 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus or Conflict? Fine-Grained Evaluation of Conflicting Answers in Question-Answering
Aug 17, 2025Large Language Models (LLMs) have demonstrated strong performance in question answering (QA) tasks. However, Multi-Answer Question Answering (MAQA), where a question may have several valid answers, remains challenging. Traditional QA settings often assume consistency across evidences, but MAQA can involve conflicting answers. Constructing datasets that reflect such conflicts is costly and labor-intensive, while existing benchmarks often rely on synthetic data, restrict the task to yes/no questions, or apply unverified automated annotation. To advance research in this area, we extend the conflict-aware MAQA setting to require models not only to identify all valid answers, but also to detect specific conflicting answer pairs, if any. To support this task, we introduce a novel cost-effective methodology for leveraging fact-checking datasets to construct NATCONFQA, a new benchmark for realistic, conflict-aware MAQA, enriched with detailed conflict labels, for all answer pairs. We evaluate eight high-end LLMs on NATCONFQA, revealing their fragility in handling various types of conflicts and the flawed strategies they employ to resolve them.
DRAGged into Conflicts: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs
Jun 10, 2025Retrieval Augmented Generation (RAG) is a commonly used approach for enhancing large language models (LLMs) with relevant and up-to-date information. However, the retrieved sources can often contain conflicting information and it remains unclear how models should address such discrepancies. In this work, we first propose a novel taxonomy of knowledge conflict types in RAG, along with the desired model behavior for each type. We then introduce CONFLICTS, a high-quality benchmark with expert annotations of conflict types in a realistic RAG setting. CONFLICTS is the first benchmark that enables tracking progress on how models address a wide range of knowledge conflicts. We conduct extensive experiments on this benchmark, showing that LLMs often struggle to appropriately resolve conflicts between sources. While prompting LLMs to explicitly reason about the potential conflict in the retrieved documents significantly improves the quality and appropriateness of their responses, substantial room for improvement in future research remains.
CLATTER: Comprehensive Entailment Reasoning for Hallucination Detection
Jun 05, 2025A common approach to hallucination detection casts it as a natural language inference (NLI) task, often using LLMs to classify whether the generated text is entailed by corresponding reference texts. Since entailment classification is a complex reasoning task, one would expect that LLMs could benefit from generating an explicit reasoning process, as in CoT reasoning or the explicit ``thinking'' of recent reasoning models. In this work, we propose that guiding such models to perform a systematic and comprehensive reasoning process -- one that both decomposes the text into smaller facts and also finds evidence in the source for each fact -- allows models to execute much finer-grained and accurate entailment decisions, leading to increased performance. To that end, we define a 3-step reasoning process, consisting of (i) claim decomposition, (ii) sub-claim attribution and entailment classification, and (iii) aggregated classification, showing that such guided reasoning indeed yields improved hallucination detection. Following this reasoning framework, we introduce an analysis scheme, consisting of several metrics that measure the quality of the intermediate reasoning steps, which provided additional empirical evidence for the improved quality of our guided reasoning scheme.
QAPyramid: Fine-grained Evaluation of Content Selection for Text Summarization
Dec 10, 2024
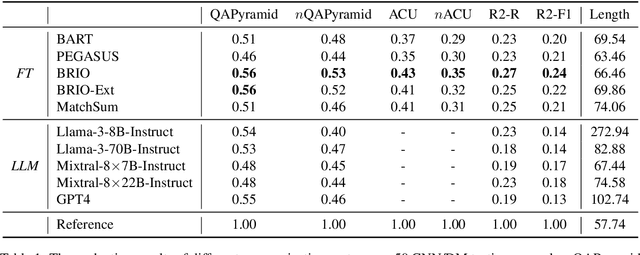
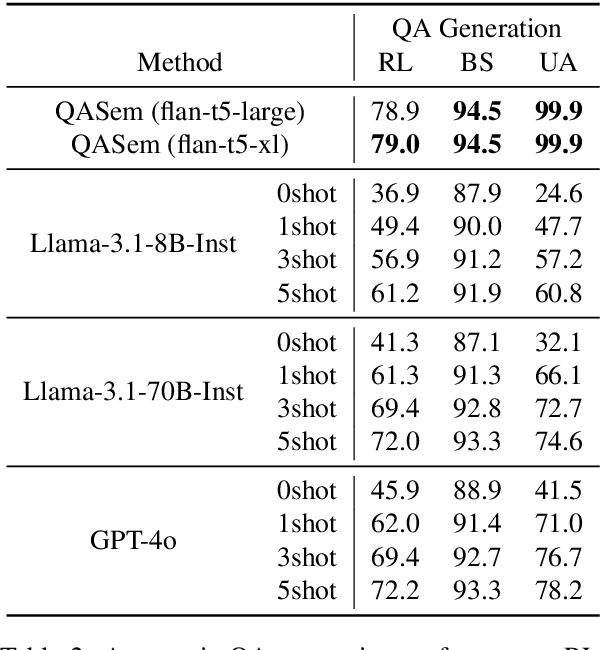
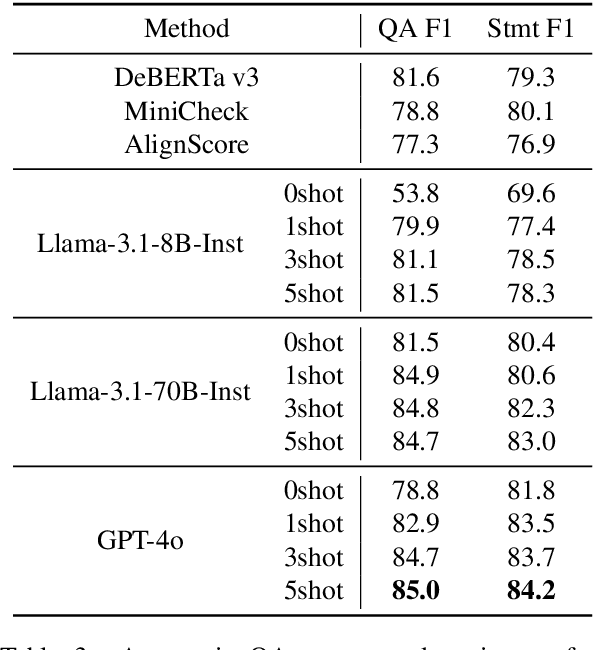
How to properly conduct human evaluations for text summarization is a longstanding challenge. The Pyramid human evaluation protocol, which assesses content selection by breaking the reference summary into sub-units and verifying their presence in the system summary, has been widely adopted. However, it suffers from a lack of systematicity in the definition and granularity of the sub-units. We address these problems by proposing QAPyramid, which decomposes each reference summary into finer-grained question-answer (QA) pairs according to the QA-SRL framework. We collect QA-SRL annotations for reference summaries from CNN/DM and evaluate 10 summarization systems, resulting in 8.9K QA-level annotations. We show that, compared to Pyramid, QAPyramid provides more systematic and fine-grained content selection evaluation while maintaining high inter-annotator agreement without needing expert annotations. Furthermore, we propose metrics that automate the evaluation pipeline and achieve higher correlations with QAPyramid than other widely adopted metrics, allowing future work to accurately and efficiently benchmark summarization systems.
Localizing Factual Inconsistencies in Attributable Text Generation
Oct 09, 2024
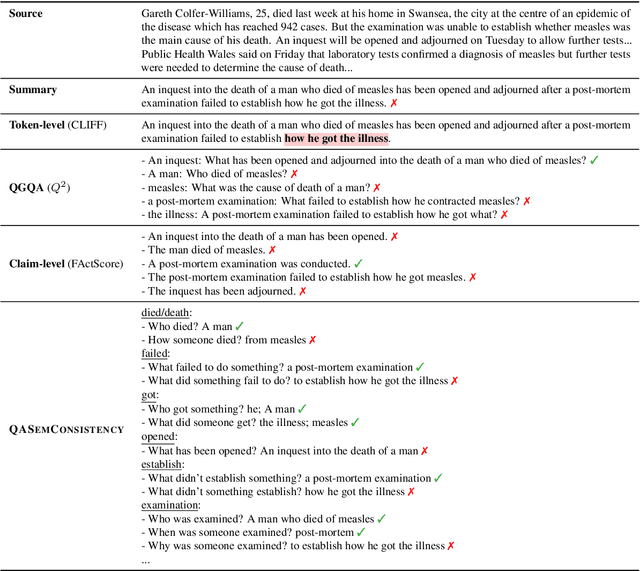

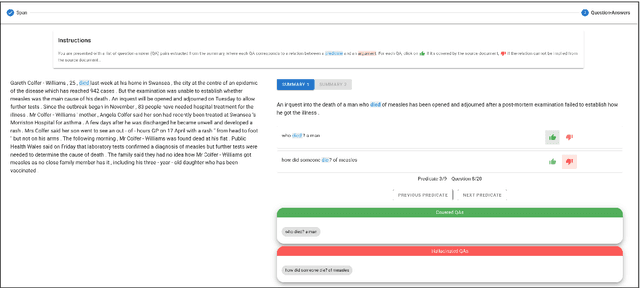
There has been an increasing interest in detecting hallucinations in model-generated texts, both manually and automatically, at varying levels of granularity. However, most existing methods fail to precisely pinpoint the errors. In this work, we introduce QASemConsistency, a new formalism for localizing factual inconsistencies in attributable text generation, at a fine-grained level. Drawing inspiration from Neo-Davidsonian formal semantics, we propose decomposing the generated text into minimal predicate-argument level propositions, expressed as simple question-answer (QA) pairs, and assess whether each individual QA pair is supported by a trusted reference text. As each QA pair corresponds to a single semantic relation between a predicate and an argument, QASemConsistency effectively localizes the unsupported information. We first demonstrate the effectiveness of the QASemConsistency methodology for human annotation, by collecting crowdsourced annotations of granular consistency errors, while achieving a substantial inter-annotator agreement ($\kappa > 0.7)$. Then, we implement several methods for automatically detecting localized factual inconsistencies, with both supervised entailment models and open-source LLMs.
Explicating the Implicit: Argument Detection Beyond Sentence Boundaries
Aug 08, 2024



Detecting semantic arguments of a predicate word has been conventionally modeled as a sentence-level task. The typical reader, however, perfectly interprets predicate-argument relations in a much wider context than just the sentence where the predicate was evoked. In this work, we reformulate the problem of argument detection through textual entailment to capture semantic relations across sentence boundaries. We propose a method that tests whether some semantic relation can be inferred from a full passage by first encoding it into a simple and standalone proposition and then testing for entailment against the passage. Our method does not require direct supervision, which is generally absent due to dataset scarcity, but instead builds on existing NLI and sentence-level SRL resources. Such a method can potentially explicate pragmatically understood relations into a set of explicit sentences. We demonstrate it on a recent document-level benchmark, outperforming some supervised methods and contemporary language models.
SEAM: A Stochastic Benchmark for Multi-Document Tasks
Jun 23, 2024



Various tasks, such as summarization, multi-hop question answering, or coreference resolution, are naturally phrased over collections of real-world documents. Such tasks present a unique set of challenges, revolving around the lack of coherent narrative structure across documents, which often leads to contradiction, omission, or repetition of information. Despite their real-world application and challenging properties, there is currently no benchmark which specifically measures the abilities of large language models (LLMs) on multi-document tasks. To bridge this gap, we present SEAM (a Stochastic Evaluation Approach for Multi-document tasks), a conglomerate benchmark over a diverse set of multi-document datasets, setting conventional evaluation criteria, input-output formats, and evaluation protocols. In particular, SEAM addresses the sensitivity of LLMs to minor prompt variations through repeated evaluations, where in each evaluation we sample uniformly at random the values of arbitrary factors (e.g., the order of documents). We evaluate different LLMs on SEAM finding that multi-document tasks pose a significant challenge for LLMs, even for state-of-the-art models with 70B parameters. In addition, we show that the stochastic approach uncovers underlying statistical trends which cannot be observed in a static benchmark. We hope that SEAM will spur progress via consistent and meaningful evaluation of multi-document tasks.
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Jun 19, 2024Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
Attribute First, then Generate: Locally-attributable Grounded Text Generation
Apr 01, 2024Recent efforts to address hallucinations in Large Language Models (LLMs) have focused on attributed text generation, which supplements generated texts with citations of supporting sources for post-generation fact-checking and corrections. Yet, these citations often point to entire documents or paragraphs, burdening users with extensive verification work. In this paper, we introduce a locally-attributable text generation approach, prioritizing concise attributions. Our method, named ``Attribute First, then Generate'', breaks down the conventional end-to-end generation process into three intuitive steps: content selection, sentence planning, and sequential sentence generation. By initially identifying relevant source segments (``select first'') and then conditioning the generation process on them (``then generate''), we ensure these segments also act as the output's fine-grained attributions (``select'' becomes ``attribute''). Tested on Multi-document Summarization and Long-form Question-answering, our method not only yields more concise citations than the baselines but also maintains - and in some cases enhances - both generation quality and attribution accuracy. Furthermore, it significantly reduces the time required for fact verification by human assessors.
CHAMP: Efficient Annotation and Consolidation of Cluster Hierarchies
Nov 19, 2023Various NLP tasks require a complex hierarchical structure over nodes, where each node is a cluster of items. Examples include generating entailment graphs, hierarchical cross-document coreference resolution, annotating event and subevent relations, etc. To enable efficient annotation of such hierarchical structures, we release CHAMP, an open source tool allowing to incrementally construct both clusters and hierarchy simultaneously over any type of texts. This incremental approach significantly reduces annotation time compared to the common pairwise annotation approach and also guarantees maintaining transitivity at the cluster and hierarchy levels. Furthermore, CHAMP includes a consolidation mode, where an adjudicator can easily compare multiple cluster hierarchy annotations and resolve disagreements.