 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
SeeGULL Multilingual: a Dataset of Geo-Culturally Situated Stereotypes
Mar 08, 2024



While generative multilingual models are rapidly being deployed, their safety and fairness evaluations are largely limited to resources collected in English. This is especially problematic for evaluations targeting inherently socio-cultural phenomena such as stereotyping, where it is important to build multi-lingual resources that reflect the stereotypes prevalent in respective language communities. However, gathering these resources, at scale, in varied languages and regions pose a significant challenge as it requires broad socio-cultural knowledge and can also be prohibitively expensive. To overcome this critical gap, we employ a recently introduced approach that couples LLM generations for scale with culturally situated validations for reliability, and build SeeGULL Multilingual, a global-scale multilingual dataset of social stereotypes, containing over 25K stereotypes, spanning 20 languages, with human annotations across 23 regions, and demonstrate its utility in identifying gaps in model evaluations. Content warning: Stereotypes shared in this paper can be offensive.
Harm Amplification in Text-to-Image Models
Feb 01, 2024



Text-to-image (T2I) models have emerged as a significant advancement in generative AI; however, there exist safety concerns regarding their potential to produce harmful image outputs even when users input seemingly safe prompts. This phenomenon, where T2I models generate harmful representations that were not explicit in the input, poses a potentially greater risk than adversarial prompts, leaving users unintentionally exposed to harms. Our paper addresses this issue by first introducing a formal definition for this phenomenon, termed harm amplification. We further contribute to the field by developing methodologies to quantify harm amplification in which we consider the harm of the model output in the context of user input. We then empirically examine how to apply these different methodologies to simulate real-world deployment scenarios including a quantification of disparate impacts across genders resulting from harm amplification. Together, our work aims to offer researchers tools to comprehensively address safety challenges in T2I systems and contribute to the responsible deployment of generative AI models.
Sinkhorn-Flow: Predicting Probability Mass Flow in Dynamical Systems Using Optimal Transport
Mar 14, 2023



Predicting how distributions over discrete variables vary over time is a common task in time series forecasting. But whereas most approaches focus on merely predicting the distribution at subsequent time steps, a crucial piece of information in many settings is to determine how this probability mass flows between the different elements over time. We propose a new approach to predicting such mass flow over time using optimal transport. Specifically, we propose a generic approach to predicting transport matrices in end-to-end deep learning systems, replacing the standard softmax operation with Sinkhorn iterations. We apply our approach to the task of predicting how communities will evolve over time in social network settings, and show that the approach improves substantially over alternative prediction methods. We specifically highlight results on the task of predicting faction evolution in Ukrainian parliamentary voting.
WriterForcing: Generating more interesting story endings
Jul 18, 2019

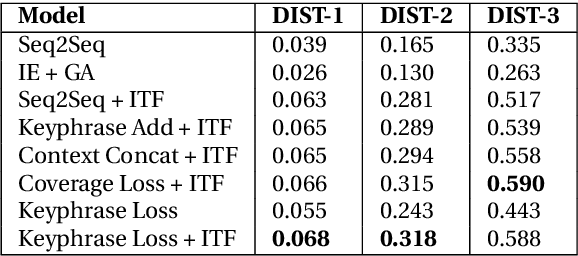
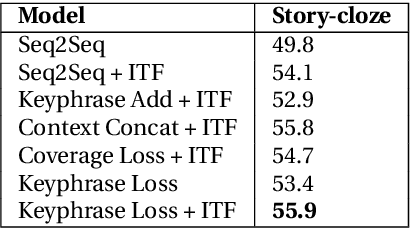
We study the problem of generating interesting endings for stories. Neural generative models have shown promising results for various text generation problems. Sequence to Sequence (Seq2Seq) models are typically trained to generate a single output sequence for a given input sequence. However, in the context of a story, multiple endings are possible. Seq2Seq models tend to ignore the context and generate generic and dull responses. Very few works have studied generating diverse and interesting story endings for a given story context. In this paper, we propose models which generate more diverse and interesting outputs by 1) training models to focus attention on important keyphrases of the story, and 2) promoting generation of non-generic words. We show that the combination of the two leads to more diverse and interesting endings.
Low-rank geometric mean metric learning
Jun 14, 2018
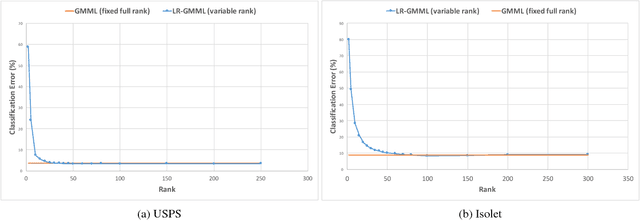
We propose a low-rank approach to learning a Mahalanobis metric from data. Inspired by the recent geometric mean metric learning (GMML) algorithm, we propose a low-rank variant of the algorithm. This allows to jointly learn a low-dimensional subspace where the data reside and the Mahalanobis metric that appropriately fits the data. Our results show that we compete effectively with GMML at lower ranks.
A two-dimensional decomposition approach for matrix completion through gossip
Jan 11, 2018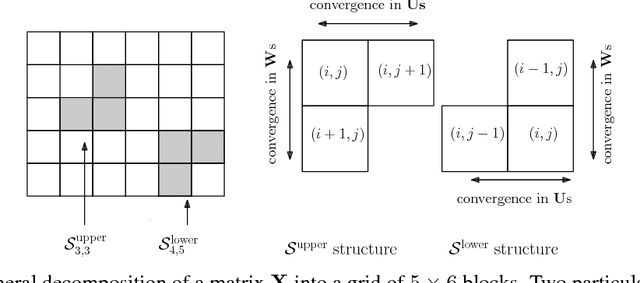


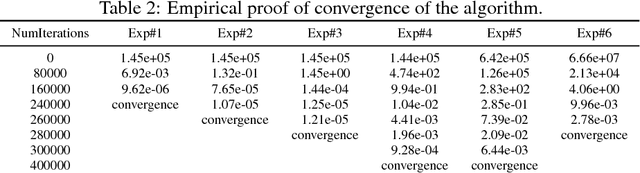
Factoring a matrix into two low rank matrices is at the heart of many problems. The problem of matrix completion especially uses it to decompose a sparse matrix into two non sparse, low rank matrices which can then be used to predict unknown entries of the original matrix. We present a scalable and decentralized approach in which instead of learning two factors for the original input matrix, we decompose the original matrix into a grid blocks, each of whose factors can be individually learned just by communicating (gossiping) with neighboring blocks. This eliminates any need for a central server. We show that our algorithm performs well on both synthetic and real datasets.
MRNet-Product2Vec: A Multi-task Recurrent Neural Network for Product Embeddings
Sep 21, 2017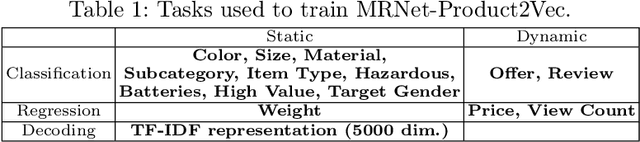
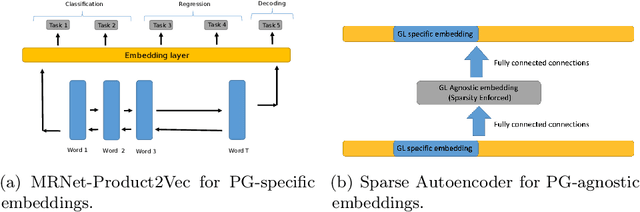

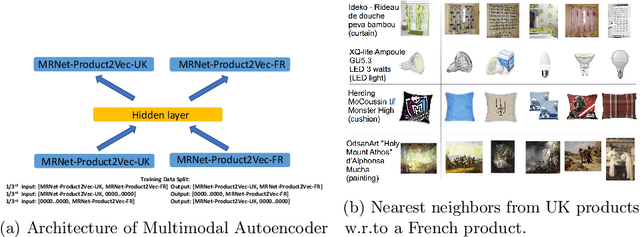
E-commerce websites such as Amazon, Alibaba, Flipkart, and Walmart sell billions of products. Machine learning (ML) algorithms involving products are often used to improve the customer experience and increase revenue, e.g., product similarity, recommendation, and price estimation. The products are required to be represented as features before training an ML algorithm. In this paper, we propose an approach called MRNet-Product2Vec for creating generic embeddings of products within an e-commerce ecosystem. We learn a dense and low-dimensional embedding where a diverse set of signals related to a product are explicitly injected into its representation. We train a Discriminative Multi-task Bidirectional Recurrent Neural Network (RNN), where the input is a product title fed through a Bidirectional RNN and at the output, product labels corresponding to fifteen different tasks are predicted. The task set includes several intrinsic characteristics about a product such as price, weight, size, color, popularity, and material. We evaluate the proposed embedding quantitatively and qualitatively. We demonstrate that they are almost as good as sparse and extremely high-dimensional TF-IDF representation in spite of having less than 3% of the TF-IDF dimension. We also use a multimodal autoencoder for comparing products from different language-regions and show preliminary yet promising qualitative results.