 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Video Captioning with Evolving Pseudo-Tokens
Jul 27, 2022
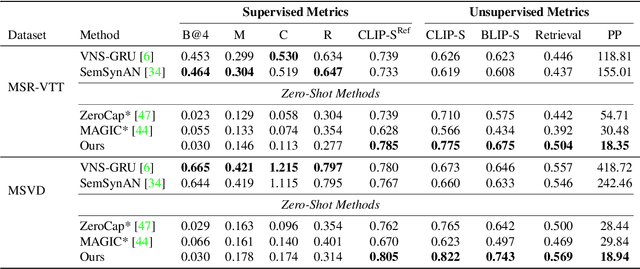
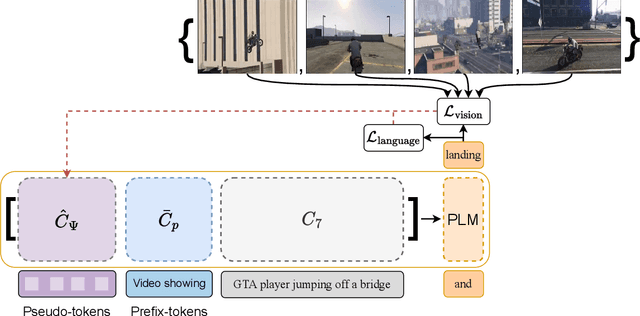
We introduce a zero-shot video captioning method that employs two frozen networks: the GPT-2 language model and the CLIP image-text matching model. The matching score is used to steer the language model toward generating a sentence that has a high average matching score to a subset of the video frames. Unlike zero-shot image captioning methods, our work considers the entire sentence at once. This is achieved by optimizing, during the generation process, part of the prompt from scratch, by modifying the representation of all other tokens in the prompt, and by repeating the process iteratively, gradually improving the specificity and comprehensiveness of the generated sentence. Our experiments show that the generated captions are coherent and display a broad range of real-world knowledge. Our code is available at: https://github.com/YoadTew/zero-shot-video-to-text
End to End Lip Synchronization with a Temporal AutoEncoder
Mar 30, 2022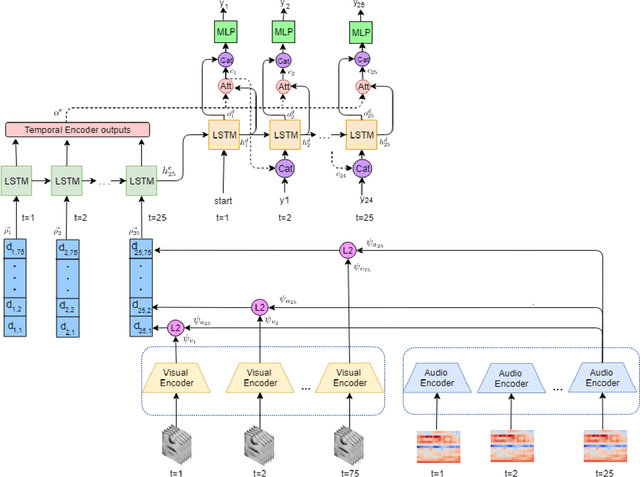
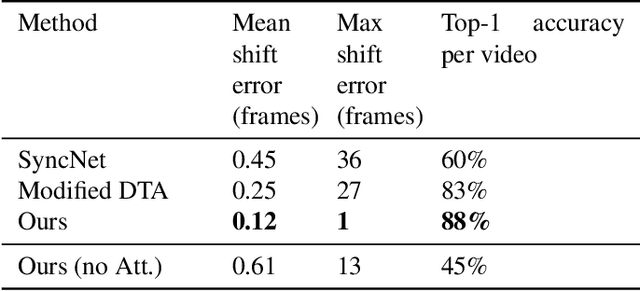
We study the problem of syncing the lip movement in a video with the audio stream. Our solution finds an optimal alignment using a dual-domain recurrent neural network that is trained on synthetic data we generate by dropping and duplicating video frames. Once the alignment is found, we modify the video in order to sync the two sources. Our method is shown to greatly outperform the literature methods on a variety of existing and new benchmarks. As an application, we demonstrate our ability to robustly align text-to-speech generated audio with an existing video stream. Our code and samples are available at https://github.com/itsyoavshalev/End-to-End-Lip-Synchronization-with-a-Temporal-AutoEncoder.
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Nov 29, 2021
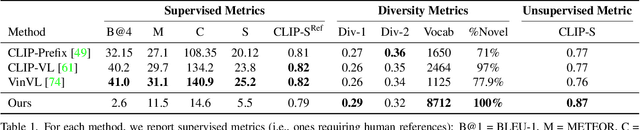
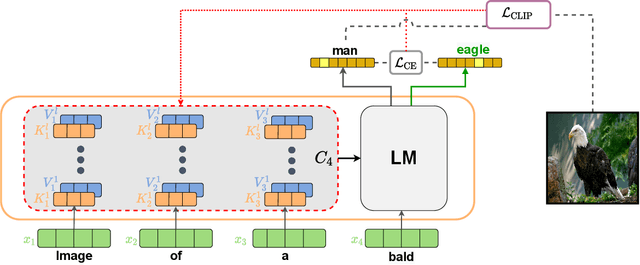

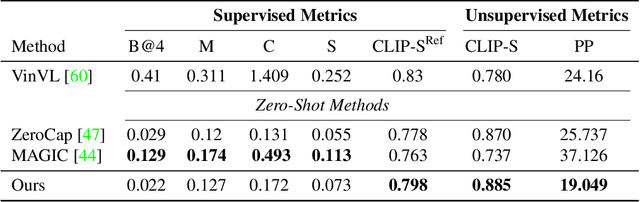
Recent text-to-image matching models apply contrastive learning to large corpora of uncurated pairs of images and sentences. While such models can provide a powerful score for matching and subsequent zero-shot tasks, they are not capable of generating caption given an image. In this work, we repurpose such models to generate a descriptive text given an image at inference time, without any further training or tuning step. This is done by combining the visual-semantic model with a large language model, benefiting from the knowledge in both web-scale models. The resulting captions are much less restrictive than those obtained by supervised captioning methods. Moreover, as a zero-shot learning method, it is extremely flexible and we demonstrate its ability to perform image arithmetic in which the inputs can be either images or text and the output is a sentence. This enables novel high-level vision capabilities such as comparing two images or solving visual analogy tests.
Image Animation with Perturbed Masks
Nov 18, 2020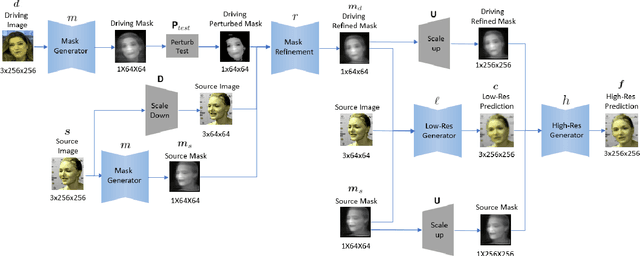
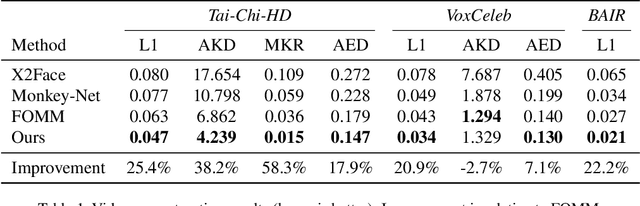
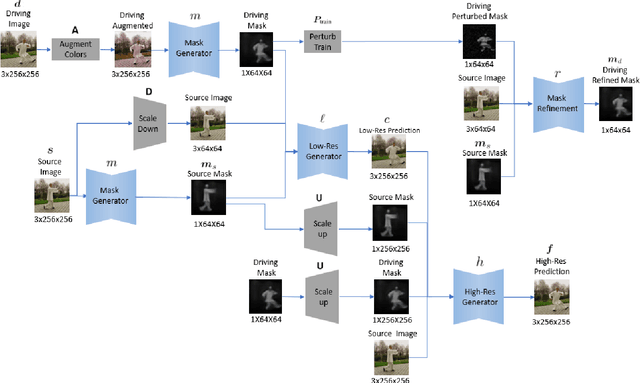
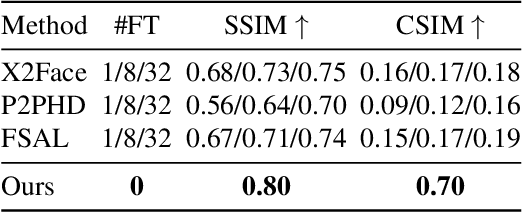
We present a novel approach for image-animation of a source image by a driving video, both depicting the same type of object. We do not assume the existence of pose models and our method is able to animate arbitrary objects without knowledge of the object's structure. Furthermore, both the driving video and the source image are only seen during test-time. Our method is based on a shared mask generator, which separates the foreground object from its background, and captures the object's general pose and shape. A mask-refinement module then replaces, in the mask extracted from the driver image, the identity of the driver with the identity of the source. Conditioned on the source image, the transformed mask is then decoded by a multi-scale generator that renders a realistic image, in which the content of the source frame is animated by the pose in the driving video. Due to lack of fully supervised data, we train on the task of reconstructing frames from the same video the source image is taken from. In order to control {the} source of the identity of the output frame, we employ during training perturbations that remove the unwanted identity information. Our method is shown to greatly outperform the state of the art methods on multiple benchmarks. Our code and samples are available at https://github.com/itsyoavshalev/Image-Animation-with-Perturbed-Masks