 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Watermarking for Autoregressive Image Generation
Apr 13, 2026The proliferation of autoregressive (AR) image generators demands reliable detection and attribution of their outputs to mitigate misinformation, and to filter synthetic images from training data to prevent model collapse. To address this need, watermarking techniques, specifically designed for AR models, embed a subtle signal at generation time, enabling downstream verification through a corresponding watermark detector. In this work, we study these schemes and demonstrate their vulnerability to both watermark removal and forgery attacks. We assess existing attacks and further introduce three new attacks: (i) a vector-quantized regeneration removal attack, (ii) adversarial optimization-based attack, and (iii) a frequency injection attack. Our evaluation reveals that removal and forgery attacks can be effective with access to a single watermarked reference image and without access to original model parameters or watermarking secrets. Our findings indicate that existing watermarking schemes for AR image generation do not reliably support synthetic content detection for dataset filtering. Moreover, they enable Watermark Mimicry, whereby authentic images can be manipulated to imitate a generator's watermark and trigger false detection to prevent their inclusion in future model training.
Understanding Empirical Unlearning with Combinatorial Interpretability
Feb 22, 2026While many recent methods aim to unlearn or remove knowledge from pretrained models, seemingly erased knowledge often persists and can be recovered in various ways. Because large foundation models are far from interpretable, understanding whether and how such knowledge persists remains a significant challenge. To address this, we turn to the recently developed framework of combinatorial interpretability. This framework, designed for two-layer neural networks, enables direct inspection of the knowledge encoded in the model weights. We reproduce baseline unlearning methods within the combinatorial interpretability setting and examine their behavior along two dimensions: (i) whether they truly remove knowledge of a target concept (the concept we wish to remove) or merely inhibit its expression while retaining the underlying information, and (ii) how easily the supposedly erased knowledge can be recovered through various fine-tuning operations. Our results shed light within a fully interpretable setting on how knowledge can persist despite unlearning and when it might resurface.
When Are Concepts Erased From Diffusion Models?
May 22, 2025Concept erasure, the ability to selectively prevent a model from generating specific concepts, has attracted growing interest, with various approaches emerging to address the challenge. However, it remains unclear how thoroughly these methods erase the target concept. We begin by proposing two conceptual models for the erasure mechanism in diffusion models: (i) reducing the likelihood of generating the target concept, and (ii) interfering with the model's internal guidance mechanisms. To thoroughly assess whether a concept has been truly erased from the model, we introduce a suite of independent evaluations. Our evaluation framework includes adversarial attacks, novel probing techniques, and analysis of the model's alternative generations in place of the erased concept. Our results shed light on the tension between minimizing side effects and maintaining robustness to adversarial prompts. Broadly, our work underlines the importance of comprehensive evaluation for erasure in diffusion models.
Forging and Removing Latent-Noise Diffusion Watermarks Using a Single Image
Apr 27, 2025Watermarking techniques are vital for protecting intellectual property and preventing fraudulent use of media. Most previous watermarking schemes designed for diffusion models embed a secret key in the initial noise. The resulting pattern is often considered hard to remove and forge into unrelated images. In this paper, we propose a black-box adversarial attack without presuming access to the diffusion model weights. Our attack uses only a single watermarked example and is based on a simple observation: there is a many-to-one mapping between images and initial noises. There are regions in the clean image latent space pertaining to each watermark that get mapped to the same initial noise when inverted. Based on this intuition, we propose an adversarial attack to forge the watermark by introducing perturbations to the images such that we can enter the region of watermarked images. We show that we can also apply a similar approach for watermark removal by learning perturbations to exit this region. We report results on multiple watermarking schemes (Tree-Ring, RingID, WIND, and Gaussian Shading) across two diffusion models (SDv1.4 and SDv2.0). Our results demonstrate the effectiveness of the attack and expose vulnerabilities in the watermarking methods, motivating future research on improving them.
SEAL: Semantic Aware Image Watermarking
Mar 15, 2025Generative models have rapidly evolved to generate realistic outputs. However, their synthetic outputs increasingly challenge the clear distinction between natural and AI-generated content, necessitating robust watermarking techniques. Watermarks are typically expected to preserve the integrity of the target image, withstand removal attempts, and prevent unauthorized replication onto unrelated images. To address this need, recent methods embed persistent watermarks into images produced by diffusion models using the initial noise. Yet, to do so, they either distort the distribution of generated images or rely on searching through a long dictionary of used keys for detection. In this paper, we propose a novel watermarking method that embeds semantic information about the generated image directly into the watermark, enabling a distortion-free watermark that can be verified without requiring a database of key patterns. Instead, the key pattern can be inferred from the semantic embedding of the image using locality-sensitive hashing. Furthermore, conditioning the watermark detection on the original image content improves robustness against forgery attacks. To demonstrate that, we consider two largely overlooked attack strategies: (i) an attacker extracting the initial noise and generating a novel image with the same pattern; (ii) an attacker inserting an unrelated (potentially harmful) object into a watermarked image, possibly while preserving the watermark. We empirically validate our method's increased robustness to these attacks. Taken together, our results suggest that content-aware watermarks can mitigate risks arising from image-generative models.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Hidden in the Noise: Two-Stage Robust Watermarking for Images
Dec 05, 2024As the quality of image generators continues to improve, deepfakes become a topic of considerable societal debate. Image watermarking allows responsible model owners to detect and label their AI-generated content, which can mitigate the harm. Yet, current state-of-the-art methods in image watermarking remain vulnerable to forgery and removal attacks. This vulnerability occurs in part because watermarks distort the distribution of generated images, unintentionally revealing information about the watermarking techniques. In this work, we first demonstrate a distortion-free watermarking method for images, based on a diffusion model's initial noise. However, detecting the watermark requires comparing the initial noise reconstructed for an image to all previously used initial noises. To mitigate these issues, we propose a two-stage watermarking framework for efficient detection. During generation, we augment the initial noise with generated Fourier patterns to embed information about the group of initial noises we used. For detection, we (i) retrieve the relevant group of noises, and (ii) search within the given group for an initial noise that might match our image. This watermarking approach achieves state-of-the-art robustness to forgery and removal against a large battery of attacks.
SELECT: A Large-Scale Benchmark of Data Curation Strategies for Image Classification
Oct 07, 2024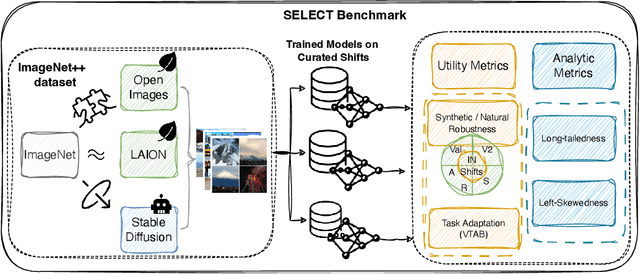
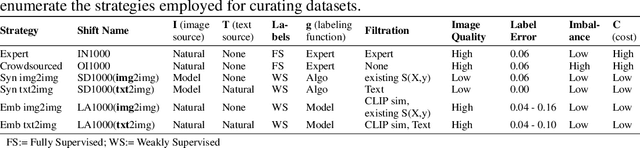

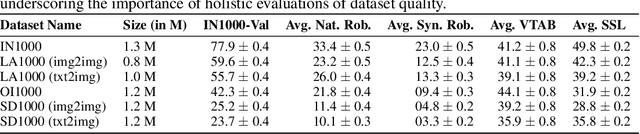
Data curation is the problem of how to collect and organize samples into a dataset that supports efficient learning. Despite the centrality of the task, little work has been devoted towards a large-scale, systematic comparison of various curation methods. In this work, we take steps towards a formal evaluation of data curation strategies and introduce SELECT, the first large-scale benchmark of curation strategies for image classification. In order to generate baseline methods for the SELECT benchmark, we create a new dataset, ImageNet++, which constitutes the largest superset of ImageNet-1K to date. Our dataset extends ImageNet with 5 new training-data shifts, each approximately the size of ImageNet-1K itself, and each assembled using a distinct curation strategy. We evaluate our data curation baselines in two ways: (i) using each training-data shift to train identical image classification models from scratch (ii) using the data itself to fit a pretrained self-supervised representation. Our findings show interesting trends, particularly pertaining to recent methods for data curation such as synthetic data generation and lookup based on CLIP embeddings. We show that although these strategies are highly competitive for certain tasks, the curation strategy used to assemble the original ImageNet-1K dataset remains the gold standard. We anticipate that our benchmark can illuminate the path for new methods to further reduce the gap. We release our checkpoints, code, documentation, and a link to our dataset at https://github.com/jimmyxu123/SELECT.
Dataset and Lessons Learned from the 2024 SaTML LLM Capture-the-Flag Competition
Jun 12, 2024



Large language model systems face important security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
Robust Concept Erasure Using Task Vectors
Apr 04, 2024
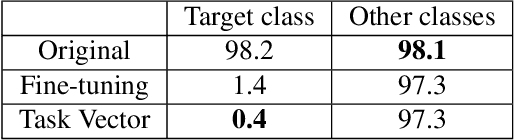
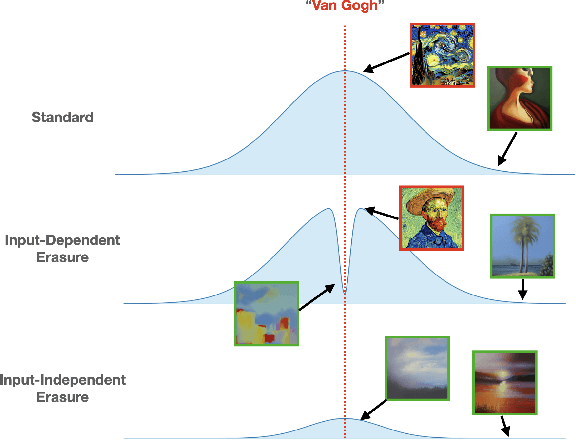
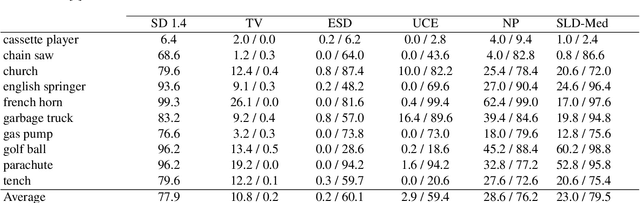
With the rapid growth of text-to-image models, a variety of techniques have been suggested to prevent undesirable image generations. Yet, these methods often only protect against specific user prompts and have been shown to allow unsafe generations with other inputs. Here we focus on unconditionally erasing a concept from a text-to-image model rather than conditioning the erasure on the user's prompt. We first show that compared to input-dependent erasure methods, concept erasure that uses Task Vectors (TV) is more robust to unexpected user inputs, not seen during training. However, TV-based erasure can also affect the core performance of the edited model, particularly when the required edit strength is unknown. To this end, we propose a method called Diverse Inversion, which we use to estimate the required strength of the TV edit. Diverse Inversion finds within the model input space a large set of word embeddings, each of which induces the generation of the target concept. We find that encouraging diversity in the set makes our estimation more robust to unexpected prompts. Finally, we show that Diverse Inversion enables us to apply a TV edit only to a subset of the model weights, enhancing the erasure capabilities while better maintaining the core functionality of the model.