 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAPPÉ: A Post-Processing Framework for Group Fairness Regularization
Dec 05, 2023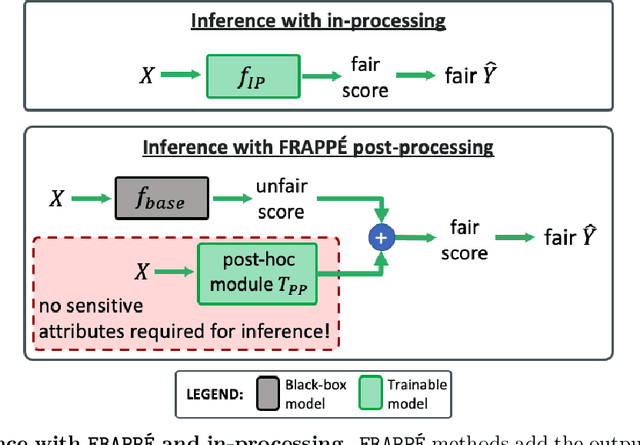
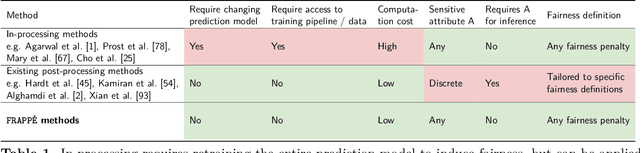
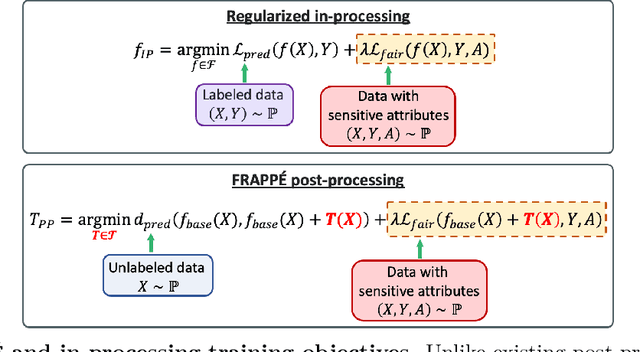
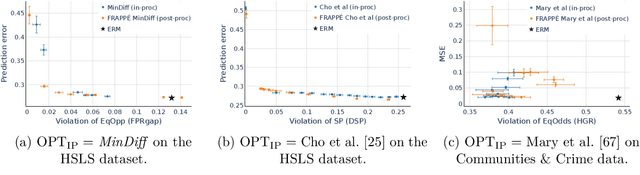
Post-processing mitigation techniques for group fairness generally adjust the decision threshold of a base model in order to improve fairness. Methods in this family exhibit several advantages that make them appealing in practice: post-processing requires no access to the model training pipeline, is agnostic to the base model architecture, and offers a reduced computation cost compared to in-processing. Despite these benefits, existing methods face other challenges that limit their applicability: they require knowledge of the sensitive attributes at inference time and are oftentimes outperformed by in-processing. In this paper, we propose a general framework to transform any in-processing method with a penalized objective into a post-processing procedure. The resulting method is specifically designed to overcome the aforementioned shortcomings of prior post-processing approaches. Furthermore, we show theoretically and through extensive experiments on real-world data that the resulting post-processing method matches or even surpasses the fairness-error trade-off offered by the in-processing counterpart.
Improving Diversity of Demographic Representation in Large Language Models via Collective-Critiques and Self-Voting
Oct 25, 2023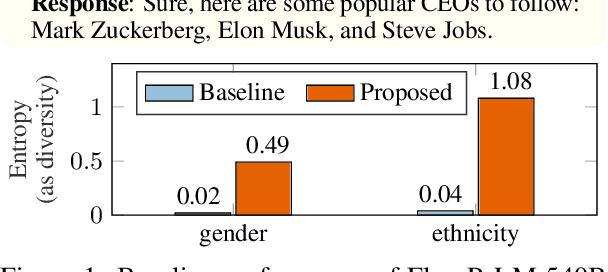
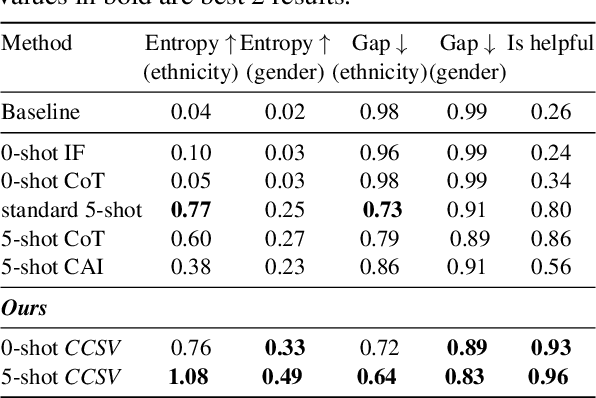

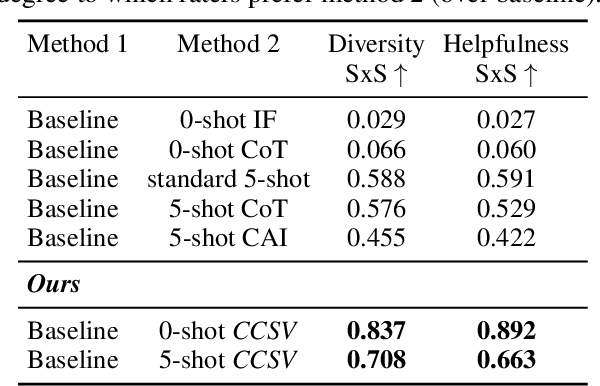
A crucial challenge for generative large language models (LLMs) is diversity: when a user's prompt is under-specified, models may follow implicit assumptions while generating a response, which may result in homogenization of the responses, as well as certain demographic groups being under-represented or even erased from the generated responses. In this paper, we formalize diversity of representation in generative LLMs. We present evaluation datasets and propose metrics to measure diversity in generated responses along people and culture axes. We find that LLMs understand the notion of diversity, and that they can reason and critique their own responses for that goal. This finding motivated a new prompting technique called collective-critique and self-voting (CCSV) to self-improve people diversity of LLMs by tapping into its diversity reasoning capabilities, without relying on handcrafted examples or prompt tuning. Extensive empirical experiments with both human and automated evaluations show that our proposed approach is effective at improving people and culture diversity, and outperforms all baseline methods by a large margin.
Towards A Scalable Solution for Improving Multi-Group Fairness in Compositional Classification
Jul 11, 2023Despite the rich literature on machine learning fairness, relatively little attention has been paid to remediating complex systems, where the final prediction is the combination of multiple classifiers and where multiple groups are present. In this paper, we first show that natural baseline approaches for improving equal opportunity fairness scale linearly with the product of the number of remediated groups and the number of remediated prediction labels, rendering them impractical. We then introduce two simple techniques, called {\em task-overconditioning} and {\em group-interleaving}, to achieve a constant scaling in this multi-group multi-label setup. Our experimental results in academic and real-world environments demonstrate the effectiveness of our proposal at mitigation within this environment.
Improving Classifier Robustness through Active Generation of Pairwise Counterfactuals
May 22, 2023Counterfactual Data Augmentation (CDA) is a commonly used technique for improving robustness in natural language classifiers. However, one fundamental challenge is how to discover meaningful counterfactuals and efficiently label them, with minimal human labeling cost. Most existing methods either completely rely on human-annotated labels, an expensive process which limits the scale of counterfactual data, or implicitly assume label invariance, which may mislead the model with incorrect labels. In this paper, we present a novel framework that utilizes counterfactual generative models to generate a large number of diverse counterfactuals by actively sampling from regions of uncertainty, and then automatically label them with a learned pairwise classifier. Our key insight is that we can more correctly label the generated counterfactuals by training a pairwise classifier that interpolates the relationship between the original example and the counterfactual. We demonstrate that with a small amount of human-annotated counterfactual data (10%), we can generate a counterfactual augmentation dataset with learned labels, that provides an 18-20% improvement in robustness and a 14-21% reduction in errors on 6 out-of-domain datasets, comparable to that of a fully human-annotated counterfactual dataset for both sentiment classification and question paraphrase tasks.
Striving for data-model efficiency: Identifying data externalities on group performance
Nov 11, 2022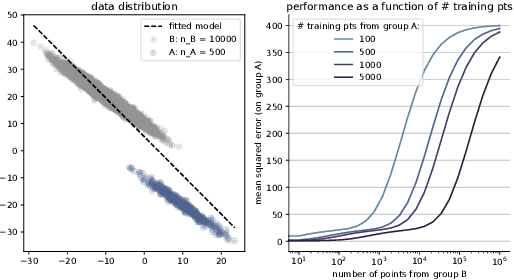
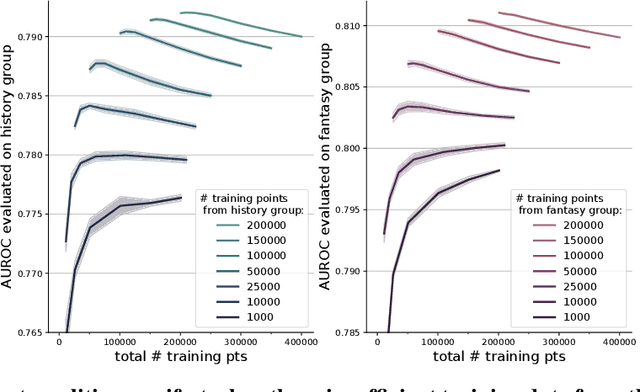
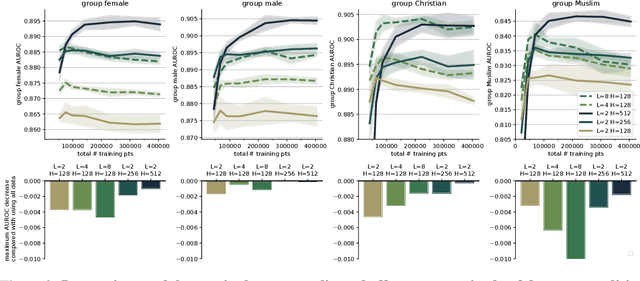
Building trustworthy, effective, and responsible machine learning systems hinges on understanding how differences in training data and modeling decisions interact to impact predictive performance. In this work, we seek to better understand how we might characterize, detect, and design for data-model synergies. We focus on a particular type of data-model inefficiency, in which adding training data from some sources can actually lower performance evaluated on key sub-groups of the population, a phenomenon we refer to as negative data externalities on group performance. Such externalities can arise in standard learning settings and can manifest differently depending on conditions between training set size and model size. Data externalities directly imply a lower bound on feasible model improvements, yet improving models efficiently requires understanding the underlying data-model tensions. From a broader perspective, our results indicate that data-efficiency is a key component of both accurate and trustworthy machine learning.
Simpson's Paradox in Recommender Fairness: Reconciling differences between per-user and aggregated evaluations
Oct 14, 2022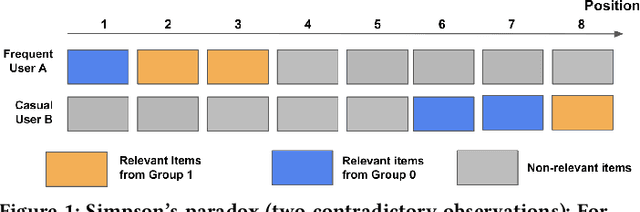
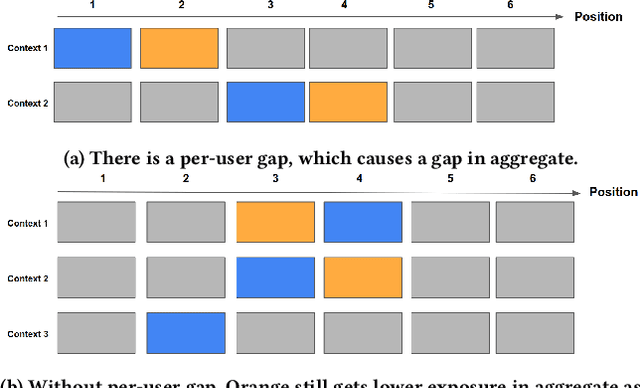
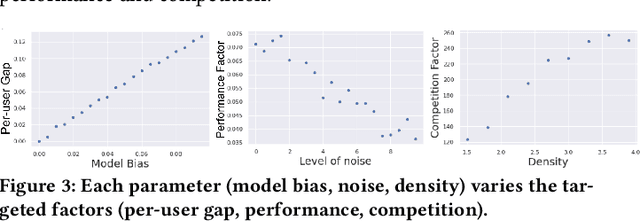
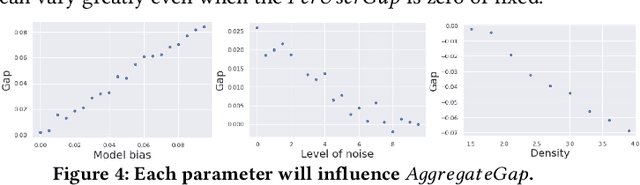
There has been a flurry of research in recent years on notions of fairness in ranking and recommender systems, particularly on how to evaluate if a recommender allocates exposure equally across groups of relevant items (also known as provider fairness). While this research has laid an important foundation, it gave rise to different approaches depending on whether relevant items are compared per-user/per-query or aggregated across users. Despite both being established and intuitive, we discover that these two notions can lead to opposite conclusions, a form of Simpson's Paradox. We reconcile these notions and show that the tension is due to differences in distributions of users where items are relevant, and break down the important factors of the user's recommendations. Based on this new understanding, practitioners might be interested in either notions, but might face challenges with the per-user metric due to partial observability of the relevance and user satisfaction, typical in real-world recommenders. We describe a technique based on distribution matching to estimate it in such a scenario. We demonstrate on simulated and real-world recommender data the effectiveness and usefulness of such an approach.
Flexible text generation for counterfactual fairness probing
Jun 28, 2022

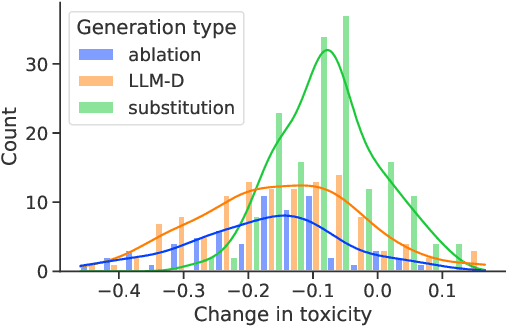
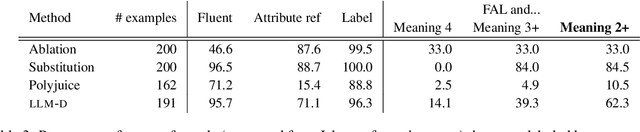
A common approach for testing fairness issues in text-based classifiers is through the use of counterfactuals: does the classifier output change if a sensitive attribute in the input is changed? Existing counterfactual generation methods typically rely on wordlists or templates, producing simple counterfactuals that don't take into account grammar, context, or subtle sensitive attribute references, and could miss issues that the wordlist creators had not considered. In this paper, we introduce a task for generating counterfactuals that overcomes these shortcomings, and demonstrate how large language models (LLMs) can be leveraged to make progress on this task. We show that this LLM-based method can produce complex counterfactuals that existing methods cannot, comparing the performance of various counterfactual generation methods on the Civil Comments dataset and showing their value in evaluating a toxicity classifier.
Causally-motivated Shortcut Removal Using Auxiliary Labels
Jun 03, 2021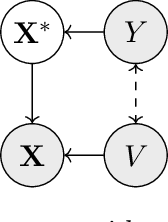

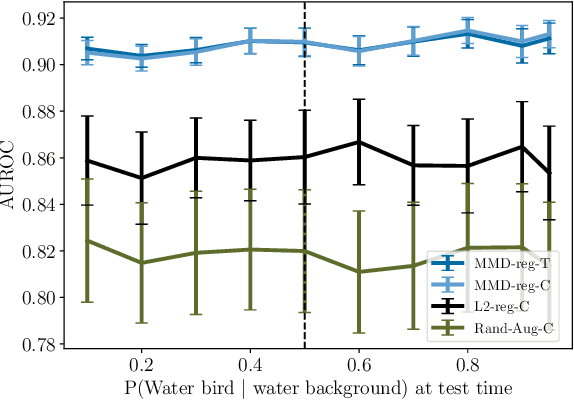
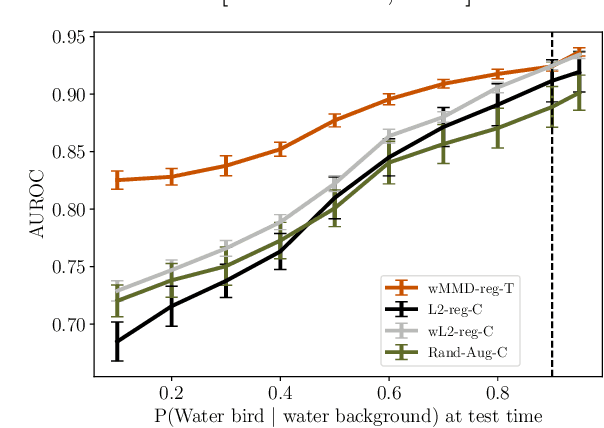
Robustness to certain forms of distribution shift is a key concern in many ML applications. Often, robustness can be formulated as enforcing invariances to particular interventions on the data generating process. Here, we study a flexible, causally-motivated approach to enforcing such invariances, paying special attention to shortcut learning, where a robust predictor can achieve optimal i.i.d generalization in principle, but instead it relies on spurious correlations or shortcuts in practice. Our approach uses auxiliary labels, typically available at training time, to enforce conditional independences between the latent factors that determine these labels. We show both theoretically and empirically that causally-motivated regularization schemes (a) lead to more robust estimators that generalize well under distribution shift, and (b) have better finite sample efficiency compared to usual regularization schemes, even in the absence of distribution shifts. Our analysis highlights important theoretical properties of training techniques commonly used in causal inference, fairness, and disentanglement literature.
CAT-Gen: Improving Robustness in NLP Models via Controlled Adversarial Text Generation
Oct 05, 2020
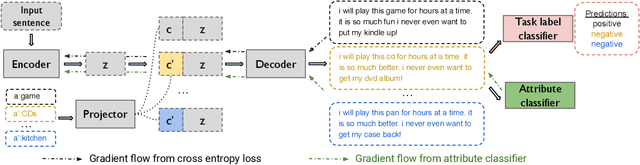

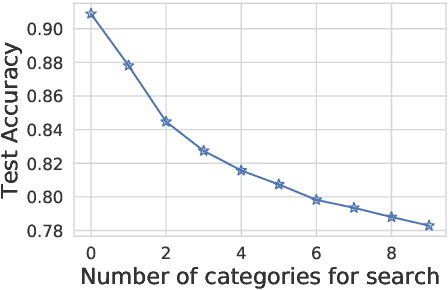
NLP models are shown to suffer from robustness issues, i.e., a model's prediction can be easily changed under small perturbations to the input. In this work, we present a Controlled Adversarial Text Generation (CAT-Gen) model that, given an input text, generates adversarial texts through controllable attributes that are known to be invariant to task labels. For example, in order to attack a model for sentiment classification over product reviews, we can use the product categories as the controllable attribute which would not change the sentiment of the reviews. Experiments on real-world NLP datasets demonstrate that our method can generate more diverse and fluent adversarial texts, compared to many existing adversarial text generation approaches. We further use our generated adversarial examples to improve models through adversarial training, and we demonstrate that our generated attacks are more robust against model re-training and different model architectures.
Modeling Latent Variable Uncertainty for Loss-based Learning
Jun 18, 2012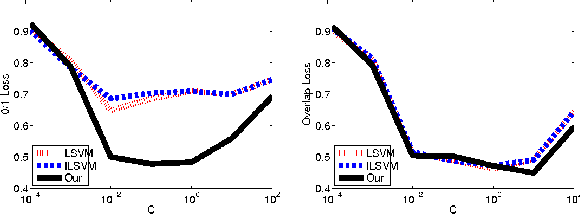
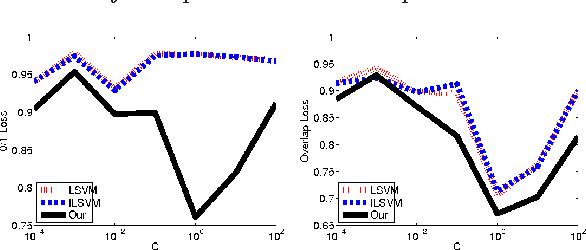
We consider the problem of parameter estimation using weakly supervised datasets, where a training sample consists of the input and a partially specified annotation, which we refer to as the output. The missing information in the annotation is modeled using latent variables. Previous methods overburden a single distribution with two separate tasks: (i) modeling the uncertainty in the latent variables during training; and (ii) making accurate predictions for the output and the latent variables during testing. We propose a novel framework that separates the demands of the two tasks using two distributions: (i) a conditional distribution to model the uncertainty of the latent variables for a given input-output pair; and (ii) a delta distribution to predict the output and the latent variables for a given input. During learning, we encourage agreement between the two distributions by minimizing a loss-based dissimilarity coefficient. Our approach generalizes latent SVM in two important ways: (i) it models the uncertainty over latent variables instead of relying on a pointwise estimate; and (ii) it allows the use of loss functions that depend on latent variables, which greatly increases its applicability. We demonstrate the efficacy of our approach on two challenging problems---object detection and action detection---using publicly available datasets.