 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectMate: A Recurrence Prior for Object Insertion and Subject-Driven Generation
Dec 11, 2024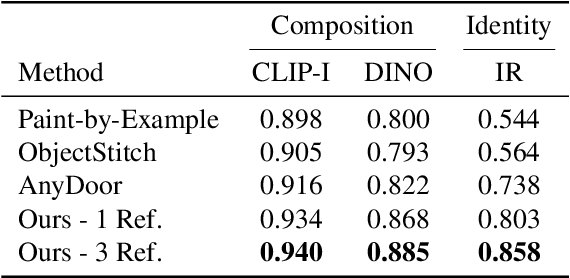

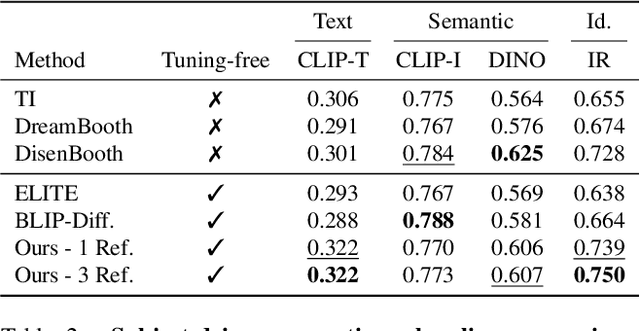
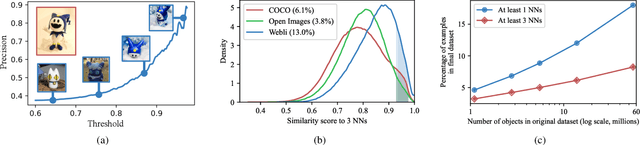
This paper introduces a tuning-free method for both object insertion and subject-driven generation. The task involves composing an object, given multiple views, into a scene specified by either an image or text. Existing methods struggle to fully meet the task's challenging objectives: (i) seamlessly composing the object into the scene with photorealistic pose and lighting, and (ii) preserving the object's identity. We hypothesize that achieving these goals requires large scale supervision, but manually collecting sufficient data is simply too expensive. The key observation in this paper is that many mass-produced objects recur across multiple images of large unlabeled datasets, in different scenes, poses, and lighting conditions. We use this observation to create massive supervision by retrieving sets of diverse views of the same object. This powerful paired dataset enables us to train a straightforward text-to-image diffusion architecture to map the object and scene descriptions to the composited image. We compare our method, ObjectMate, with state-of-the-art methods for object insertion and subject-driven generation, using a single or multiple references. Empirically, ObjectMate achieves superior identity preservation and more photorealistic composition. Differently from many other multi-reference methods, ObjectMate does not require slow test-time tuning.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
SVNR: Spatially-variant Noise Removal with Denoising Diffusion
Jun 28, 2023Denoising diffusion models have recently shown impressive results in generative tasks. By learning powerful priors from huge collections of training images, such models are able to gradually modify complete noise to a clean natural image via a sequence of small denoising steps, seemingly making them well-suited for single image denoising. However, effectively applying denoising diffusion models to removal of realistic noise is more challenging than it may seem, since their formulation is based on additive white Gaussian noise, unlike noise in real-world images. In this work, we present SVNR, a novel formulation of denoising diffusion that assumes a more realistic, spatially-variant noise model. SVNR enables using the noisy input image as the starting point for the denoising diffusion process, in addition to conditioning the process on it. To this end, we adapt the diffusion process to allow each pixel to have its own time embedding, and propose training and inference schemes that support spatially-varying time maps. Our formulation also accounts for the correlation that exists between the condition image and the samples along the modified diffusion process. In our experiments we demonstrate the advantages of our approach over a strong diffusion model baseline, as well as over a state-of-the-art single image denoising method.
Underwater Single Image Color Restoration Using Haze-Lines and a New Quantitative Dataset
Nov 06, 2018

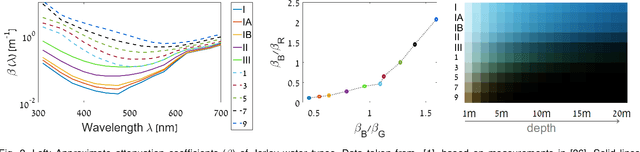
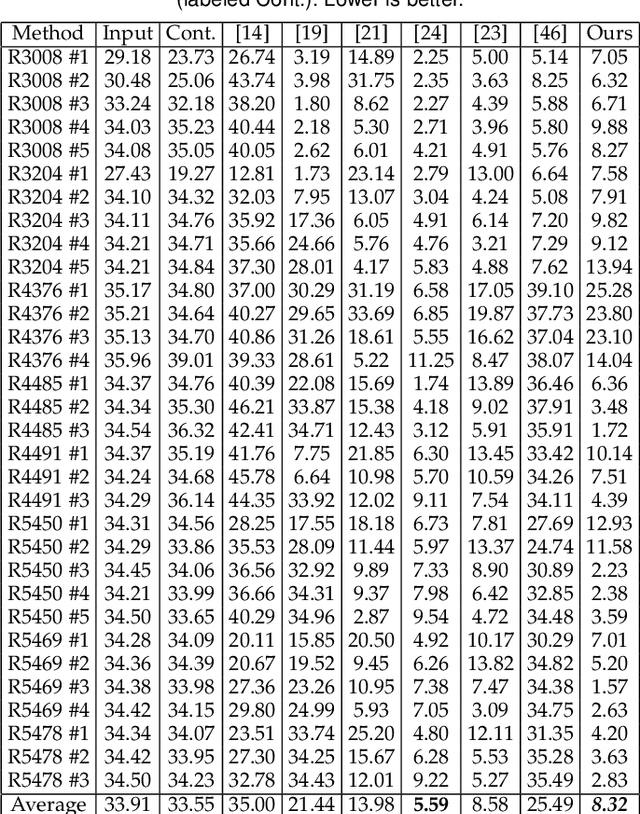
Underwater images suffer from color distortion and low contrast, because light is attenuated while it propagates through water. Attenuation under water varies with wavelength, unlike terrestrial images where attenuation is assumed to be spectrally uniform. The attenuation depends both on the water body and the 3D structure of the scene, making color restoration difficult. Unlike existing single underwater image enhancement techniques, our method takes into account multiple spectral profiles of different water types. By estimating just two additional global parameters: the attenuation ratios of the blue-red and blue-green color channels, the problem is reduced to single image dehazing, where all color channels have the same attenuation coefficients. Since the water type is unknown, we evaluate different parameters out of an existing library of water types. Each type leads to a different restored image and the best result is automatically chosen based on color distribution. We collected a dataset of images taken in different locations with varying water properties, showing color charts in the scenes. Moreover, to obtain ground truth, the 3D structure of the scene was calculated based on stereo imaging. This dataset enables a quantitative evaluation of restoration algorithms on natural images and shows the advantage of our method.