 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Simpson's Paradox in Recommender Fairness: Reconciling differences between per-user and aggregated evaluations
Oct 14, 2022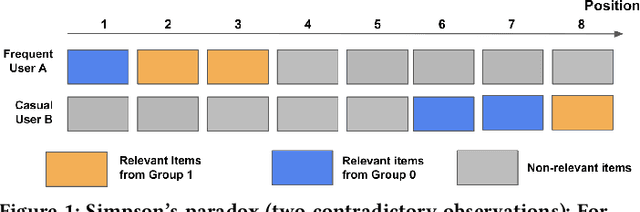
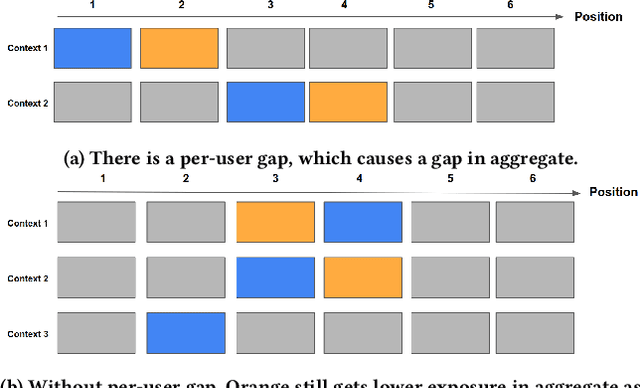
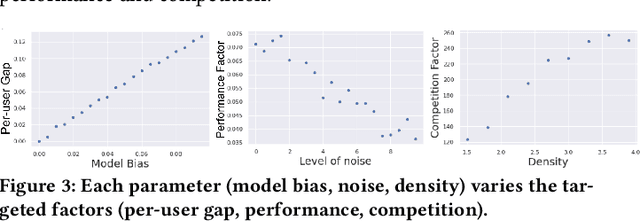
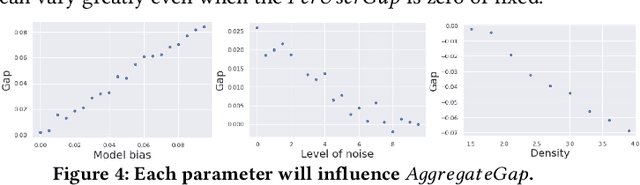
There has been a flurry of research in recent years on notions of fairness in ranking and recommender systems, particularly on how to evaluate if a recommender allocates exposure equally across groups of relevant items (also known as provider fairness). While this research has laid an important foundation, it gave rise to different approaches depending on whether relevant items are compared per-user/per-query or aggregated across users. Despite both being established and intuitive, we discover that these two notions can lead to opposite conclusions, a form of Simpson's Paradox. We reconcile these notions and show that the tension is due to differences in distributions of users where items are relevant, and break down the important factors of the user's recommendations. Based on this new understanding, practitioners might be interested in either notions, but might face challenges with the per-user metric due to partial observability of the relevance and user satisfaction, typical in real-world recommenders. We describe a technique based on distribution matching to estimate it in such a scenario. We demonstrate on simulated and real-world recommender data the effectiveness and usefulness of such an approach.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022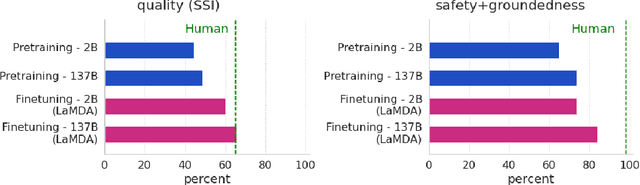
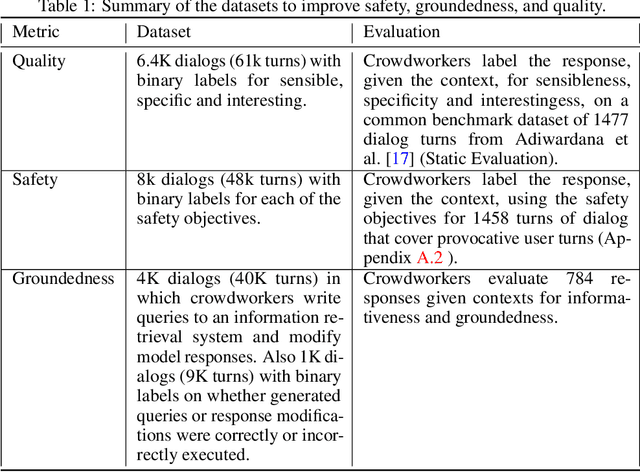
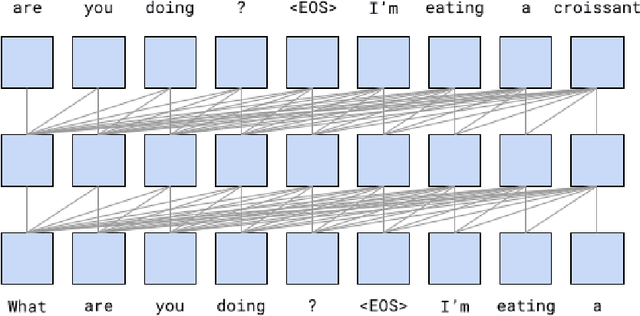

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Re-imagining Algorithmic Fairness in India and Beyond
Jan 27, 2021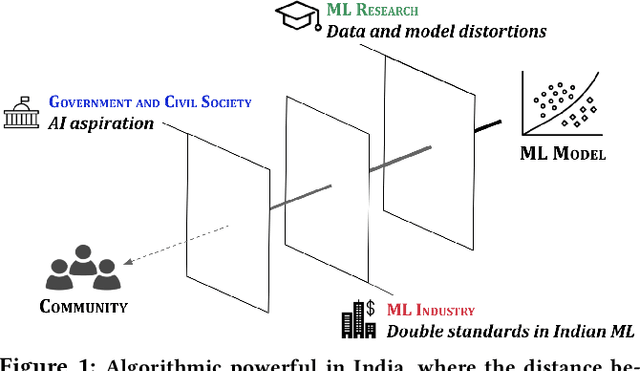

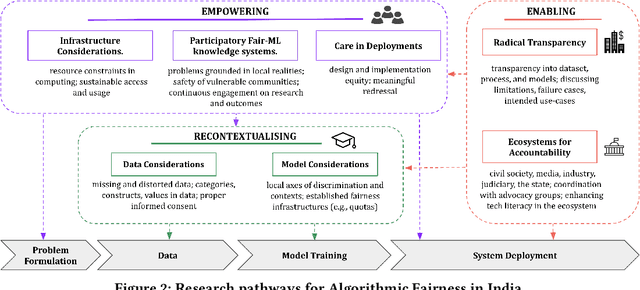
Conventional algorithmic fairness is West-centric, as seen in its sub-groups, values, and methods. In this paper, we de-center algorithmic fairness and analyse AI power in India. Based on 36 qualitative interviews and a discourse analysis of algorithmic deployments in India, we find that several assumptions of algorithmic fairness are challenged. We find that in India, data is not always reliable due to socio-economic factors, ML makers appear to follow double standards, and AI evokes unquestioning aspiration. We contend that localising model fairness alone can be window dressing in India, where the distance between models and oppressed communities is large. Instead, we re-imagine algorithmic fairness in India and provide a roadmap to re-contextualise data and models, empower oppressed communities, and enable Fair-ML ecosystems.
Fairness in Recommendation Ranking through Pairwise Comparisons
Mar 02, 2019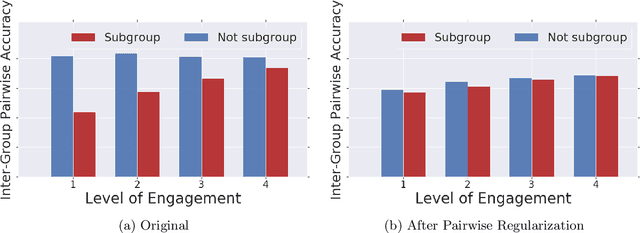

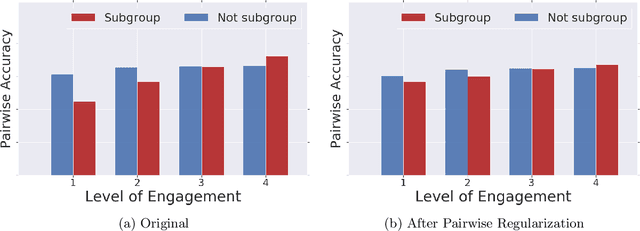
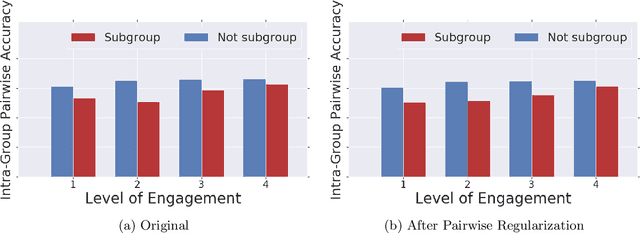
Recommender systems are one of the most pervasive applications of machine learning in industry, with many services using them to match users to products or information. As such it is important to ask: what are the possible fairness risks, how can we quantify them, and how should we address them? In this paper we offer a set of novel metrics for evaluating algorithmic fairness concerns in recommender systems. In particular we show how measuring fairness based on pairwise comparisons from randomized experiments provides a tractable means to reason about fairness in rankings from recommender systems. Building on this metric, we offer a new regularizer to encourage improving this metric during model training and thus improve fairness in the resulting rankings. We apply this pairwise regularization to a large-scale, production recommender system and show that we are able to significantly improve the system's pairwise fairness.
Putting Fairness Principles into Practice: Challenges, Metrics, and Improvements
Jan 14, 2019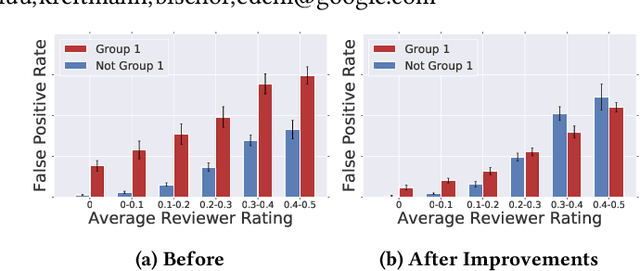
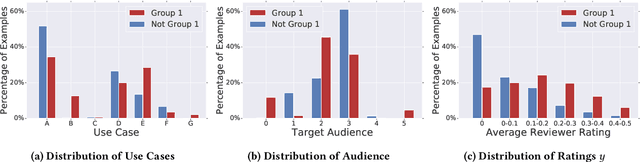

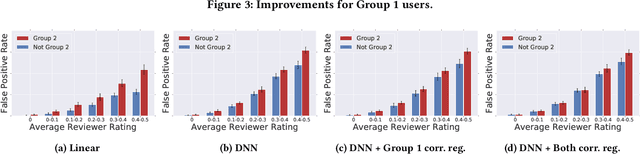
As more researchers have become aware of and passionate about algorithmic fairness, there has been an explosion in papers laying out new metrics, suggesting algorithms to address issues, and calling attention to issues in existing applications of machine learning. This research has greatly expanded our understanding of the concerns and challenges in deploying machine learning, but there has been much less work in seeing how the rubber meets the road. In this paper we provide a case-study on the application of fairness in machine learning research to a production classification system, and offer new insights in how to measure and address algorithmic fairness issues. We discuss open questions in implementing equality of opportunity and describe our fairness metric, conditional equality, that takes into account distributional differences. Further, we provide a new approach to improve on the fairness metric during model training and demonstrate its efficacy in improving performance for a real-world product