 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
Query Refinement Prompts for Closed-Book Long-Form Question Answering
Oct 31, 2022Large language models (LLMs) have been shown to perform well in answering questions and in producing long-form texts, both in few-shot closed-book settings. While the former can be validated using well-known evaluation metrics, the latter is difficult to evaluate. We resolve the difficulties to evaluate long-form output by doing both tasks at once -- to do question answering that requires long-form answers. Such questions tend to be multifaceted, i.e., they may have ambiguities and/or require information from multiple sources. To this end, we define query refinement prompts that encourage LLMs to explicitly express the multifacetedness in questions and generate long-form answers covering multiple facets of the question. Our experiments on two long-form question answering datasets, ASQA and AQuAMuSe, show that using our prompts allows us to outperform fully finetuned models in the closed book setting, as well as achieve results comparable to retrieve-then-generate open-book models.
Flexible text generation for counterfactual fairness probing
Jun 28, 2022

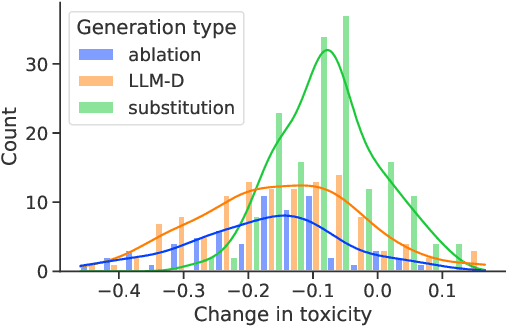
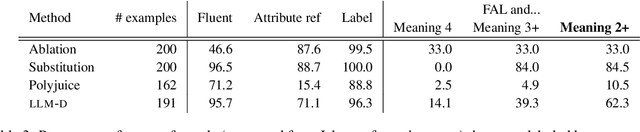
A common approach for testing fairness issues in text-based classifiers is through the use of counterfactuals: does the classifier output change if a sensitive attribute in the input is changed? Existing counterfactual generation methods typically rely on wordlists or templates, producing simple counterfactuals that don't take into account grammar, context, or subtle sensitive attribute references, and could miss issues that the wordlist creators had not considered. In this paper, we introduce a task for generating counterfactuals that overcomes these shortcomings, and demonstrate how large language models (LLMs) can be leveraged to make progress on this task. We show that this LLM-based method can produce complex counterfactuals that existing methods cannot, comparing the performance of various counterfactual generation methods on the Civil Comments dataset and showing their value in evaluating a toxicity classifier.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021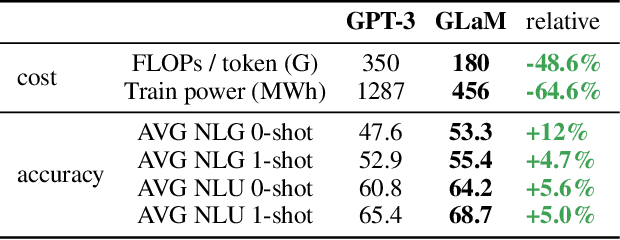
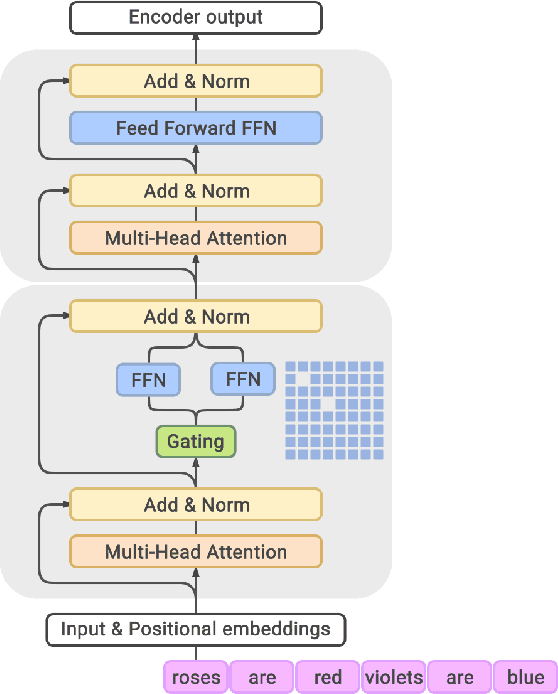
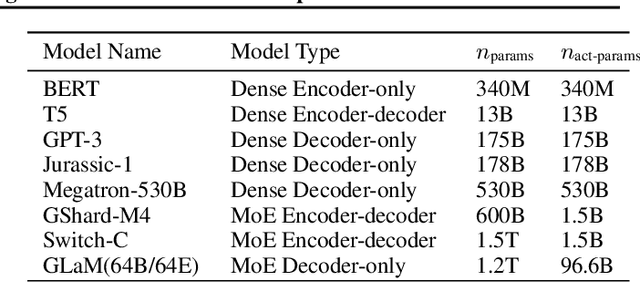
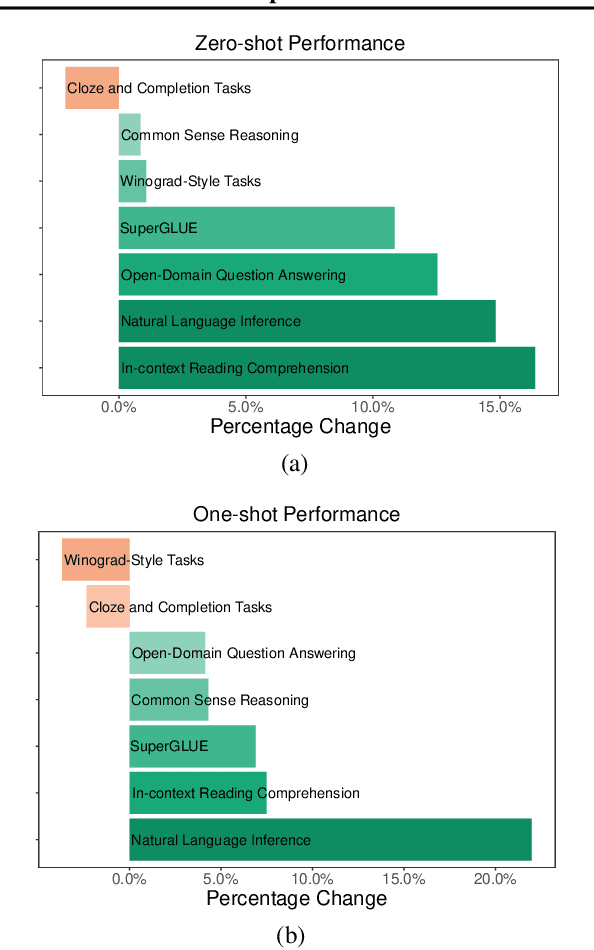
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
Towards Deconfounding the Influence of Subject's Demographic Characteristics in Question Answering
Apr 15, 2021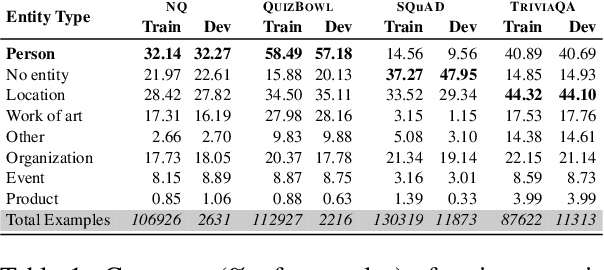
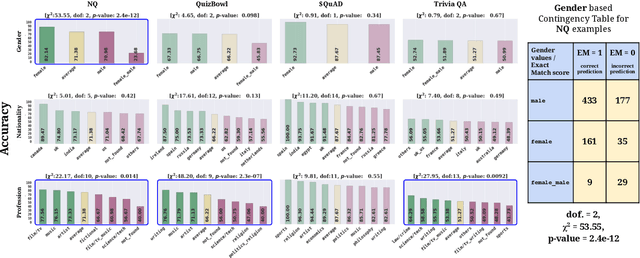
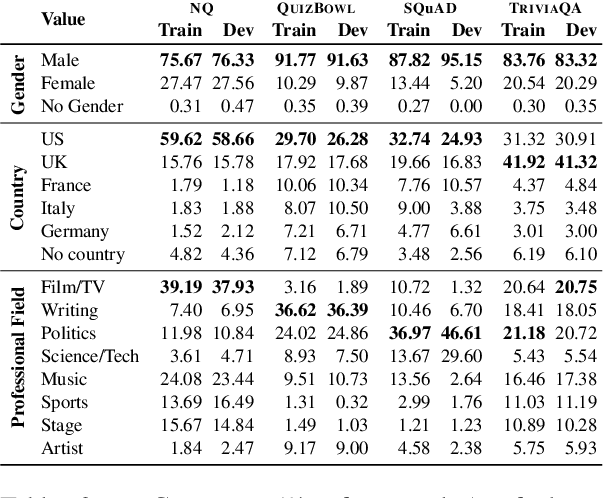
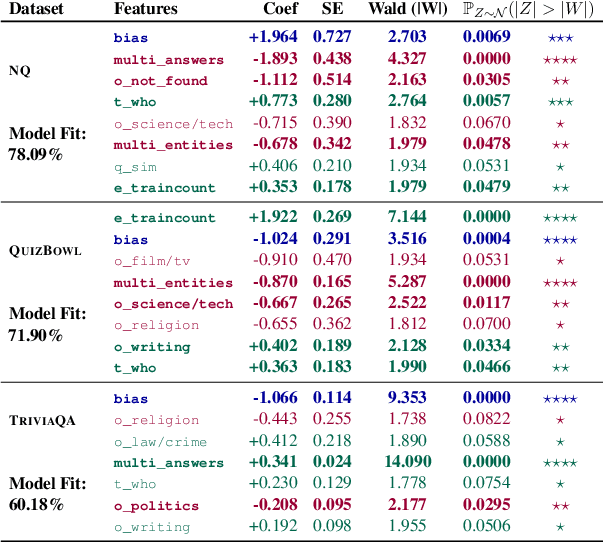
Question Answering (QA) tasks are used as benchmarks of general machine intelligence. Therefore, robust QA evaluation is critical, and metrics should indicate how models will answer any question. However, major QA datasets have skewed distributions over gender, profession, and nationality. Despite that skew, models generalize -- we find little evidence that accuracy is lower for people based on gender or nationality. Instead, there is more variation in question topic and question ambiguity. Adequately accessing the generalization of QA systems requires more representative datasets.
How to Write a Bias Statement: Recommendations for Submissions to the Workshop on Gender Bias in NLP
Apr 07, 2021At the Workshop on Gender Bias in NLP (GeBNLP), we'd like to encourage authors to give explicit consideration to the wider aspects of bias and its social implications. For the 2020 edition of the workshop, we therefore requested that all authors include an explicit bias statement in their work to clarify how their work relates to the social context in which NLP systems are used. The programme committee of the workshops included a number of reviewers with a background in the humanities and social sciences, in addition to NLP experts doing the bulk of the reviewing. Each paper was assigned one of those reviewers, and they were asked to pay specific attention to the provided bias statements in their reviews. This initiative was well received by the authors who submitted papers to the workshop, several of whom said they received useful suggestions and literature hints from the bias reviewers. We are therefore planning to keep this feature of the review process in future editions of the workshop.
They, Them, Theirs: Rewriting with Gender-Neutral English
Feb 12, 2021
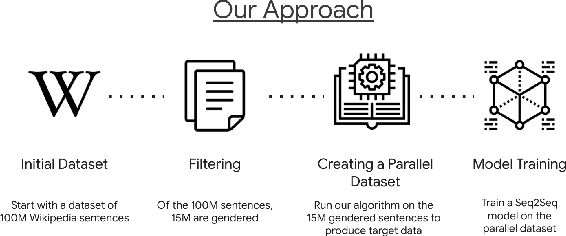
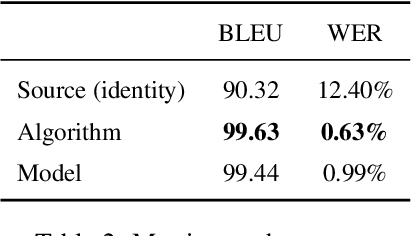
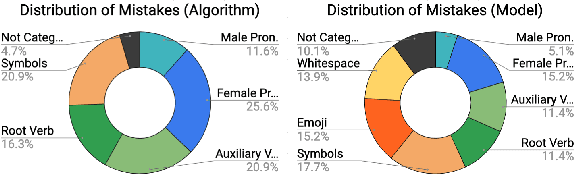
Responsible development of technology involves applications being inclusive of the diverse set of users they hope to support. An important part of this is understanding the many ways to refer to a person and being able to fluently change between the different forms as needed. We perform a case study on the singular they, a common way to promote gender inclusion in English. We define a re-writing task, create an evaluation benchmark, and show how a model can be trained to produce gender-neutral English with <1% word error rate with no human-labeled data. We discuss the practical applications and ethical considerations of the task, providing direction for future work into inclusive natural language systems.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
Measuring and Reducing Gendered Correlations in Pre-trained Models
Oct 12, 2020
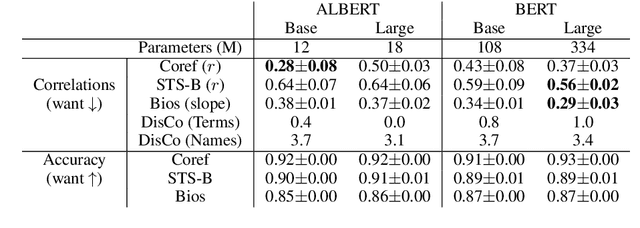
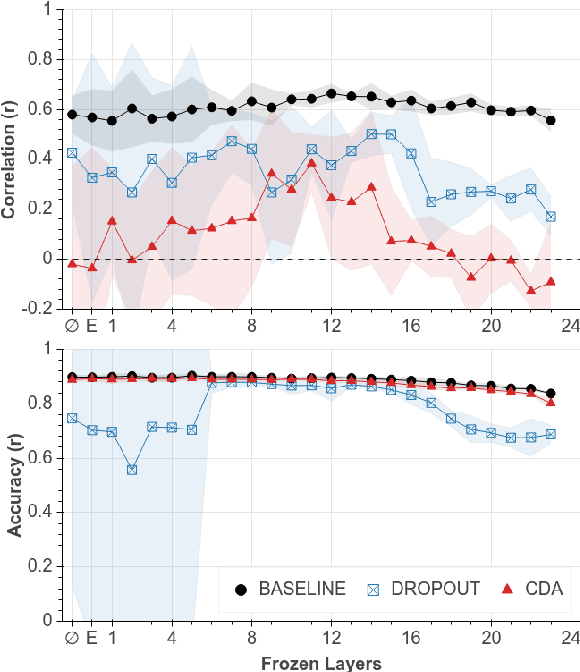
Pre-trained models have revolutionized natural language understanding. However, researchers have found they can encode artifacts undesired in many applications, such as professions correlating with one gender more than another. We explore such gendered correlations as a case study for how to address unintended correlations in pre-trained models. We define metrics and reveal that it is possible for models with similar accuracy to encode correlations at very different rates. We show how measured correlations can be reduced with general-purpose techniques, and highlight the trade offs different strategies have. With these results, we make recommendations for training robust models: (1) carefully evaluate unintended correlations, (2) be mindful of seemingly innocuous configuration differences, and (3) focus on general mitigations.
Type B Reflexivization as an Unambiguous Testbed for Multilingual Multi-Task Gender Bias
Sep 28, 2020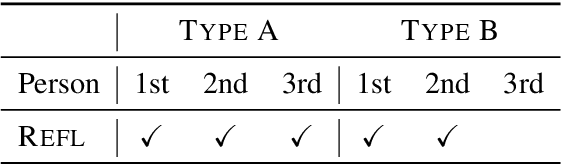
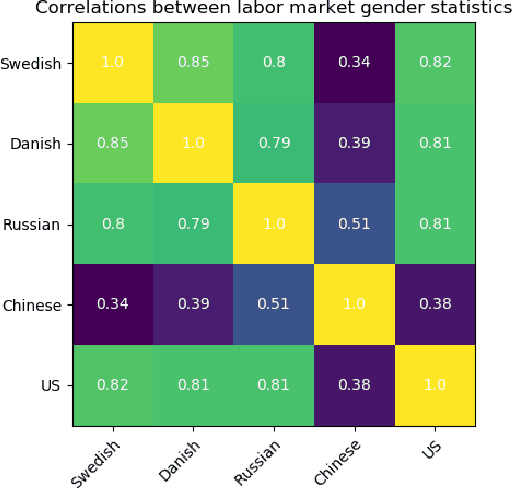


The one-sided focus on English in previous studies of gender bias in NLP misses out on opportunities in other languages: English challenge datasets such as GAP and WinoGender highlight model preferences that are "hallucinatory", e.g., disambiguating gender-ambiguous occurrences of 'doctor' as male doctors. We show that for languages with type B reflexivization, e.g., Swedish and Russian, we can construct multi-task challenge datasets for detecting gender bias that lead to unambiguously wrong model predictions: In these languages, the direct translation of 'the doctor removed his mask' is not ambiguous between a coreferential reading and a disjoint reading. Instead, the coreferential reading requires a non-gendered pronoun, and the gendered, possessive pronouns are anti-reflexive. We present a multilingual, multi-task challenge dataset, which spans four languages and four NLP tasks and focuses only on this phenomenon. We find evidence for gender bias across all task-language combinations and correlate model bias with national labor market statistics.