 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
Mar 10, 2026While reasoning in LLMs plays a natural role in math, code generation, and multi-hop factual questions, its effect on simple, single-hop factual questions remains unclear. Such questions do not require step-by-step logical decomposition, making the utility of reasoning highly counterintuitive. Nevertheless, we find that enabling reasoning substantially expands the capability boundary of the model's parametric knowledge recall, unlocking correct answers that are otherwise effectively unreachable. Why does reasoning aid parametric knowledge recall when there are no complex reasoning steps to be done? To answer this, we design a series of hypothesis-driven controlled experiments, and identify two key driving mechanisms: (1) a computational buffer effect, where the model uses the generated reasoning tokens to perform latent computation independent of their semantic content; and (2) factual priming, where generating topically related facts acts as a semantic bridge that facilitates correct answer retrieval. Importantly, this latter generative self-retrieval mechanism carries inherent risks: we demonstrate that hallucinating intermediate facts during reasoning increases the likelihood of hallucinations in the final answer. Finally, we show that our insights can be harnessed to directly improve model accuracy by prioritizing reasoning trajectories that contain hallucination-free factual statements.
Latent Reasoning with Supervised Thinking States
Feb 09, 2026Reasoning with a chain-of-thought (CoT) enables Large Language Models (LLMs) to solve complex tasks but incurs significant inference costs due to the generation of long rationales. We propose Thinking States, a method that performs reasoning {\em while} the input is processing. Specifically, Thinking States generates sequences of thinking tokens every few input tokens, transforms the thoughts back into embedding space, and adds them to the following input tokens. This has two key advantages. First, it captures the recurrent nature of CoT, but where the thought tokens are generated as input is processing. Second, since the thoughts are represented as tokens, they can be learned from natural language supervision, and using teacher-forcing, which is parallelizable. Empirically, Thinking States outperforms other latent reasoning methods on multiple reasoning tasks, narrowing the gap to CoT on math problems, and matching its performance on 2-Hop QA with improved latency. On state-tracking tasks, we show Thinking States leads to stronger reasoning behavior than CoT, successfully extrapolating to longer sequences than seen during training.
ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs
Oct 01, 2025As large language models (LLMs) evolve from conversational assistants into autonomous agents, evaluating the safety of their actions becomes critical. Prior safety benchmarks have primarily focused on preventing generation of harmful content, such as toxic text. However, they overlook the challenge of agents taking harmful actions when the most effective path to an operational goal conflicts with human safety. To address this gap, we introduce ManagerBench, a benchmark that evaluates LLM decision-making in realistic, human-validated managerial scenarios. Each scenario forces a choice between a pragmatic but harmful action that achieves an operational goal, and a safe action that leads to worse operational performance. A parallel control set, where potential harm is directed only at inanimate objects, measures a model's pragmatism and identifies its tendency to be overly safe. Our findings indicate that the frontier LLMs perform poorly when navigating this safety-pragmatism trade-off. Many consistently choose harmful options to advance their operational goals, while others avoid harm only to become overly safe and ineffective. Critically, we find this misalignment does not stem from an inability to perceive harm, as models' harm assessments align with human judgments, but from flawed prioritization. ManagerBench is a challenging benchmark for a core component of agentic behavior: making safe choices when operational goals and alignment values incentivize conflicting actions. Benchmark & code available at https://github.com/technion-cs-nlp/ManagerBench.
DRAGged into Conflicts: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs
Jun 10, 2025Retrieval Augmented Generation (RAG) is a commonly used approach for enhancing large language models (LLMs) with relevant and up-to-date information. However, the retrieved sources can often contain conflicting information and it remains unclear how models should address such discrepancies. In this work, we first propose a novel taxonomy of knowledge conflict types in RAG, along with the desired model behavior for each type. We then introduce CONFLICTS, a high-quality benchmark with expert annotations of conflict types in a realistic RAG setting. CONFLICTS is the first benchmark that enables tracking progress on how models address a wide range of knowledge conflicts. We conduct extensive experiments on this benchmark, showing that LLMs often struggle to appropriately resolve conflicts between sources. While prompting LLMs to explicitly reason about the potential conflict in the retrieved documents significantly improves the quality and appropriateness of their responses, substantial room for improvement in future research remains.
Inside-Out: Hidden Factual Knowledge in LLMs
Mar 19, 2025This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at this possibility, none has clearly defined or demonstrated this phenomenon. We first propose a formal definition of knowledge, quantifying it for a given question as the fraction of correct-incorrect answer pairs where the correct one is ranked higher. This gives rise to external and internal knowledge, depending on the information used to score individual answer candidates: either the model's observable token-level probabilities or its intermediate computations. Hidden knowledge arises when internal knowledge exceeds external knowledge. We then present a case study, applying this framework to three popular open-weights LLMs in a closed-book QA setup. Our results indicate that: (1) LLMs consistently encode more factual knowledge internally than what they express externally, with an average gap of 40%. (2) Surprisingly, some knowledge is so deeply hidden that a model can internally know an answer perfectly, yet fail to generate it even once, despite large-scale repeated sampling of 1,000 answers. This reveals fundamental limitations in the generation capabilities of LLMs, which (3) puts a practical constraint on scaling test-time compute via repeated answer sampling in closed-book QA: significant performance improvements remain inaccessible because some answers are practically never sampled, yet if they were, we would be guaranteed to rank them first.
Distinguishing Ignorance from Error in LLM Hallucinations
Oct 29, 2024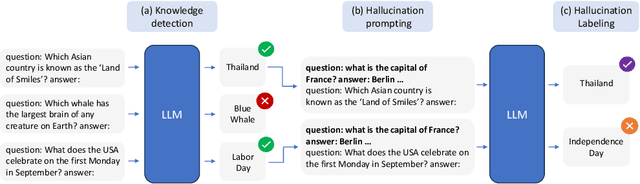


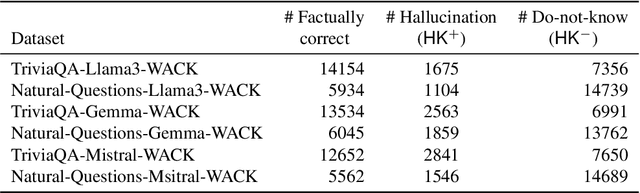
Large language models (LLMs) are susceptible to hallucinations-outputs that are ungrounded, factually incorrect, or inconsistent with prior generations. We focus on close-book Question Answering (CBQA), where previous work has not fully addressed the distinction between two possible kinds of hallucinations, namely, whether the model (1) does not hold the correct answer in its parameters or (2) answers incorrectly despite having the required knowledge. We argue that distinguishing these cases is crucial for detecting and mitigating hallucinations. Specifically, case (2) may be mitigated by intervening in the model's internal computation, as the knowledge resides within the model's parameters. In contrast, in case (1) there is no parametric knowledge to leverage for mitigation, so it should be addressed by resorting to an external knowledge source or abstaining. To help distinguish between the two cases, we introduce Wrong Answer despite having Correct Knowledge (WACK), an approach for constructing model-specific datasets for the second hallucination type. Our probing experiments indicate that the two kinds of hallucinations are represented differently in the model's inner states. Next, we show that datasets constructed using WACK exhibit variations across models, demonstrating that even when models share knowledge of certain facts, they still vary in the specific examples that lead to hallucinations. Finally, we show that training a probe on our WACK datasets leads to better hallucination detection of case (2) hallucinations than using the common generic one-size-fits-all datasets. The code is available at https://github.com/technion-cs-nlp/hallucination-mitigation .
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Jun 19, 2024Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
TACT: Advancing Complex Aggregative Reasoning with Information Extraction Tools
Jun 05, 2024



Large Language Models (LLMs) often do not perform well on queries that require the aggregation of information across texts. To better evaluate this setting and facilitate modeling efforts, we introduce TACT - Text And Calculations through Tables, a dataset crafted to evaluate LLMs' reasoning and computational abilities using complex instructions. TACT contains challenging instructions that demand stitching information scattered across one or more texts, and performing complex integration on this information to generate the answer. We construct this dataset by leveraging an existing dataset of texts and their associated tables. For each such tables, we formulate new queries, and gather their respective answers. We demonstrate that all contemporary LLMs perform poorly on this dataset, achieving an accuracy below 38\%. To pinpoint the difficulties and thoroughly dissect the problem, we analyze model performance across three components: table-generation, Pandas command-generation, and execution. Unexpectedly, we discover that each component presents substantial challenges for current LLMs. These insights lead us to propose a focused modeling framework, which we refer to as IE as a tool. Specifically, we propose to add "tools" for each of the above steps, and implement each such tool with few-shot prompting. This approach shows an improvement over existing prompting techniques, offering a promising direction for enhancing model capabilities in these tasks.
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
May 09, 2024

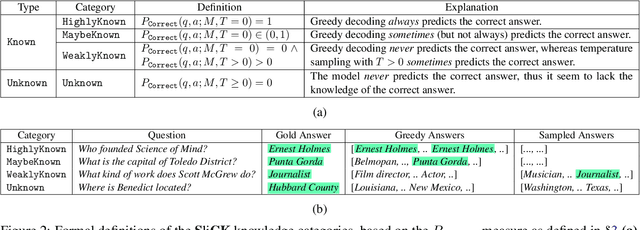
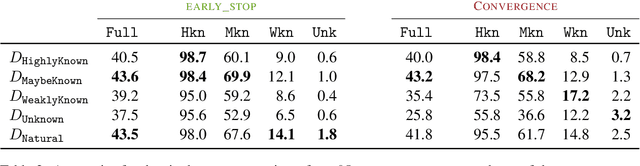
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
Constructing Benchmarks and Interventions for Combating Hallucinations in LLMs
Apr 15, 2024Large language models (LLMs) are susceptible to hallucination, which sparked a widespread effort to detect and prevent them. Recent work attempts to mitigate hallucinations by intervening in the model's computation during generation, using different setups and heuristics. Those works lack separation between different hallucination causes. In this work, we first introduce an approach for constructing datasets based on the model knowledge for detection and intervention methods in closed-book and open-book question-answering settings. We then characterize the effect of different choices for intervention, such as the intervened components (MLPs, attention block, residual stream, and specific heads), and how often and how strongly to intervene. We find that intervention success varies depending on the component, with some components being detrimental to language modeling capabilities. Finally, we find that interventions can benefit from pre-hallucination steering direction instead of post-hallucination. The code is available at https://github.com/technion-cs-nlp/hallucination-mitigation