 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"This is my unicorn, Fluffy": Personalizing frozen vision-language representations
Paper and Code
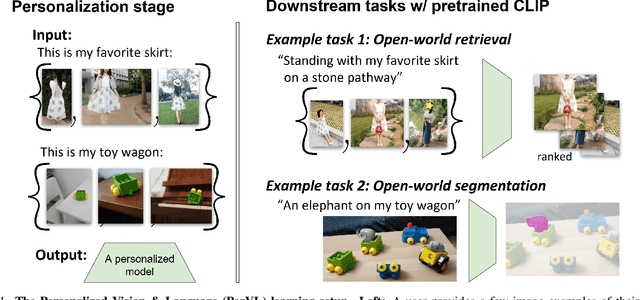
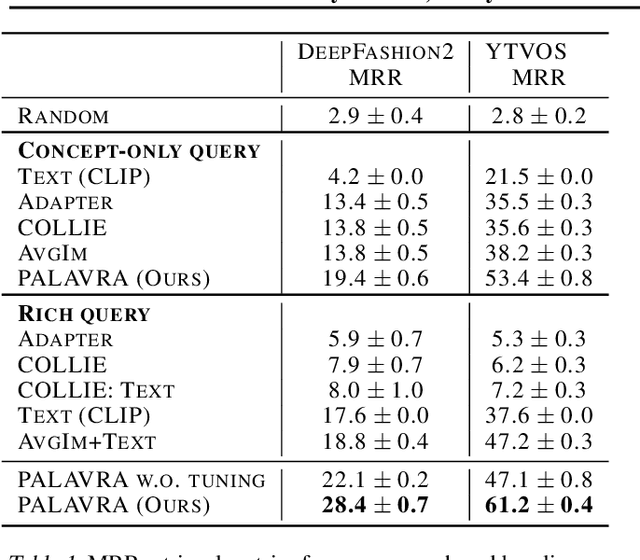
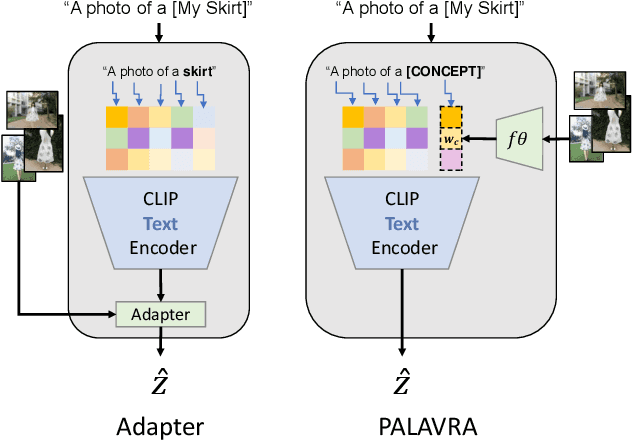

Large Vision & Language models pretrained on web-scale data provide representations that are invaluable for numerous V&L problems. However, it is unclear how they can be used for reasoning about user-specific visual concepts in unstructured language. This problem arises in multiple domains, from personalized image retrieval to personalized interaction with smart devices. We introduce a new learning setup called Personalized Vision & Language (PerVL) with two new benchmark datasets for retrieving and segmenting user-specific "personalized" concepts "in the wild". In PerVL, one should learn personalized concepts (1) independently of the downstream task (2) allowing a pretrained model to reason about them with free language, and (3) does not require personalized negative examples. We propose an architecture for solving PerVL that operates by extending the input vocabulary of a pretrained model with new word embeddings for the new personalized concepts. The model can then reason about them by simply using them in a sentence. We demonstrate that our approach learns personalized visual concepts from a few examples and can effectively apply them in image retrieval and semantic segmentation using rich textual queries.