 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Video Captioning with Evolving Pseudo-Tokens
Jul 27, 2022
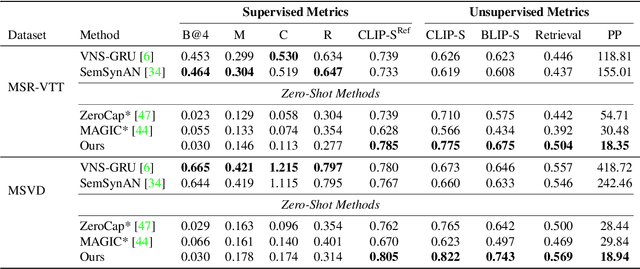
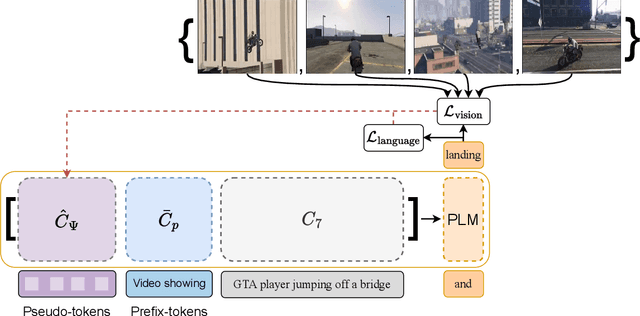
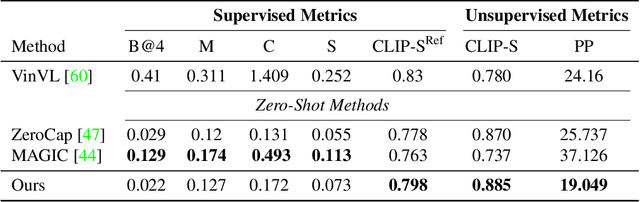
We introduce a zero-shot video captioning method that employs two frozen networks: the GPT-2 language model and the CLIP image-text matching model. The matching score is used to steer the language model toward generating a sentence that has a high average matching score to a subset of the video frames. Unlike zero-shot image captioning methods, our work considers the entire sentence at once. This is achieved by optimizing, during the generation process, part of the prompt from scratch, by modifying the representation of all other tokens in the prompt, and by repeating the process iteratively, gradually improving the specificity and comprehensiveness of the generated sentence. Our experiments show that the generated captions are coherent and display a broad range of real-world knowledge. Our code is available at: https://github.com/YoadTew/zero-shot-video-to-text