (MIM) and Bayesian Personalized Ranking (BPR) have found success in conventional recommender systems. Inspired by this, we simulate these operations through natural language to generate auxiliary-task data samples that encode item correlations and user preferences. Fine-tuning LLMs on such auxiliary-task data samples and incorporating more informative recommendation-task data samples facilitates the injection of recommendation-specific knowledge into LLMs. Extensive experiments across retrieval, ranking, and rating prediction tasks on LLMs such as FLAN-T5-Base and FLAN-T5-XL show the effectiveness of our technique in domains such as Amazon Toys & Games, Beauty, and Sports & Outdoors. Notably, our method outperforms conventional and LLM-based baselines, including the current SOTA, by significant margins in retrieval, showcasing its potential for enhancing recommendation quality.
Online Matching: A Real-time Bandit System for Large-scale Recommendations
Jul 29, 2023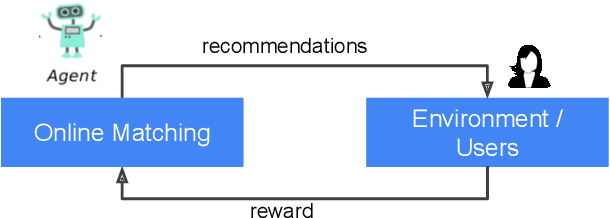

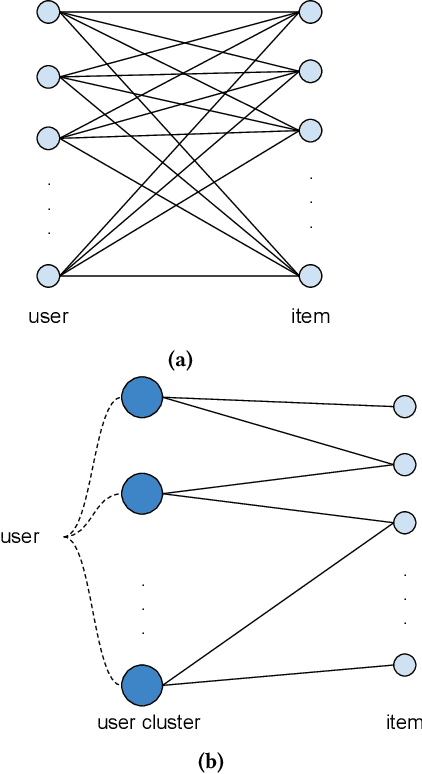

The last decade has witnessed many successes of deep learning-based models for industry-scale recommender systems. These models are typically trained offline in a batch manner. While being effective in capturing users' past interactions with recommendation platforms, batch learning suffers from long model-update latency and is vulnerable to system biases, making it hard to adapt to distribution shift and explore new items or user interests. Although online learning-based approaches (e.g., multi-armed bandits) have demonstrated promising theoretical results in tackling these challenges, their practical real-time implementation in large-scale recommender systems remains limited. First, the scalability of online approaches in servicing a massive online traffic while ensuring timely updates of bandit parameters poses a significant challenge. Additionally, exploring uncertainty in recommender systems can easily result in unfavorable user experience, highlighting the need for devising intricate strategies that effectively balance the trade-off between exploitation and exploration. In this paper, we introduce Online Matching: a scalable closed-loop bandit system learning from users' direct feedback on items in real time. We present a hybrid "offline + online" approach for constructing this system, accompanied by a comprehensive exposition of the end-to-end system architecture. We propose Diag-LinUCB -- a novel extension of the LinUCB algorithm -- to enable distributed updates of bandits parameter in a scalable and timely manner. We conduct live experiments in YouTube and show that Online Matching is able to enhance the capabilities of fresh content discovery and item exploration in the present platform.
Better Generalization with Semantic IDs: A case study in Ranking for Recommendations
Jun 13, 2023Training good representations for items is critical in recommender models. Typically, an item is assigned a unique randomly generated ID, and is commonly represented by learning an embedding corresponding to the value of the random ID. Although widely used, this approach have limitations when the number of items are large and items are power-law distributed -- typical characteristics of real-world recommendation systems. This leads to the item cold-start problem, where the model is unable to make reliable inferences for tail and previously unseen items. Removing these ID features and their learned embeddings altogether to combat cold-start issue severely degrades the recommendation quality. Content-based item embeddings are more reliable, but they are expensive to store and use, particularly for users' past item interaction sequence. In this paper, we use Semantic IDs, a compact discrete item representations learned from content embeddings using RQ-VAE that captures hierarchy of concepts in items. We showcase how we use them as a replacement of item IDs in a resource-constrained ranking model used in an industrial-scale video sharing platform. Moreover, we show how Semantic IDs improves the generalization ability of our system, without sacrificing top-level metrics.
Value of Exploration: Measurements, Findings and Algorithms
May 12, 2023



Effective exploration is believed to positively influence the long-term user experience on recommendation platforms. Determining its exact benefits, however, has been challenging. Regular A/B tests on exploration often measure neutral or even negative engagement metrics while failing to capture its long-term benefits. To address this, we present a systematic study to formally quantify the value of exploration by examining its effects on the content corpus, a key entity in the recommender system that directly affects user experiences. Specifically, we introduce new metrics and the associated experiment design to measure the benefit of exploration on the corpus change, and further connect the corpus change to the long-term user experience. Furthermore, we investigate the possibility of introducing the Neural Linear Bandit algorithm to build an exploration-based ranking system, and use it as the backbone algorithm for our case study. We conduct extensive live experiments on a large-scale commercial recommendation platform that serves billions of users to validate the new experiment designs, quantify the long-term values of exploration, and to verify the effectiveness of the adopted neural linear bandit algorithm for exploration.
Recommender Systems with Generative Retrieval
May 08, 2023Modern recommender systems leverage large-scale retrieval models consisting of two stages: training a dual-encoder model to embed queries and candidates in the same space, followed by an Approximate Nearest Neighbor (ANN) search to select top candidates given a query's embedding. In this paper, we propose a new single-stage paradigm: a generative retrieval model which autoregressively decodes the identifiers for the target candidates in one phase. To do this, instead of assigning randomly generated atomic IDs to each item, we generate Semantic IDs: a semantically meaningful tuple of codewords for each item that serves as its unique identifier. We use a hierarchical method called RQ-VAE to generate these codewords. Once we have the Semantic IDs for all the items, a Transformer based sequence-to-sequence model is trained to predict the Semantic ID of the next item. Since this model predicts the tuple of codewords identifying the next item directly in an autoregressive manner, it can be considered a generative retrieval model. We show that our recommender system trained in this new paradigm improves the results achieved by current SOTA models on the Amazon dataset. Moreover, we demonstrate that the sequence-to-sequence model coupled with hierarchical Semantic IDs offers better generalization and hence improves retrieval of cold-start items for recommendations.
Simpson's Paradox in Recommender Fairness: Reconciling differences between per-user and aggregated evaluations
Oct 14, 2022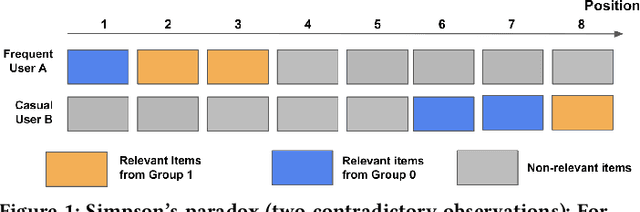
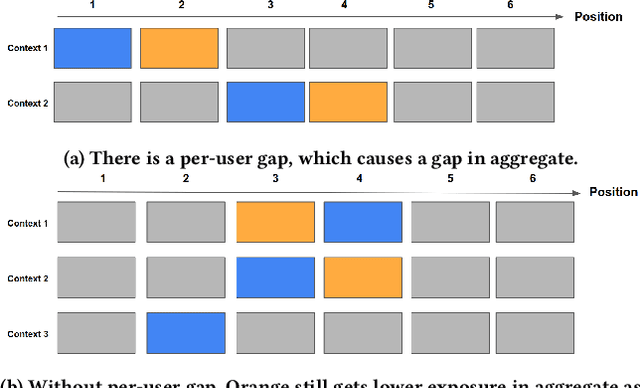
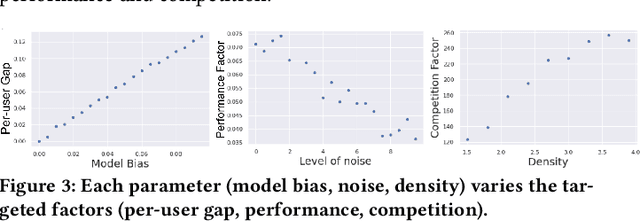
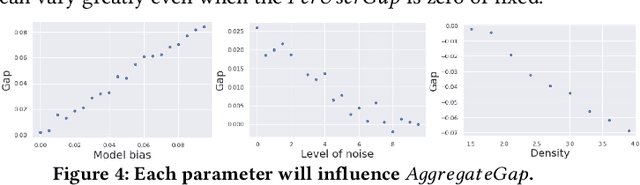
There has been a flurry of research in recent years on notions of fairness in ranking and recommender systems, particularly on how to evaluate if a recommender allocates exposure equally across groups of relevant items (also known as provider fairness). While this research has laid an important foundation, it gave rise to different approaches depending on whether relevant items are compared per-user/per-query or aggregated across users. Despite both being established and intuitive, we discover that these two notions can lead to opposite conclusions, a form of Simpson's Paradox. We reconcile these notions and show that the tension is due to differences in distributions of users where items are relevant, and break down the important factors of the user's recommendations. Based on this new understanding, practitioners might be interested in either notions, but might face challenges with the per-user metric due to partial observability of the relevance and user satisfaction, typical in real-world recommenders. We describe a technique based on distribution matching to estimate it in such a scenario. We demonstrate on simulated and real-world recommender data the effectiveness and usefulness of such an approach.
Fairness in Recommendation Ranking through Pairwise Comparisons
Mar 02, 2019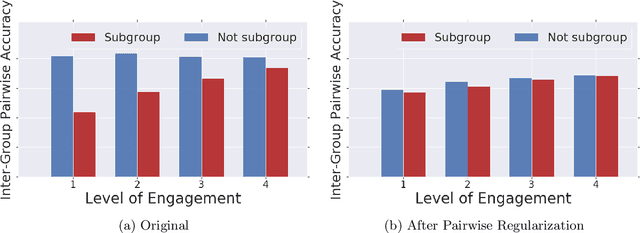

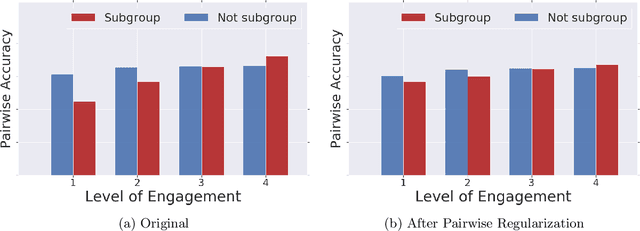
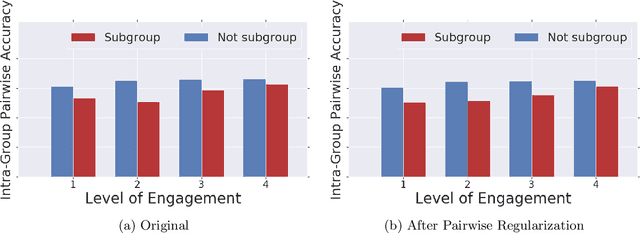
Recommender systems are one of the most pervasive applications of machine learning in industry, with many services using them to match users to products or information. As such it is important to ask: what are the possible fairness risks, how can we quantify them, and how should we address them? In this paper we offer a set of novel metrics for evaluating algorithmic fairness concerns in recommender systems. In particular we show how measuring fairness based on pairwise comparisons from randomized experiments provides a tractable means to reason about fairness in rankings from recommender systems. Building on this metric, we offer a new regularizer to encourage improving this metric during model training and thus improve fairness in the resulting rankings. We apply this pairwise regularization to a large-scale, production recommender system and show that we are able to significantly improve the system's pairwise fairness.