Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deconfounding the Influence of Subject's Demographic Characteristics in Question Answering
Paper and Code
Apr 15, 2021
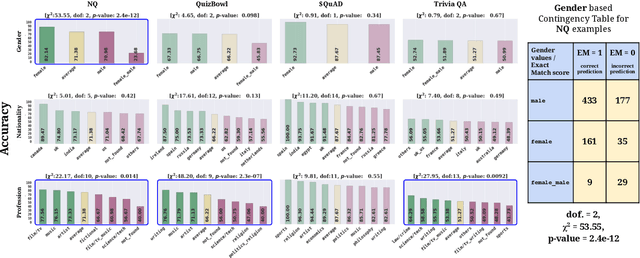
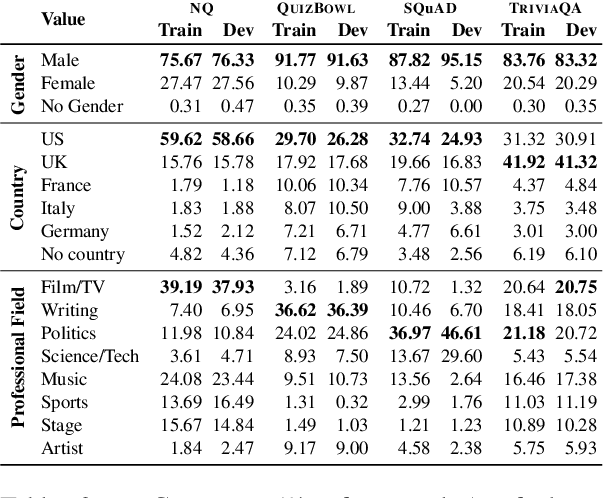
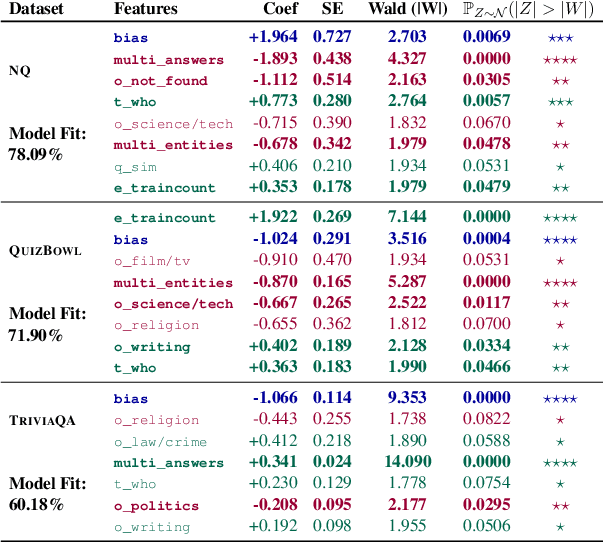
Question Answering (QA) tasks are used as benchmarks of general machine intelligence. Therefore, robust QA evaluation is critical, and metrics should indicate how models will answer any question. However, major QA datasets have skewed distributions over gender, profession, and nationality. Despite that skew, models generalize -- we find little evidence that accuracy is lower for people based on gender or nationality. Instead, there is more variation in question topic and question ambiguity. Adequately accessing the generalization of QA systems requires more representative datasets.
View paper on