 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Science of AI Agent Reliability
Feb 18, 2026AI agents are increasingly deployed to execute important tasks. While rising accuracy scores on standard benchmarks suggest rapid progress, many agents still continue to fail in practice. This discrepancy highlights a fundamental limitation of current evaluations: compressing agent behavior into a single success metric obscures critical operational flaws. Notably, it ignores whether agents behave consistently across runs, withstand perturbations, fail predictably, or have bounded error severity. Grounded in safety-critical engineering, we provide a holistic performance profile by proposing twelve concrete metrics that decompose agent reliability along four key dimensions: consistency, robustness, predictability, and safety. Evaluating 14 agentic models across two complementary benchmarks, we find that recent capability gains have only yielded small improvements in reliability. By exposing these persistent limitations, our metrics complement traditional evaluations while offering tools for reasoning about how agents perform, degrade, and fail.
RWKV-7 "Goose" with Expressive Dynamic State Evolution
Mar 18, 2025We present RWKV-7 "Goose", a new sequence modeling architecture, along with pre-trained language models that establish a new state-of-the-art in downstream performance at the 3 billion parameter scale on multilingual tasks, and match current SoTA English language performance despite being trained on dramatically fewer tokens than other top 3B models. Nevertheless, RWKV-7 models require only constant memory usage and constant inference time per token. RWKV-7 introduces a newly generalized formulation of the delta rule with vector-valued gating and in-context learning rates, as well as a relaxed value replacement rule. We show that RWKV-7 can perform state tracking and recognize all regular languages, while retaining parallelizability of training. This exceeds the capabilities of Transformers under standard complexity conjectures, which are limited to $\mathsf{TC}^0$. To demonstrate RWKV-7's language modeling capability, we also present an extended open source 3.1 trillion token multilingual corpus, and train four RWKV-7 models ranging from 0.19 billion to 2.9 billion parameters on this dataset. To foster openness, reproduction, and adoption, we release our models and dataset component listing at https://huggingface.co/RWKV, and our training and inference code at https://github.com/RWKV/RWKV-LM all under the Apache 2.0 License.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
MASAI: Modular Architecture for Software-engineering AI Agents
Jun 17, 2024A common method to solve complex problems in software engineering, is to divide the problem into multiple sub-problems. Inspired by this, we propose a Modular Architecture for Software-engineering AI (MASAI) agents, where different LLM-powered sub-agents are instantiated with well-defined objectives and strategies tuned to achieve those objectives. Our modular architecture offers several advantages: (1) employing and tuning different problem-solving strategies across sub-agents, (2) enabling sub-agents to gather information from different sources scattered throughout a repository, and (3) avoiding unnecessarily long trajectories which inflate costs and add extraneous context. MASAI enabled us to achieve the highest performance (28.33% resolution rate) on the popular and highly challenging SWE-bench Lite dataset consisting of 300 GitHub issues from 11 Python repositories. We conduct a comprehensive evaluation of MASAI relative to other agentic methods and analyze the effects of our design decisions and their contribution to the success of MASAI.
Language Agnostic Code Embeddings
Oct 25, 2023Recently, code language models have achieved notable advancements in addressing a diverse array of essential code comprehension and generation tasks. Yet, the field lacks a comprehensive deep dive and understanding of the code embeddings of multilingual code models. In this paper, we present a comprehensive study on multilingual code embeddings, focusing on the cross-lingual capabilities of these embeddings across different programming languages. Through probing experiments, we demonstrate that code embeddings comprise two distinct components: one deeply tied to the nuances and syntax of a specific language, and the other remaining agnostic to these details, primarily focusing on semantics. Further, we show that when we isolate and eliminate this language-specific component, we witness significant improvements in downstream code retrieval tasks, leading to an absolute increase of up to +17 in the Mean Reciprocal Rank (MRR).
Locally Differentially Private Document Generation Using Zero Shot Prompting
Oct 24, 2023



Numerous studies have highlighted the privacy risks associated with pretrained large language models. In contrast, our research offers a unique perspective by demonstrating that pretrained large language models can effectively contribute to privacy preservation. We propose a locally differentially private mechanism called DP-Prompt, which leverages the power of pretrained large language models and zero-shot prompting to counter author de-anonymization attacks while minimizing the impact on downstream utility. When DP-Prompt is used with a powerful language model like ChatGPT (gpt-3.5), we observe a notable reduction in the success rate of de-anonymization attacks, showing that it surpasses existing approaches by a considerable margin despite its simpler design. For instance, in the case of the IMDB dataset, DP-Prompt (with ChatGPT) perfectly recovers the clean sentiment F1 score while achieving a 46\% reduction in author identification F1 score against static attackers and a 26\% reduction against adaptive attackers. We conduct extensive experiments across six open-source large language models, ranging up to 7 billion parameters, to analyze various effects of the privacy-utility tradeoff.
Rieoptax: Riemannian Optimization in JAX
Oct 10, 2022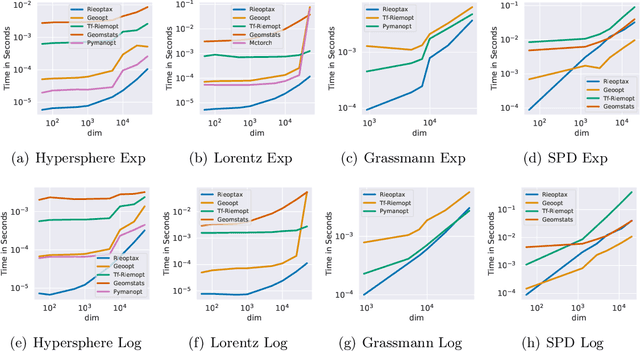

We present Rieoptax, an open source Python library for Riemannian optimization in JAX. We show that many differential geometric primitives, such as Riemannian exponential and logarithm maps, are usually faster in Rieoptax than existing frameworks in Python, both on CPU and GPU. We support various range of basic and advanced stochastic optimization solvers like Riemannian stochastic gradient, stochastic variance reduction, and adaptive gradient methods. A distinguishing feature of the proposed toolbox is that we also support differentially private optimization on Riemannian manifolds.
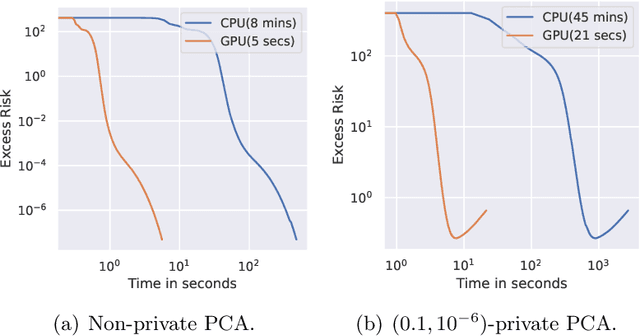
Differentially Private Fréchet Mean on the Manifold of Symmetric Positive Definite (SPD) Matrices
Aug 08, 2022
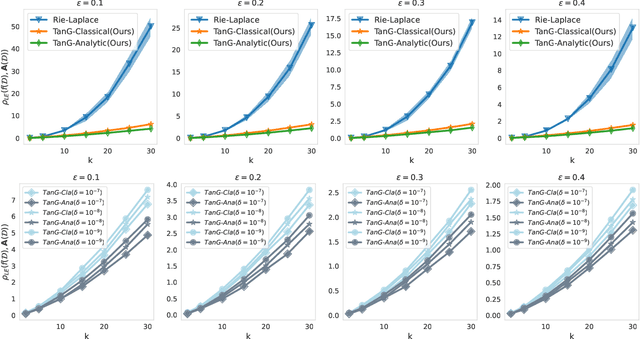
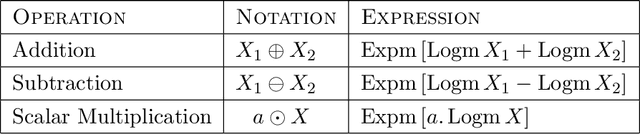
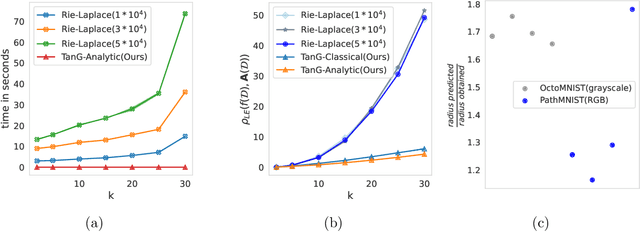
Differential privacy has become crucial in the real-world deployment of statistical and machine learning algorithms with rigorous privacy guarantees. The earliest statistical queries, for which differential privacy mechanisms have been developed, were for the release of the sample mean. In Geometric Statistics, the sample Fr\'echet mean represents one of the most fundamental statistical summaries, as it generalizes the sample mean for data belonging to nonlinear manifolds. In that spirit, the only geometric statistical query for which a differential privacy mechanism has been developed, so far, is for the release of the sample Fr\'echet mean: the \emph{Riemannian Laplace mechanism} was recently proposed to privatize the Fr\'echet mean on complete Riemannian manifolds. In many fields, the manifold of Symmetric Positive Definite (SPD) matrices is used to model data spaces, including in medical imaging where privacy requirements are key. We propose a novel, simple and fast mechanism - the \emph{Tangent Gaussian mechanism} - to compute a differentially private Fr\'echet mean on the SPD manifold endowed with the log-Euclidean Riemannian metric. We show that our new mechanism obtains quadratic utility improvement in terms of data dimension over the current and only available baseline. Our mechanism is also simpler in practice as it does not require any expensive Markov Chain Monte Carlo (MCMC) sampling, and is computationally faster by multiple orders of magnitude -- as confirmed by extensive experiments.
Shrinkage Estimation of Higher Order Bochner Integrals
Jul 21, 2022We consider shrinkage estimation of higher order Hilbert space valued Bochner integrals in a non-parametric setting. We propose estimators that shrink the $U$-statistic estimator of the Bochner integral towards a pre-specified target element in the Hilbert space. Depending on the degeneracy of the kernel of the $U$-statistic, we construct consistent shrinkage estimators with fast rates of convergence, and develop oracle inequalities comparing the risks of the the $U$-statistic estimator and its shrinkage version. Surprisingly, we show that the shrinkage estimator designed by assuming complete degeneracy of the kernel of the $U$-statistic is a consistent estimator even when the kernel is not complete degenerate. This work subsumes and improves upon Krikamol et al., 2016, JMLR and Zhou et al., 2019, JMVA, which only handle mean element and covariance operator estimation in a reproducing kernel Hilbert space. We also specialize our results to normal mean estimation and show that for $d\ge 3$, the proposed estimator strictly improves upon the sample mean in terms of the mean squared error.