 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePadding Tone: A Mechanistic Analysis of Padding Tokens in T2I Models
Jan 12, 2025



Text-to-image (T2I) diffusion models rely on encoded prompts to guide the image generation process. Typically, these prompts are extended to a fixed length by adding padding tokens before text encoding. Despite being a default practice, the influence of padding tokens on the image generation process has not been investigated. In this work, we conduct the first in-depth analysis of the role padding tokens play in T2I models. We develop two causal techniques to analyze how information is encoded in the representation of tokens across different components of the T2I pipeline. Using these techniques, we investigate when and how padding tokens impact the image generation process. Our findings reveal three distinct scenarios: padding tokens may affect the model's output during text encoding, during the diffusion process, or be effectively ignored. Moreover, we identify key relationships between these scenarios and the model's architecture (cross or self-attention) and its training process (frozen or trained text encoder). These insights contribute to a deeper understanding of the mechanisms of padding tokens, potentially informing future model design and training practices in T2I systems.
Multi-Shot Character Consistency for Text-to-Video Generation
Dec 10, 2024

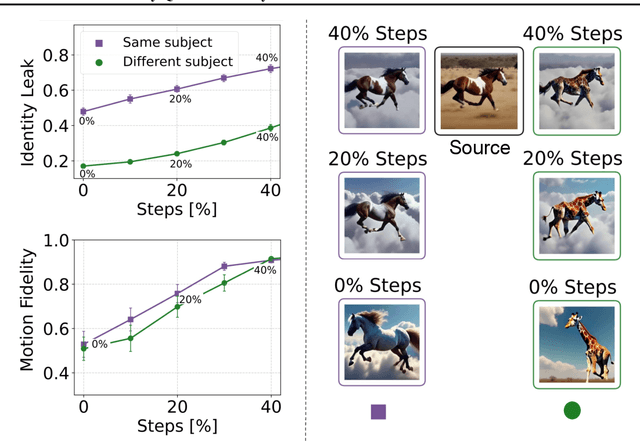

Text-to-video models have made significant strides in generating short video clips from textual descriptions. Yet, a significant challenge remains: generating several video shots of the same characters, preserving their identity without hurting video quality, dynamics, and responsiveness to text prompts. We present Video Storyboarding, a training-free method to enable pretrained text-to-video models to generate multiple shots with consistent characters, by sharing features between them. Our key insight is that self-attention query features (Q) encode both motion and identity. This creates a hard-to-avoid trade-off between preserving character identity and making videos dynamic, when features are shared. To address this issue, we introduce a novel query injection strategy that balances identity preservation and natural motion retention. This approach improves upon naive consistency techniques applied to videos, which often struggle to maintain this delicate equilibrium. Our experiments demonstrate significant improvements in character consistency across scenes while maintaining high-quality motion and text alignment. These results offer insights into critical stages of video generation and the interplay of structure and motion in video diffusion models.
Add-it: Training-Free Object Insertion in Images With Pretrained Diffusion Models
Nov 12, 2024
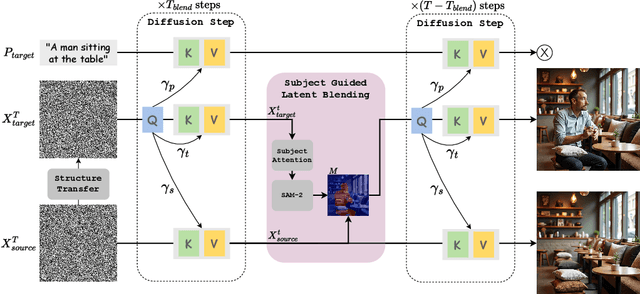
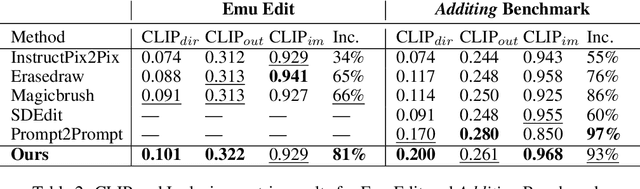
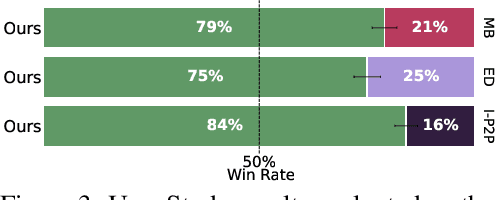
Adding Object into images based on text instructions is a challenging task in semantic image editing, requiring a balance between preserving the original scene and seamlessly integrating the new object in a fitting location. Despite extensive efforts, existing models often struggle with this balance, particularly with finding a natural location for adding an object in complex scenes. We introduce Add-it, a training-free approach that extends diffusion models' attention mechanisms to incorporate information from three key sources: the scene image, the text prompt, and the generated image itself. Our weighted extended-attention mechanism maintains structural consistency and fine details while ensuring natural object placement. Without task-specific fine-tuning, Add-it achieves state-of-the-art results on both real and generated image insertion benchmarks, including our newly constructed "Additing Affordance Benchmark" for evaluating object placement plausibility, outperforming supervised methods. Human evaluations show that Add-it is preferred in over 80% of cases, and it also demonstrates improvements in various automated metrics.
Make It Count: Text-to-Image Generation with an Accurate Number of Objects
Jun 14, 2024Despite the unprecedented success of text-to-image diffusion models, controlling the number of depicted objects using text is surprisingly hard. This is important for various applications from technical documents, to children's books to illustrating cooking recipes. Generating object-correct counts is fundamentally challenging because the generative model needs to keep a sense of separate identity for every instance of the object, even if several objects look identical or overlap, and then carry out a global computation implicitly during generation. It is still unknown if such representations exist. To address count-correct generation, we first identify features within the diffusion model that can carry the object identity information. We then use them to separate and count instances of objects during the denoising process and detect over-generation and under-generation. We fix the latter by training a model that predicts both the shape and location of a missing object, based on the layout of existing ones, and show how it can be used to guide denoising with correct object count. Our approach, CountGen, does not depend on external source to determine object layout, but rather uses the prior from the diffusion model itself, creating prompt-dependent and seed-dependent layouts. Evaluated on two benchmark datasets, we find that CountGen strongly outperforms the count-accuracy of existing baselines.
Training-Free Consistent Text-to-Image Generation
Feb 05, 2024Text-to-image models offer a new level of creative flexibility by allowing users to guide the image generation process through natural language. However, using these models to consistently portray the same subject across diverse prompts remains challenging. Existing approaches fine-tune the model to teach it new words that describe specific user-provided subjects or add image conditioning to the model. These methods require lengthy per-subject optimization or large-scale pre-training. Moreover, they struggle to align generated images with text prompts and face difficulties in portraying multiple subjects. Here, we present ConsiStory, a training-free approach that enables consistent subject generation by sharing the internal activations of the pretrained model. We introduce a subject-driven shared attention block and correspondence-based feature injection to promote subject consistency between images. Additionally, we develop strategies to encourage layout diversity while maintaining subject consistency. We compare ConsiStory to a range of baselines, and demonstrate state-of-the-art performance on subject consistency and text alignment, without requiring a single optimization step. Finally, ConsiStory can naturally extend to multi-subject scenarios, and even enable training-free personalization for common objects.
Key-Locked Rank One Editing for Text-to-Image Personalization
May 02, 2023



Text-to-image models (T2I) offer a new level of flexibility by allowing users to guide the creative process through natural language. However, personalizing these models to align with user-provided visual concepts remains a challenging problem. The task of T2I personalization poses multiple hard challenges, such as maintaining high visual fidelity while allowing creative control, combining multiple personalized concepts in a single image, and keeping a small model size. We present Perfusion, a T2I personalization method that addresses these challenges using dynamic rank-1 updates to the underlying T2I model. Perfusion avoids overfitting by introducing a new mechanism that "locks" new concepts' cross-attention Keys to their superordinate category. Additionally, we develop a gated rank-1 approach that enables us to control the influence of a learned concept during inference time and to combine multiple concepts. This allows runtime-efficient balancing of visual-fidelity and textual-alignment with a single 100KB trained model, which is five orders of magnitude smaller than the current state of the art. Moreover, it can span different operating points across the Pareto front without additional training. Finally, we show that Perfusion outperforms strong baselines in both qualitative and quantitative terms. Importantly, key-locking leads to novel results compared to traditional approaches, allowing to portray personalized object interactions in unprecedented ways, even in one-shot settings.
Zero-Shot Video Captioning with Evolving Pseudo-Tokens
Jul 27, 2022
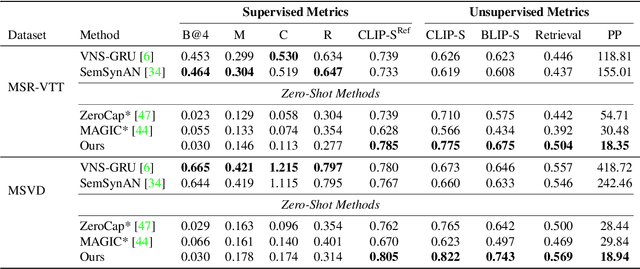
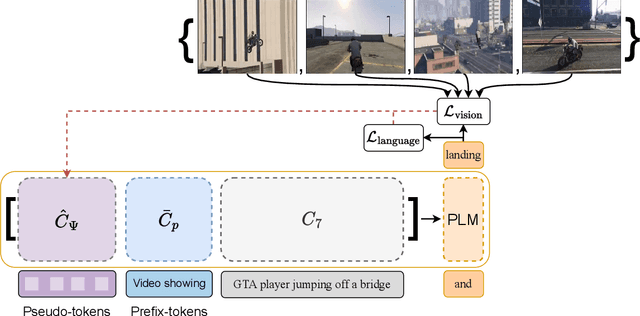
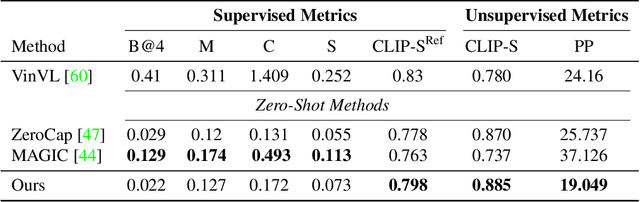
We introduce a zero-shot video captioning method that employs two frozen networks: the GPT-2 language model and the CLIP image-text matching model. The matching score is used to steer the language model toward generating a sentence that has a high average matching score to a subset of the video frames. Unlike zero-shot image captioning methods, our work considers the entire sentence at once. This is achieved by optimizing, during the generation process, part of the prompt from scratch, by modifying the representation of all other tokens in the prompt, and by repeating the process iteratively, gradually improving the specificity and comprehensiveness of the generated sentence. Our experiments show that the generated captions are coherent and display a broad range of real-world knowledge. Our code is available at: https://github.com/YoadTew/zero-shot-video-to-text
What is Where by Looking: Weakly-Supervised Open-World Phrase-Grounding without Text Inputs
Jun 27, 2022



Given an input image, and nothing else, our method returns the bounding boxes of objects in the image and phrases that describe the objects. This is achieved within an open world paradigm, in which the objects in the input image may not have been encountered during the training of the localization mechanism. Moreover, training takes place in a weakly supervised setting, where no bounding boxes are provided. To achieve this, our method combines two pre-trained networks: the CLIP image-to-text matching score and the BLIP image captioning tool. Training takes place on COCO images and their captions and is based on CLIP. Then, during inference, BLIP is used to generate a hypothesis regarding various regions of the current image. Our work generalizes weakly supervised segmentation and phrase grounding and is shown empirically to outperform the state of the art in both domains. It also shows very convincing results in the novel task of weakly-supervised open-world purely visual phrase-grounding presented in our work. For example, on the datasets used for benchmarking phrase-grounding, our method results in a very modest degradation in comparison to methods that employ human captions as an additional input. Our code is available at https://github.com/talshaharabany/what-is-where-by-looking and a live demo can be found at https://replicate.com/talshaharabany/what-is-where-by-looking.
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Nov 29, 2021
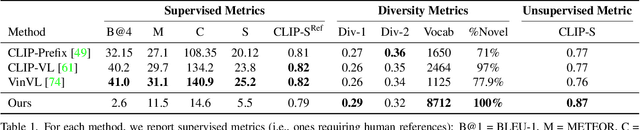
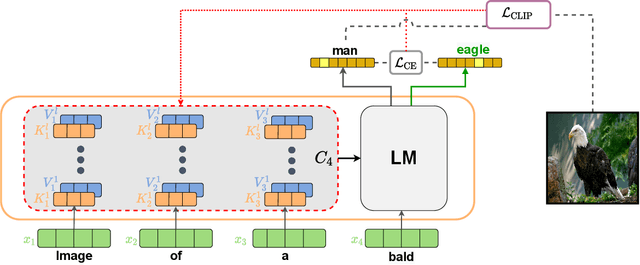

Recent text-to-image matching models apply contrastive learning to large corpora of uncurated pairs of images and sentences. While such models can provide a powerful score for matching and subsequent zero-shot tasks, they are not capable of generating caption given an image. In this work, we repurpose such models to generate a descriptive text given an image at inference time, without any further training or tuning step. This is done by combining the visual-semantic model with a large language model, benefiting from the knowledge in both web-scale models. The resulting captions are much less restrictive than those obtained by supervised captioning methods. Moreover, as a zero-shot learning method, it is extremely flexible and we demonstrate its ability to perform image arithmetic in which the inputs can be either images or text and the output is a sentence. This enables novel high-level vision capabilities such as comparing two images or solving visual analogy tests.