 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Centric Evidence Ranking for Attribution and Fact Verification
Jan 29, 2026Attribution and fact verification are critical challenges in natural language processing for assessing information reliability. While automated systems and Large Language Models (LLMs) aim to retrieve and select concise evidence to support or refute claims, they often present users with either insufficient or overly redundant information, leading to inefficient and error-prone verification. To address this, we propose Evidence Ranking, a novel task that prioritizes presenting sufficient information as early as possible in a ranked list. This minimizes user reading effort while still making all available evidence accessible for sequential verification. We compare two approaches for the new ranking task: one-shot ranking and incremental ranking. We introduce a new evaluation framework, inspired by information retrieval metrics, and construct a unified benchmark by aggregating existing fact verification datasets. Extensive experiments with diverse models show that incremental ranking strategies better capture complementary evidence and that LLM-based methods outperform shallower baselines, while still facing challenges in balancing sufficiency and redundancy. Compared to evidence selection, we conduct a controlled user study and demonstrate that evidence ranking both reduces reading effort and improves verification. This work provides a foundational step toward more interpretable, efficient, and user-aligned information verification systems.
GenerationPrograms: Fine-grained Attribution with Executable Programs
Jun 17, 2025
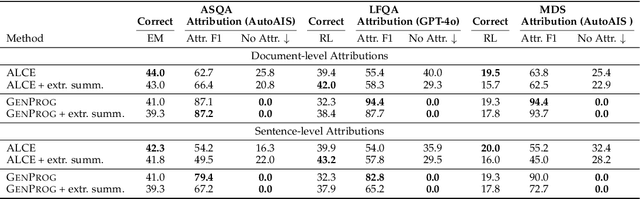
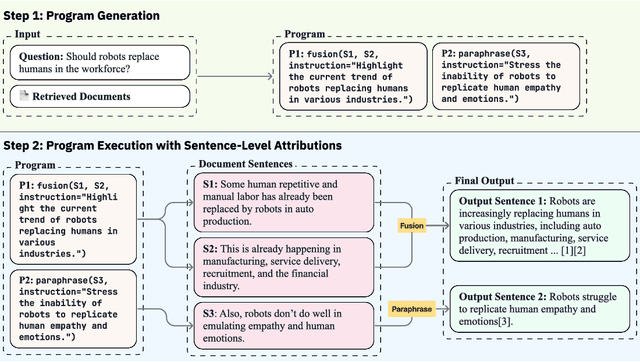
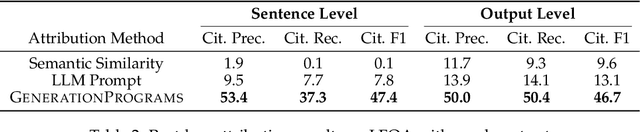
Recent large language models (LLMs) achieve impressive performance in source-conditioned text generation but often fail to correctly provide fine-grained attributions for their outputs, undermining verifiability and trust. Moreover, existing attribution methods do not explain how and why models leverage the provided source documents to generate their final responses, limiting interpretability. To overcome these challenges, we introduce a modular generation framework, GenerationPrograms, inspired by recent advancements in executable "code agent" architectures. Unlike conventional generation methods that simultaneously generate outputs and attributions or rely on post-hoc attribution, GenerationPrograms decomposes the process into two distinct stages: first, creating an executable program plan composed of modular text operations (such as paraphrasing, compression, and fusion) explicitly tailored to the query, and second, executing these operations following the program's specified instructions to produce the final response. Empirical evaluations demonstrate that GenerationPrograms significantly improves attribution quality at both the document level and sentence level across two long-form question-answering tasks and a multi-document summarization task. We further demonstrate that GenerationPrograms can effectively function as a post-hoc attribution method, outperforming traditional techniques in recovering accurate attributions. In addition, the interpretable programs generated by GenerationPrograms enable localized refinement through modular-level improvements that further enhance overall attribution quality.
CLATTER: Comprehensive Entailment Reasoning for Hallucination Detection
Jun 05, 2025A common approach to hallucination detection casts it as a natural language inference (NLI) task, often using LLMs to classify whether the generated text is entailed by corresponding reference texts. Since entailment classification is a complex reasoning task, one would expect that LLMs could benefit from generating an explicit reasoning process, as in CoT reasoning or the explicit ``thinking'' of recent reasoning models. In this work, we propose that guiding such models to perform a systematic and comprehensive reasoning process -- one that both decomposes the text into smaller facts and also finds evidence in the source for each fact -- allows models to execute much finer-grained and accurate entailment decisions, leading to increased performance. To that end, we define a 3-step reasoning process, consisting of (i) claim decomposition, (ii) sub-claim attribution and entailment classification, and (iii) aggregated classification, showing that such guided reasoning indeed yields improved hallucination detection. Following this reasoning framework, we introduce an analysis scheme, consisting of several metrics that measure the quality of the intermediate reasoning steps, which provided additional empirical evidence for the improved quality of our guided reasoning scheme.
Explicating the Implicit: Argument Detection Beyond Sentence Boundaries
Aug 08, 2024



Detecting semantic arguments of a predicate word has been conventionally modeled as a sentence-level task. The typical reader, however, perfectly interprets predicate-argument relations in a much wider context than just the sentence where the predicate was evoked. In this work, we reformulate the problem of argument detection through textual entailment to capture semantic relations across sentence boundaries. We propose a method that tests whether some semantic relation can be inferred from a full passage by first encoding it into a simple and standalone proposition and then testing for entailment against the passage. Our method does not require direct supervision, which is generally absent due to dataset scarcity, but instead builds on existing NLI and sentence-level SRL resources. Such a method can potentially explicate pragmatically understood relations into a set of explicit sentences. We demonstrate it on a recent document-level benchmark, outperforming some supervised methods and contemporary language models.
Make It Count: Text-to-Image Generation with an Accurate Number of Objects
Jun 14, 2024Despite the unprecedented success of text-to-image diffusion models, controlling the number of depicted objects using text is surprisingly hard. This is important for various applications from technical documents, to children's books to illustrating cooking recipes. Generating object-correct counts is fundamentally challenging because the generative model needs to keep a sense of separate identity for every instance of the object, even if several objects look identical or overlap, and then carry out a global computation implicitly during generation. It is still unknown if such representations exist. To address count-correct generation, we first identify features within the diffusion model that can carry the object identity information. We then use them to separate and count instances of objects during the denoising process and detect over-generation and under-generation. We fix the latter by training a model that predicts both the shape and location of a missing object, based on the layout of existing ones, and show how it can be used to guide denoising with correct object count. Our approach, CountGen, does not depend on external source to determine object layout, but rather uses the prior from the diffusion model itself, creating prompt-dependent and seed-dependent layouts. Evaluated on two benchmark datasets, we find that CountGen strongly outperforms the count-accuracy of existing baselines.
Attribute First, then Generate: Locally-attributable Grounded Text Generation
Apr 01, 2024Recent efforts to address hallucinations in Large Language Models (LLMs) have focused on attributed text generation, which supplements generated texts with citations of supporting sources for post-generation fact-checking and corrections. Yet, these citations often point to entire documents or paragraphs, burdening users with extensive verification work. In this paper, we introduce a locally-attributable text generation approach, prioritizing concise attributions. Our method, named ``Attribute First, then Generate'', breaks down the conventional end-to-end generation process into three intuitive steps: content selection, sentence planning, and sequential sentence generation. By initially identifying relevant source segments (``select first'') and then conditioning the generation process on them (``then generate''), we ensure these segments also act as the output's fine-grained attributions (``select'' becomes ``attribute''). Tested on Multi-document Summarization and Long-form Question-answering, our method not only yields more concise citations than the baselines but also maintains - and in some cases enhances - both generation quality and attribution accuracy. Furthermore, it significantly reduces the time required for fact verification by human assessors.
What's the Plan? Evaluating and Developing Planning-Aware Techniques for LLMs
Feb 18, 2024


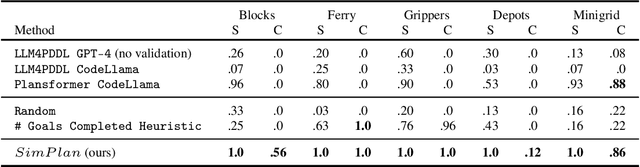
Planning is a fundamental task in artificial intelligence that involves finding a sequence of actions that achieve a specified goal in a given environment. Large language models (LLMs) are increasingly used for applications that require planning capabilities, such as web or embodied agents. In line with recent studies, we demonstrate through experimentation that LLMs lack necessary skills required for planning. Based on these observations, we advocate for the potential of a hybrid approach that combines LLMs with classical planning methodology. Then, we introduce SimPlan, a novel hybrid-method, and evaluate its performance in a new challenging setup. Our extensive experiments across various planning domains demonstrate that SimPlan significantly outperforms existing LLM-based planners.
Dont Add, dont Miss: Effective Content Preserving Generation from Pre-Selected Text Spans
Oct 13, 2023



The recently introduced Controlled Text Reduction (CTR) task isolates the text generation step within typical summarization-style tasks. It does so by challenging models to generate coherent text conforming to pre-selected content within the input text ("highlights"). This framing enables increased modularity in summarization-like tasks, allowing to couple a single CTR model with various content-selection setups and modules. However, there are currently no reliable CTR models, while the performance of the existing baseline for the task is mediocre, falling short of practical utility. Here, we address this gap by introducing a high-quality, open-source CTR model that tackles two prior key limitations: inadequate enforcement of the content-preservation constraint, and suboptimal silver training data. Addressing these, we amplify the content-preservation constraint in both training, via RL, and inference, via a controlled decoding strategy. Further, we substantially improve the silver training data quality via GPT-4 distillation. Overall, pairing the distilled dataset with the highlight-adherence strategies yields marked gains over the current baseline, of up to 30 ROUGE-L points, providing a reliable CTR model for downstream use.
Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment
Jun 15, 2023Text-conditioned image generation models often generate incorrect associations between entities and their visual attributes. This reflects an impaired mapping between linguistic binding of entities and modifiers in the prompt and visual binding of the corresponding elements in the generated image. As one notable example, a query like ``a pink sunflower and a yellow flamingo'' may incorrectly produce an image of a yellow sunflower and a pink flamingo. To remedy this issue, we propose SynGen, an approach which first syntactically analyses the prompt to identify entities and their modifiers, and then uses a novel loss function that encourages the cross-attention maps to agree with the linguistic binding reflected by the syntax. Specifically, we encourage large overlap between attention maps of entities and their modifiers, and small overlap with other entities and modifier words. The loss is optimized during inference, without retraining or fine-tuning the model. Human evaluation on three datasets, including one new and challenging set, demonstrate significant improvements of SynGen compared with current state of the art methods. This work highlights how making use of sentence structure during inference can efficiently and substantially improve the faithfulness of text-to-image generation.
Revisiting Sentence Union Generation as a Testbed for Text Consolidation
May 24, 2023



Tasks involving text generation based on multiple input texts, such as multi-document summarization, long-form question answering and contemporary dialogue applications, challenge models for their ability to properly consolidate partly-overlapping multi-text information. However, these tasks entangle the consolidation phase with the often subjective and ill-defined content selection requirement, impeding proper assessment of models' consolidation capabilities. In this paper, we suggest revisiting the sentence union generation task as an effective well-defined testbed for assessing text consolidation capabilities, decoupling the consolidation challenge from subjective content selection. To support research on this task, we present refined annotation methodology and tools for crowdsourcing sentence union, create the largest union dataset to date and provide an analysis of its rich coverage of various consolidation aspects. We then propose a comprehensive evaluation protocol for union generation, including both human and automatic evaluation. Finally, as baselines, we evaluate state-of-the-art language models on the task, along with a detailed analysis of their capacity to address multi-text consolidation challenges and their limitations.