 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Photorealistic Simplification
May 11, 2026Existing image simplification techniques often rely on Non-Photorealistic Rendering (NPR), transforming photographs into stylized sketches, cartoons, or paintings. While effective at reducing visual complexity, such approaches typically sacrifice photographic realism. In this work, we explore a complementary direction: simplifying images while preserving their photorealistic appearance. We introduce progressive semantic image simplification, a framework that iteratively reduces scene complexity by removing and inpainting elements in a controlled manner. At each step, the resulting image remains a plausible natural photograph. Our method combines semantic understanding with generative editing, leveraging Vision-Language Models (VLMs) to identify and prioritize elements for removal, and a learned verifier to ensure photorealism and coherence throughout the process. This is implemented via an iterative Select-Remove-Verify pipeline that produces high-quality simplification trajectories. To improve efficiency, we further distill this process into an image-to-video generation model that directly predicts coherent simplification sequences from a single input image. Beyond generating cleaner and more focused compositions, our approach enables applications such as content-aware decluttering, semantic layer decomposition, and interactive editing. More broadly, our work suggests that simplification through structured content removal can serve as a practical mechanism for guiding visual interpretation within the photorealistic domain, complementing traditional abstraction methods.
A Dataset is Worth 1 MB
Feb 26, 2026A dataset server must often distribute the same large payload to many clients, incurring massive communication costs. Since clients frequently operate on diverse hardware and software frameworks, transmitting a pre-trained model is often infeasible; instead, agents require raw data to train their own task-specific models locally. While dataset distillation attempts to compress training signals, current methods struggle to scale to high-resolution data and rarely achieve sufficiently small files. In this paper, we propose Pseudo-Labels as Data (PLADA), a method that completely eliminates pixel transmission. We assume agents are preloaded with a large, generic, unlabeled reference dataset (e.g., ImageNet-1K, ImageNet-21K) and communicate a new task by transmitting only the class labels for specific images. To address the distribution mismatch between the reference and target datasets, we introduce a pruning mechanism that filters the reference dataset to retain only the labels of the most semantically relevant images for the target task. This selection process simultaneously maximizes training efficiency and minimizes transmission payload. Experiments on 10 diverse datasets demonstrate that our approach can transfer task knowledge with a payload of less than 1 MB while retaining high classification accuracy, offering a promising solution for efficient dataset serving.
Discovering Hidden Gems in Model Repositories
Jan 29, 2026Public repositories host millions of fine-tuned models, yet community usage remains disproportionately concentrated on a small number of foundation checkpoints. We investigate whether this concentration reflects efficient market selection or if superior models are systematically overlooked. Through an extensive evaluation of over 2,000 models, we show the prevalence of "hidden gems", unpopular fine-tunes that significantly outperform their popular counterparts. Notably, within the Llama-3.1-8B family, we find rarely downloaded checkpoints that improve math performance from 83.2% to 96.0% without increasing inference costs. However, discovering these models through exhaustive evaluation of every uploaded model is computationally infeasible. We therefore formulate model discovery as a Multi-Armed Bandit problem and accelerate the Sequential Halving search algorithm by using shared query sets and aggressive elimination schedules. Our method retrieves top models with as few as 50 queries per candidate, accelerating discovery by over 50x.
Alterbute: Editing Intrinsic Attributes of Objects in Images
Jan 15, 2026We introduce Alterbute, a diffusion-based method for editing an object's intrinsic attributes in an image. We allow changing color, texture, material, and even the shape of an object, while preserving its perceived identity and scene context. Existing approaches either rely on unsupervised priors that often fail to preserve identity or use overly restrictive supervision that prevents meaningful intrinsic variations. Our method relies on: (i) a relaxed training objective that allows the model to change both intrinsic and extrinsic attributes conditioned on an identity reference image, a textual prompt describing the target intrinsic attributes, and a background image and object mask defining the extrinsic context. At inference, we restrict extrinsic changes by reusing the original background and object mask, thereby ensuring that only the desired intrinsic attributes are altered; (ii) Visual Named Entities (VNEs) - fine-grained visual identity categories (e.g., ''Porsche 911 Carrera'') that group objects sharing identity-defining features while allowing variation in intrinsic attributes. We use a vision-language model to automatically extract VNE labels and intrinsic attribute descriptions from a large public image dataset, enabling scalable, identity-preserving supervision. Alterbute outperforms existing methods on identity-preserving object intrinsic attribute editing.
LightLab: Controlling Light Sources in Images with Diffusion Models
May 14, 2025We present a simple, yet effective diffusion-based method for fine-grained, parametric control over light sources in an image. Existing relighting methods either rely on multiple input views to perform inverse rendering at inference time, or fail to provide explicit control over light changes. Our method fine-tunes a diffusion model on a small set of real raw photograph pairs, supplemented by synthetically rendered images at scale, to elicit its photorealistic prior for relighting. We leverage the linearity of light to synthesize image pairs depicting controlled light changes of either a target light source or ambient illumination. Using this data and an appropriate fine-tuning scheme, we train a model for precise illumination changes with explicit control over light intensity and color. Lastly, we show how our method can achieve compelling light editing results, and outperforms existing methods based on user preference.
Charting and Navigating Hugging Face's Model Atlas
Mar 13, 2025



As there are now millions of publicly available neural networks, searching and analyzing large model repositories becomes increasingly important. Navigating so many models requires an atlas, but as most models are poorly documented charting such an atlas is challenging. To explore the hidden potential of model repositories, we chart a preliminary atlas representing the documented fraction of Hugging Face. It provides stunning visualizations of the model landscape and evolution. We demonstrate several applications of this atlas including predicting model attributes (e.g., accuracy), and analyzing trends in computer vision models. However, as the current atlas remains incomplete, we propose a method for charting undocumented regions. Specifically, we identify high-confidence structural priors based on dominant real-world model training practices. Leveraging these priors, our approach enables accurate mapping of previously undocumented areas of the atlas. We publicly release our datasets, code, and interactive atlas.
Can this Model Also Recognize Dogs? Zero-Shot Model Search from Weights
Feb 13, 2025



With the increasing numbers of publicly available models, there are probably pretrained, online models for most tasks users require. However, current model search methods are rudimentary, essentially a text-based search in the documentation, thus users cannot find the relevant models. This paper presents ProbeLog, a method for retrieving classification models that can recognize a target concept, such as "Dog", without access to model metadata or training data. Differently from previous probing methods, ProbeLog computes a descriptor for each output dimension (logit) of each model, by observing its responses on a fixed set of inputs (probes). Our method supports both logit-based retrieval ("find more logits like this") and zero-shot, text-based retrieval ("find all logits corresponding to dogs"). As probing-based representations require multiple costly feedforward passes through the model, we develop a method, based on collaborative filtering, that reduces the cost of encoding repositories by 3x. We demonstrate that ProbeLog achieves high retrieval accuracy, both in real-world and fine-grained search tasks and is scalable to full-size repositories.
ObjectMate: A Recurrence Prior for Object Insertion and Subject-Driven Generation
Dec 11, 2024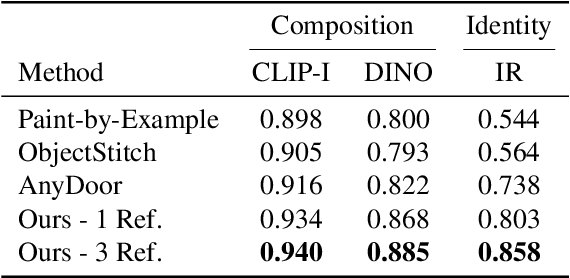

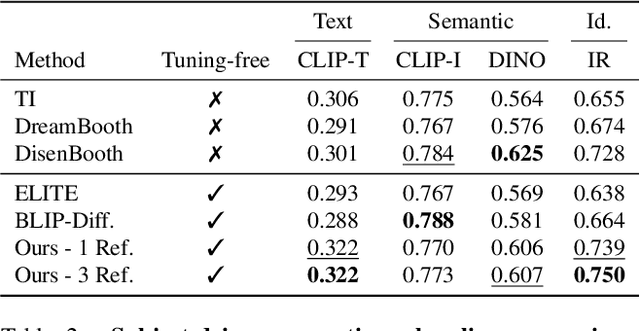
This paper introduces a tuning-free method for both object insertion and subject-driven generation. The task involves composing an object, given multiple views, into a scene specified by either an image or text. Existing methods struggle to fully meet the task's challenging objectives: (i) seamlessly composing the object into the scene with photorealistic pose and lighting, and (ii) preserving the object's identity. We hypothesize that achieving these goals requires large scale supervision, but manually collecting sufficient data is simply too expensive. The key observation in this paper is that many mass-produced objects recur across multiple images of large unlabeled datasets, in different scenes, poses, and lighting conditions. We use this observation to create massive supervision by retrieving sets of diverse views of the same object. This powerful paired dataset enables us to train a straightforward text-to-image diffusion architecture to map the object and scene descriptions to the composited image. We compare our method, ObjectMate, with state-of-the-art methods for object insertion and subject-driven generation, using a single or multiple references. Empirically, ObjectMate achieves superior identity preservation and more photorealistic composition. Differently from many other multi-reference methods, ObjectMate does not require slow test-time tuning.
Representing Model Weights with Language using Tree Experts
Oct 17, 2024



The increasing availability of public models begs the question: can we train neural networks that use other networks as input? This paper learns to represent models within a joint space that embeds both model weights and language. However, machine learning on model weights is challenging as model weights often exhibit significant variation unrelated to the models' semantic properties (nuisance variation). We identify a key property of real-world models: most public models belong to a small set of Model Trees, where all models within a tree are fine-tuned from a common ancestor (e.g., a foundation model). Importantly, we find that within each tree there is less nuisance variation between models. For example, while classifying models according to their training dataset generally requires complex architectures, in our case, even a linear classifier trained on a single layer is often effective. While effective, linear layers are computationally expensive as model weights are very high dimensional. To address this, we introduce Probing Experts (ProbeX), a theoretically motivated, lightweight probing method. Notably, ProbeX is the first probing method designed to learn from the weights of just a single model layer. We also construct and release a dataset that simulates the structure of public model repositories. Our results show that ProbeX can effectively map the weights of large models into a shared weight-language embedding space. Furthermore, we demonstrate the impressive generalization of our method, achieving zero-shot model classification and retrieval.
Deep Linear Probe Generators for Weight Space Learning
Oct 14, 2024



Weight space learning aims to extract information about a neural network, such as its training dataset or generalization error. Recent approaches learn directly from model weights, but this presents many challenges as weights are high-dimensional and include permutation symmetries between neurons. An alternative approach, Probing, represents a model by passing a set of learned inputs (probes) through the model, and training a predictor on top of the corresponding outputs. Although probing is typically not used as a stand alone approach, our preliminary experiment found that a vanilla probing baseline worked surprisingly well. However, we discover that current probe learning strategies are ineffective. We therefore propose Deep Linear Probe Generators (ProbeGen), a simple and effective modification to probing approaches. ProbeGen adds a shared generator module with a deep linear architecture, providing an inductive bias towards structured probes thus reducing overfitting. While simple, ProbeGen performs significantly better than the state-of-the-art and is very efficient, requiring between 30 to 1000 times fewer FLOPs than other top approaches.