 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting Fairness Principles into Practice: Challenges, Metrics, and Improvements
Jan 14, 2019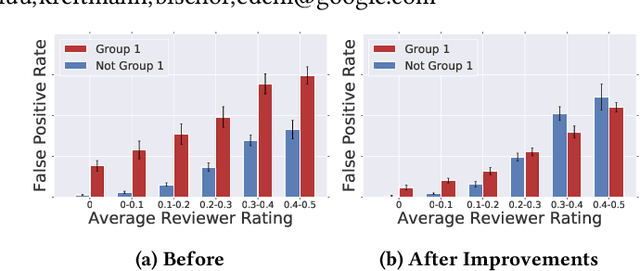
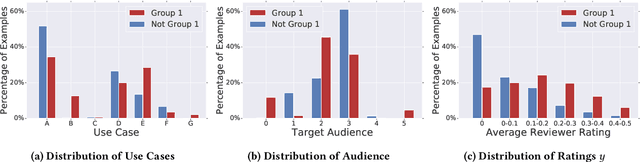

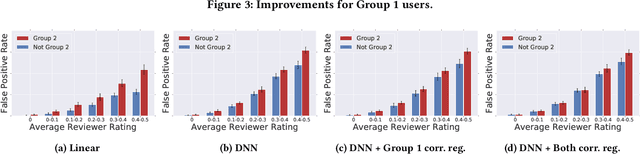
As more researchers have become aware of and passionate about algorithmic fairness, there has been an explosion in papers laying out new metrics, suggesting algorithms to address issues, and calling attention to issues in existing applications of machine learning. This research has greatly expanded our understanding of the concerns and challenges in deploying machine learning, but there has been much less work in seeing how the rubber meets the road. In this paper we provide a case-study on the application of fairness in machine learning research to a production classification system, and offer new insights in how to measure and address algorithmic fairness issues. We discuss open questions in implementing equality of opportunity and describe our fairness metric, conditional equality, that takes into account distributional differences. Further, we provide a new approach to improve on the fairness metric during model training and demonstrate its efficacy in improving performance for a real-world product
Detecting User Engagement in Everyday Conversations
Oct 13, 2004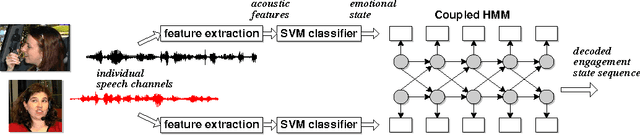
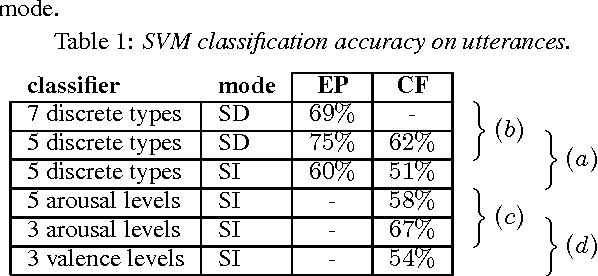
This paper presents a novel application of speech emotion recognition: estimation of the level of conversational engagement between users of a voice communication system. We begin by using machine learning techniques, such as the support vector machine (SVM), to classify users' emotions as expressed in individual utterances. However, this alone fails to model the temporal and interactive aspects of conversational engagement. We therefore propose the use of a multilevel structure based on coupled hidden Markov models (HMM) to estimate engagement levels in continuous natural speech. The first level is comprised of SVM-based classifiers that recognize emotional states, which could be (e.g.) discrete emotion types or arousal/valence levels. A high-level HMM then uses these emotional states as input, estimating users' engagement in conversation by decoding the internal states of the HMM. We report experimental results obtained by applying our algorithms to the LDC Emotional Prosody and CallFriend speech corpora.
* 4 pages (A4), 1 figure (EPS)