 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Shot Character Consistency for Text-to-Video Generation
Dec 10, 2024

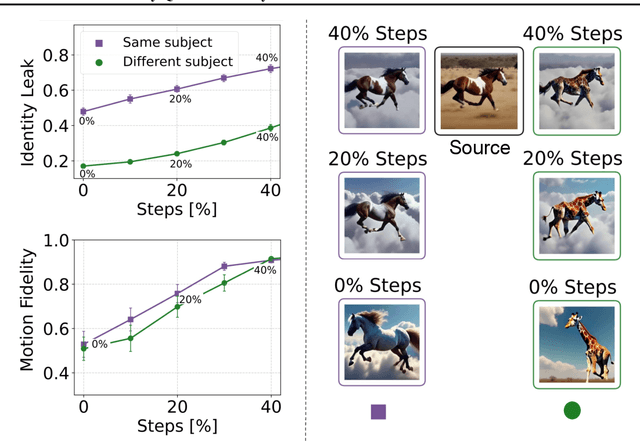

Text-to-video models have made significant strides in generating short video clips from textual descriptions. Yet, a significant challenge remains: generating several video shots of the same characters, preserving their identity without hurting video quality, dynamics, and responsiveness to text prompts. We present Video Storyboarding, a training-free method to enable pretrained text-to-video models to generate multiple shots with consistent characters, by sharing features between them. Our key insight is that self-attention query features (Q) encode both motion and identity. This creates a hard-to-avoid trade-off between preserving character identity and making videos dynamic, when features are shared. To address this issue, we introduce a novel query injection strategy that balances identity preservation and natural motion retention. This approach improves upon naive consistency techniques applied to videos, which often struggle to maintain this delicate equilibrium. Our experiments demonstrate significant improvements in character consistency across scenes while maintaining high-quality motion and text alignment. These results offer insights into critical stages of video generation and the interplay of structure and motion in video diffusion models.
Add-it: Training-Free Object Insertion in Images With Pretrained Diffusion Models
Nov 12, 2024
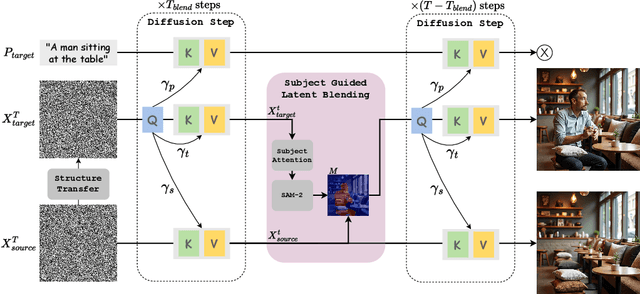
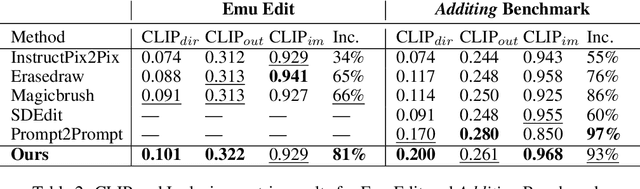
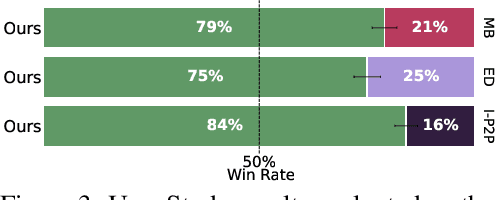
Adding Object into images based on text instructions is a challenging task in semantic image editing, requiring a balance between preserving the original scene and seamlessly integrating the new object in a fitting location. Despite extensive efforts, existing models often struggle with this balance, particularly with finding a natural location for adding an object in complex scenes. We introduce Add-it, a training-free approach that extends diffusion models' attention mechanisms to incorporate information from three key sources: the scene image, the text prompt, and the generated image itself. Our weighted extended-attention mechanism maintains structural consistency and fine details while ensuring natural object placement. Without task-specific fine-tuning, Add-it achieves state-of-the-art results on both real and generated image insertion benchmarks, including our newly constructed "Additing Affordance Benchmark" for evaluating object placement plausibility, outperforming supervised methods. Human evaluations show that Add-it is preferred in over 80% of cases, and it also demonstrates improvements in various automated metrics.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
Lay-A-Scene: Personalized 3D Object Arrangement Using Text-to-Image Priors
Jun 04, 2024Generating 3D visual scenes is at the forefront of visual generative AI, but current 3D generation techniques struggle with generating scenes with multiple high-resolution objects. Here we introduce Lay-A-Scene, which solves the task of Open-set 3D Object Arrangement, effectively arranging unseen objects. Given a set of 3D objects, the task is to find a plausible arrangement of these objects in a scene. We address this task by leveraging pre-trained text-to-image models. We personalize the model and explain how to generate images of a scene that contains multiple predefined objects without neglecting any of them. Then, we describe how to infer the 3D poses and arrangement of objects from a 2D generated image by finding a consistent projection of objects onto the 2D scene. We evaluate the quality of Lay-A-Scene using 3D objects from Objaverse and human raters and find that it often generates coherent and feasible 3D object arrangements.
Training-Free Consistent Text-to-Image Generation
Feb 05, 2024Text-to-image models offer a new level of creative flexibility by allowing users to guide the image generation process through natural language. However, using these models to consistently portray the same subject across diverse prompts remains challenging. Existing approaches fine-tune the model to teach it new words that describe specific user-provided subjects or add image conditioning to the model. These methods require lengthy per-subject optimization or large-scale pre-training. Moreover, they struggle to align generated images with text prompts and face difficulties in portraying multiple subjects. Here, we present ConsiStory, a training-free approach that enables consistent subject generation by sharing the internal activations of the pretrained model. We introduce a subject-driven shared attention block and correspondence-based feature injection to promote subject consistency between images. Additionally, we develop strategies to encourage layout diversity while maintaining subject consistency. We compare ConsiStory to a range of baselines, and demonstrate state-of-the-art performance on subject consistency and text alignment, without requiring a single optimization step. Finally, ConsiStory can naturally extend to multi-subject scenarios, and even enable training-free personalization for common objects.
Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models
Jul 13, 2023Text-to-image (T2I) personalization allows users to guide the creative image generation process by combining their own visual concepts in natural language prompts. Recently, encoder-based techniques have emerged as a new effective approach for T2I personalization, reducing the need for multiple images and long training times. However, most existing encoders are limited to a single-class domain, which hinders their ability to handle diverse concepts. In this work, we propose a domain-agnostic method that does not require any specialized dataset or prior information about the personalized concepts. We introduce a novel contrastive-based regularization technique to maintain high fidelity to the target concept characteristics while keeping the predicted embeddings close to editable regions of the latent space, by pushing the predicted tokens toward their nearest existing CLIP tokens. Our experimental results demonstrate the effectiveness of our approach and show how the learned tokens are more semantic than tokens predicted by unregularized models. This leads to a better representation that achieves state-of-the-art performance while being more flexible than previous methods.
Key-Locked Rank One Editing for Text-to-Image Personalization
May 02, 2023



Text-to-image models (T2I) offer a new level of flexibility by allowing users to guide the creative process through natural language. However, personalizing these models to align with user-provided visual concepts remains a challenging problem. The task of T2I personalization poses multiple hard challenges, such as maintaining high visual fidelity while allowing creative control, combining multiple personalized concepts in a single image, and keeping a small model size. We present Perfusion, a T2I personalization method that addresses these challenges using dynamic rank-1 updates to the underlying T2I model. Perfusion avoids overfitting by introducing a new mechanism that "locks" new concepts' cross-attention Keys to their superordinate category. Additionally, we develop a gated rank-1 approach that enables us to control the influence of a learned concept during inference time and to combine multiple concepts. This allows runtime-efficient balancing of visual-fidelity and textual-alignment with a single 100KB trained model, which is five orders of magnitude smaller than the current state of the art. Moreover, it can span different operating points across the Pareto front without additional training. Finally, we show that Perfusion outperforms strong baselines in both qualitative and quantitative terms. Importantly, key-locking leads to novel results compared to traditional approaches, allowing to portray personalized object interactions in unprecedented ways, even in one-shot settings.
Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models
Mar 05, 2023Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Aug 02, 2022
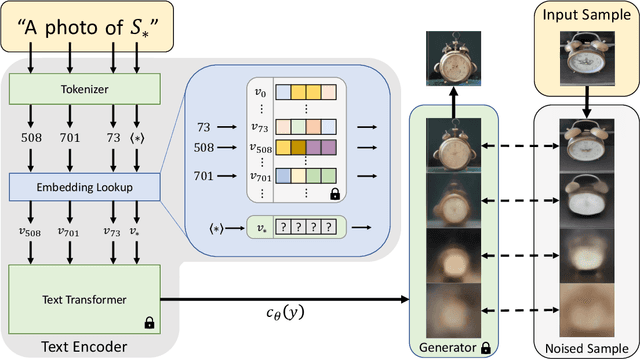


Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and novel scenes. In other words, we ask: how can we use language-guided models to turn our cat into a painting, or imagine a new product based on our favorite toy? Here we present a simple approach that allows such creative freedom. Using only 3-5 images of a user-provided concept, like an object or a style, we learn to represent it through new "words" in the embedding space of a frozen text-to-image model. These "words" can be composed into natural language sentences, guiding personalized creation in an intuitive way. Notably, we find evidence that a single word embedding is sufficient for capturing unique and varied concepts. We compare our approach to a wide range of baselines, and demonstrate that it can more faithfully portray the concepts across a range of applications and tasks. Our code, data and new words will be available at: https://textual-inversion.github.io
"This is my unicorn, Fluffy": Personalizing frozen vision-language representations
Apr 04, 2022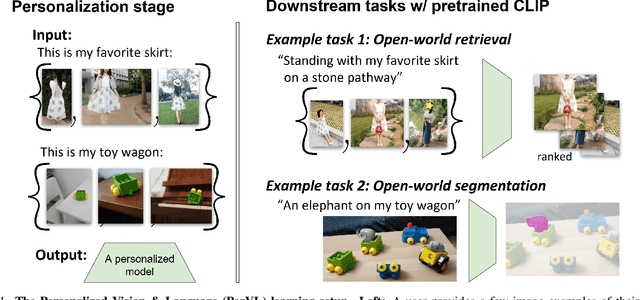
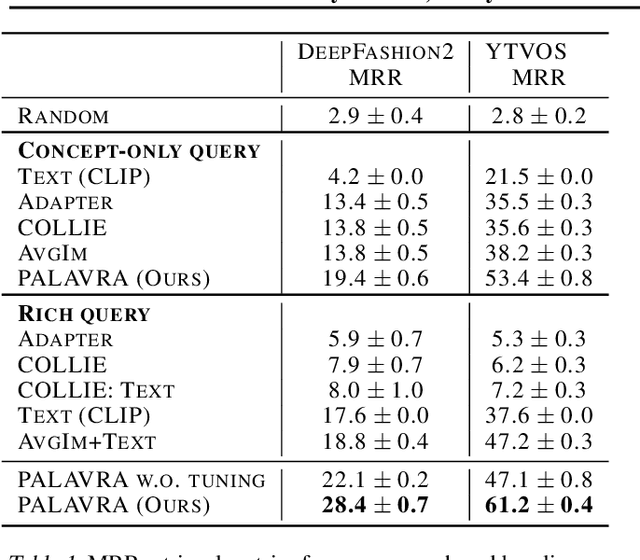
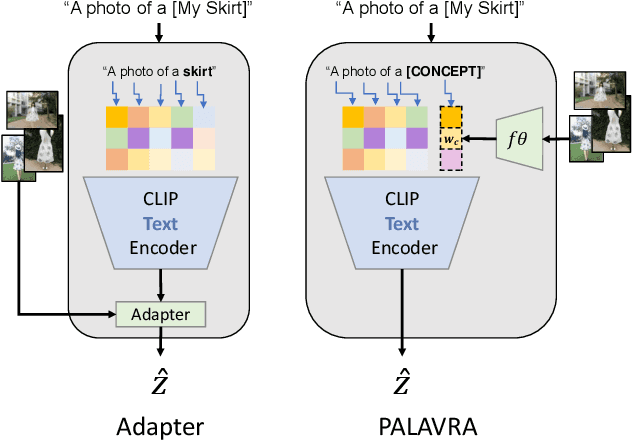

Large Vision & Language models pretrained on web-scale data provide representations that are invaluable for numerous V&L problems. However, it is unclear how they can be used for reasoning about user-specific visual concepts in unstructured language. This problem arises in multiple domains, from personalized image retrieval to personalized interaction with smart devices. We introduce a new learning setup called Personalized Vision & Language (PerVL) with two new benchmark datasets for retrieving and segmenting user-specific "personalized" concepts "in the wild". In PerVL, one should learn personalized concepts (1) independently of the downstream task (2) allowing a pretrained model to reason about them with free language, and (3) does not require personalized negative examples. We propose an architecture for solving PerVL that operates by extending the input vocabulary of a pretrained model with new word embeddings for the new personalized concepts. The model can then reason about them by simply using them in a sentence. We demonstrate that our approach learns personalized visual concepts from a few examples and can effectively apply them in image retrieval and semantic segmentation using rich textual queries.