 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Safety and Responsibility Evaluations of Advanced AI Models
Apr 22, 2024Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Generalized People Diversity: Learning a Human Perception-Aligned Diversity Representation for People Images
Jan 25, 2024



Capturing the diversity of people in images is challenging: recent literature tends to focus on diversifying one or two attributes, requiring expensive attribute labels or building classifiers. We introduce a diverse people image ranking method which more flexibly aligns with human notions of people diversity in a less prescriptive, label-free manner. The Perception-Aligned Text-derived Human representation Space (PATHS) aims to capture all or many relevant features of people-related diversity, and, when used as the representation space in the standard Maximal Marginal Relevance (MMR) ranking algorithm, is better able to surface a range of types of people-related diversity (e.g. disability, cultural attire). PATHS is created in two stages. First, a text-guided approach is used to extract a person-diversity representation from a pre-trained image-text model. Then this representation is fine-tuned on perception judgments from human annotators so that it captures the aspects of people-related similarity that humans find most salient. Empirical results show that the PATHS method achieves diversity better than baseline methods, according to side-by-side ratings from human annotators.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses
Dec 01, 2023
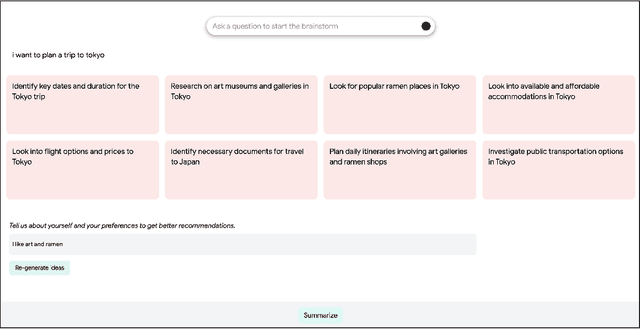


Large language model (LLM) powered chatbots are primarily text-based today, and impose a large interactional cognitive load, especially for exploratory or sensemaking tasks such as planning a trip or learning about a new city. Because the interaction is textual, users have little scaffolding in the way of structure, informational "scent", or ability to specify high-level preferences or goals. We introduce ExploreLLM that allows users to structure thoughts, help explore different options, navigate through the choices and recommendations, and to more easily steer models to generate more personalized responses. We conduct a user study and show that users find it helpful to use ExploreLLM for exploratory or planning tasks, because it provides a useful schema-like structure to the task, and guides users in planning. The study also suggests that users can more easily personalize responses with high-level preferences with ExploreLLM. Together, ExploreLLM points to a future where users interact with LLMs beyond the form of chatbots, and instead designed to support complex user tasks with a tighter integration between natural language and graphical user interfaces.
Improving Few-shot Generalization of Safety Classifiers via Data Augmented Parameter-Efficient Fine-Tuning
Oct 25, 2023

As large language models (LLMs) are widely adopted, new safety issues and policies emerge, to which existing safety classifiers do not generalize well. If we have only observed a few examples of violations of a new safety rule, how can we build a classifier to detect violations? In this paper, we study the novel setting of domain-generalized few-shot learning for LLM-based text safety classifiers. Unlike prior few-shot work, these new safety issues can be hard to uncover and we do not get to choose the few examples. We demonstrate that existing few-shot techniques do not perform well in this setting, and rather we propose to do parameter-efficient fine-tuning (PEFT) combined with augmenting training data based on similar examples in prior existing rules. We empirically show that our approach of similarity-based data-augmentation + prompt-tuning (DAPT) consistently outperforms baselines that either do not rely on data augmentation or on PEFT by 7-17% F1 score in the Social Chemistry moral judgement and 9-13% AUC in the Toxicity detection tasks, even when the new rule is loosely correlated with existing ones.
Controlled Decoding from Language Models
Oct 25, 2023



We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
Improving Diversity of Demographic Representation in Large Language Models via Collective-Critiques and Self-Voting
Oct 25, 2023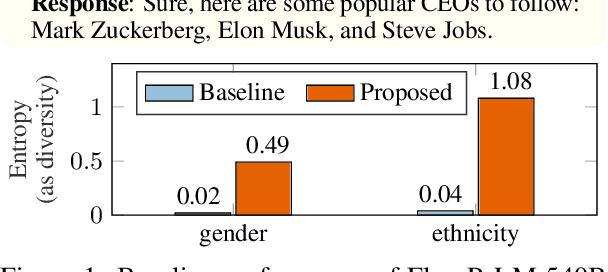
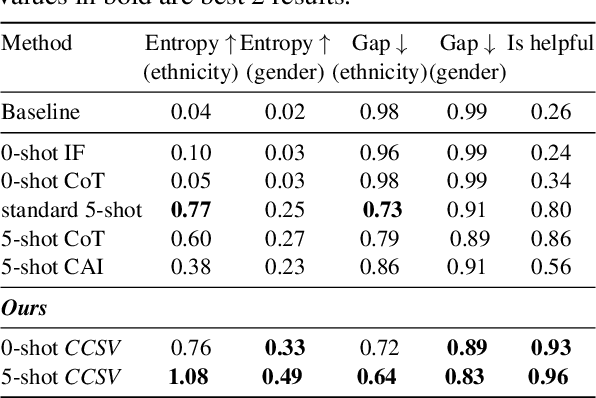

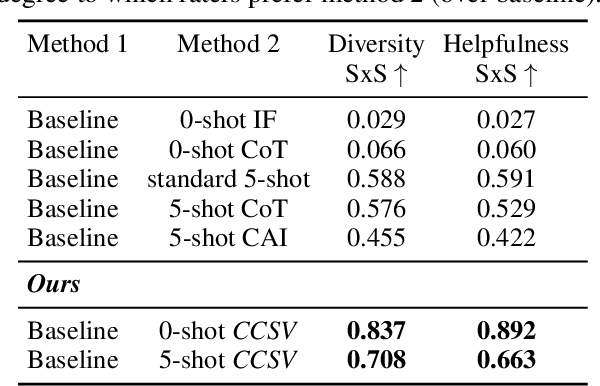
A crucial challenge for generative large language models (LLMs) is diversity: when a user's prompt is under-specified, models may follow implicit assumptions while generating a response, which may result in homogenization of the responses, as well as certain demographic groups being under-represented or even erased from the generated responses. In this paper, we formalize diversity of representation in generative LLMs. We present evaluation datasets and propose metrics to measure diversity in generated responses along people and culture axes. We find that LLMs understand the notion of diversity, and that they can reason and critique their own responses for that goal. This finding motivated a new prompting technique called collective-critique and self-voting (CCSV) to self-improve people diversity of LLMs by tapping into its diversity reasoning capabilities, without relying on handcrafted examples or prompt tuning. Extensive empirical experiments with both human and automated evaluations show that our proposed approach is effective at improving people and culture diversity, and outperforms all baseline methods by a large margin.
Break it, Imitate it, Fix it: Robustness by Generating Human-Like Attacks
Oct 25, 2023



Real-world natural language processing systems need to be robust to human adversaries. Collecting examples of human adversaries for training is an effective but expensive solution. On the other hand, training on synthetic attacks with small perturbations - such as word-substitution - does not actually improve robustness to human adversaries. In this paper, we propose an adversarial training framework that uses limited human adversarial examples to generate more useful adversarial examples at scale. We demonstrate the advantages of this system on the ANLI and hate speech detection benchmark datasets - both collected via an iterative, adversarial human-and-model-in-the-loop procedure. Compared to training only on observed human attacks, also training on our synthetic adversarial examples improves model robustness to future rounds. In ANLI, we see accuracy gains on the current set of attacks (44.1%$\,\to\,$50.1%) and on two future unseen rounds of human generated attacks (32.5%$\,\to\,$43.4%, and 29.4%$\,\to\,$40.2%). In hate speech detection, we see AUC gains on current attacks (0.76 $\to$ 0.84) and a future round (0.77 $\to$ 0.79). Attacks from methods that do not learn the distribution of existing human adversaries, meanwhile, degrade robustness.
Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering
Sep 29, 2023



Prompting and in-context learning (ICL) have become efficient learning paradigms for large language models (LLMs). However, LLMs suffer from prompt brittleness and various bias factors in the prompt, including but not limited to the formatting, the choice verbalizers, and the ICL examples. To address this problem that results in unexpected performance degradation, calibration methods have been developed to mitigate the effects of these biases while recovering LLM performance. In this work, we first conduct a systematic analysis of the existing calibration methods, where we both provide a unified view and reveal the failure cases. Inspired by these analyses, we propose Batch Calibration (BC), a simple yet intuitive method that controls the contextual bias from the batched input, unifies various prior approaches, and effectively addresses the aforementioned issues. BC is zero-shot, inference-only, and incurs negligible additional costs. In the few-shot setup, we further extend BC to allow it to learn the contextual bias from labeled data. We validate the effectiveness of BC with PaLM 2-(S, M, L) and CLIP models and demonstrate state-of-the-art performance over previous calibration baselines across more than 10 natural language understanding and image classification tasks.