 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized infinite dimensional Alpha-Procrustes based geometries
Nov 12, 2025This work extends the recently introduced Alpha-Procrustes family of Riemannian metrics for symmetric positive definite (SPD) matrices by incorporating generalized versions of the Bures-Wasserstein (GBW), Log-Euclidean, and Wasserstein distances. While the Alpha-Procrustes framework has unified many classical metrics in both finite- and infinite- dimensional settings, it previously lacked the structural components necessary to realize these generalized forms. We introduce a formalism based on unitized Hilbert-Schmidt operators and an extended Mahalanobis norm that allows the construction of robust, infinite-dimensional generalizations of GBW and Log-Hilbert-Schmidt distances. Our approach also incorporates a learnable regularization parameter that enhances geometric stability in high-dimensional comparisons. Preliminary experiments reproducing benchmarks from the literature demonstrate the improved performance of our generalized metrics, particularly in scenarios involving comparisons between datasets of varying dimension and scale. This work lays a theoretical and computational foundation for advancing robust geometric methods in machine learning, statistical inference, and functional data analysis.
A Riemannian Approach to Ground Metric Learning for Optimal Transport
Sep 16, 2024
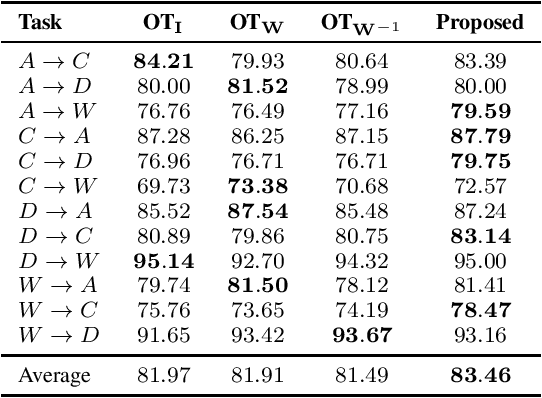
Optimal transport (OT) theory has attracted much attention in machine learning and signal processing applications. OT defines a notion of distance between probability distributions of source and target data points. A crucial factor that influences OT-based distances is the ground metric of the embedding space in which the source and target data points lie. In this work, we propose to learn a suitable latent ground metric parameterized by a symmetric positive definite matrix. We use the rich Riemannian geometry of symmetric positive definite matrices to jointly learn the OT distance along with the ground metric. Empirical results illustrate the efficacy of the learned metric in OT-based domain adaptation.
Riemannian Federated Learning via Averaging Gradient Stream
Sep 11, 2024In recent years, federated learning has garnered significant attention as an efficient and privacy-preserving distributed learning paradigm. In the Euclidean setting, Federated Averaging (FedAvg) and its variants are a class of efficient algorithms for expected (empirical) risk minimization. This paper develops and analyzes a Riemannian Federated Averaging Gradient Stream (RFedAGS) algorithm, which is a generalization of FedAvg, to problems defined on a Riemannian manifold. Under standard assumptions, the convergence rate of RFedAGS with fixed step sizes is proven to be sublinear for an approximate stationary solution. If decaying step sizes are used, the global convergence is established. Furthermore, assuming that the objective obeys the Riemannian Polyak-{\L}ojasiewicz property, the optimal gaps generated by RFedAGS with fixed step size are linearly decreasing up to a tiny upper bound, meanwhile, if decaying step sizes are used, then the gaps sublinearly vanish. Numerical simulations conducted on synthetic and real-world data demonstrate the performance of the proposed RFedAGS.
Submodular Framework for Structured-Sparse Optimal Transport
Jun 07, 2024Unbalanced optimal transport (UOT) has recently gained much attention due to its flexible framework for handling un-normalized measures and its robustness properties. In this work, we explore learning (structured) sparse transport plans in the UOT setting, i.e., transport plans have an upper bound on the number of non-sparse entries in each column (structured sparse pattern) or in the whole plan (general sparse pattern). We propose novel sparsity-constrained UOT formulations building on the recently explored maximum mean discrepancy based UOT. We show that the proposed optimization problem is equivalent to the maximization of a weakly submodular function over a uniform matroid or a partition matroid. We develop efficient gradient-based discrete greedy algorithms and provide the corresponding theoretical guarantees. Empirically, we observe that our proposed greedy algorithms select a diverse support set and we illustrate the efficacy of the proposed approach in various applications.
Riemannian coordinate descent algorithms on matrix manifolds
Jun 04, 2024Many machine learning applications are naturally formulated as optimization problems on Riemannian manifolds. The main idea behind Riemannian optimization is to maintain the feasibility of the variables while moving along a descent direction on the manifold. This results in updating all the variables at every iteration. In this work, we provide a general framework for developing computationally efficient coordinate descent (CD) algorithms on matrix manifolds that allows updating only a few variables at every iteration while adhering to the manifold constraint. In particular, we propose CD algorithms for various manifolds such as Stiefel, Grassmann, (generalized) hyperbolic, symplectic, and symmetric positive (semi)definite. While the cost per iteration of the proposed CD algorithms is low, we further develop a more efficient variant via a first-order approximation of the objective function. We analyze their convergence and complexity, and empirically illustrate their efficacy in several applications.
SLTrain: a sparse plus low-rank approach for parameter and memory efficient pretraining
Jun 04, 2024



Large language models (LLMs) have shown impressive capabilities across various tasks. However, training LLMs from scratch requires significant computational power and extensive memory capacity. Recent studies have explored low-rank structures on weights for efficient fine-tuning in terms of parameters and memory, either through low-rank adaptation or factorization. While effective for fine-tuning, low-rank structures are generally less suitable for pretraining because they restrict parameters to a low-dimensional subspace. In this work, we propose to parameterize the weights as a sum of low-rank and sparse matrices for pretraining, which we call SLTrain. The low-rank component is learned via matrix factorization, while for the sparse component, we employ a simple strategy of uniformly selecting the sparsity support at random and learning only the non-zero entries with the fixed support. While being simple, the random fixed-support sparse learning strategy significantly enhances pretraining when combined with low-rank learning. Our results show that SLTrain adds minimal extra parameters and memory costs compared to pretraining with low-rank parameterization, yet achieves substantially better performance, which is comparable to full-rank training. Remarkably, when combined with quantization and per-layer updates, SLTrain can reduce memory requirements by up to 73% when pretraining the LLaMA 7B model.
A Gauss-Newton Approach for Min-Max Optimization in Generative Adversarial Networks
Apr 10, 2024A novel first-order method is proposed for training generative adversarial networks (GANs). It modifies the Gauss-Newton method to approximate the min-max Hessian and uses the Sherman-Morrison inversion formula to calculate the inverse. The method corresponds to a fixed-point method that ensures necessary contraction. To evaluate its effectiveness, numerical experiments are conducted on various datasets commonly used in image generation tasks, such as MNIST, Fashion MNIST, CIFAR10, FFHQ, and LSUN. Our method is capable of generating high-fidelity images with greater diversity across multiple datasets. It also achieves the highest inception score for CIFAR10 among all compared methods, including state-of-the-art second-order methods. Additionally, its execution time is comparable to that of first-order min-max methods.
A Framework for Bilevel Optimization on Riemannian Manifolds
Feb 06, 2024



Bilevel optimization has seen an increasing presence in various domains of applications. In this work, we propose a framework for solving bilevel optimization problems where variables of both lower and upper level problems are constrained on Riemannian manifolds. We provide several hypergradient estimation strategies on manifolds and study their estimation error. We provide convergence and complexity analysis for the proposed hypergradient descent algorithm on manifolds. We also extend the developments to stochastic bilevel optimization and to the use of general retraction. We showcase the utility of the proposed framework on various applications.
Light-weight Deep Extreme Multilabel Classification
Apr 20, 2023



Extreme multi-label (XML) classification refers to the task of supervised multi-label learning that involves a large number of labels. Hence, scalability of the classifier with increasing label dimension is an important consideration. In this paper, we develop a method called LightDXML which modifies the recently developed deep learning based XML framework by using label embeddings instead of feature embedding for negative sampling and iterating cyclically through three major phases: (1) proxy training of label embeddings (2) shortlisting of labels for negative sampling and (3) final classifier training using the negative samples. Consequently, LightDXML also removes the requirement of a re-ranker module, thereby, leading to further savings on time and memory requirements. The proposed method achieves the best of both worlds: while the training time, model size and prediction times are on par or better compared to the tree-based methods, it attains much better prediction accuracy that is on par with the deep learning based methods. Moreover, the proposed approach achieves the best tail-label prediction accuracy over most state-of-the-art XML methods on some of the large datasets\footnote{accepted in IJCNN 2023, partial funding from MAPG grant and IIIT Seed grant at IIIT, Hyderabad, India. Code: \url{https://github.com/misterpawan/LightDXML}
Generalised Spherical Text Embedding
Nov 30, 2022This paper aims to provide an unsupervised modelling approach that allows for a more flexible representation of text embeddings. It jointly encodes the words and the paragraphs as individual matrices of arbitrary column dimension with unit Frobenius norm. The representation is also linguistically motivated with the introduction of a novel similarity metric. The proposed modelling and the novel similarity metric exploits the matrix structure of embeddings. We then go on to show that the same matrices can be reshaped into vectors of unit norm and transform our problem into an optimization problem over the spherical manifold. We exploit manifold optimization to efficiently train the matrix embeddings. We also quantitatively verify the quality of our text embeddings by showing that they demonstrate improved results in document classification, document clustering, and semantic textual similarity benchmark tests.